diff --git a/.github/workflows/stale.yml b/.github/workflows/stale.yml
new file mode 100644
index 000000000..acd1ae53a
--- /dev/null
+++ b/.github/workflows/stale.yml
@@ -0,0 +1,68 @@
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This workflow handles closing stale issues and PRs.
+name: Stale
+on:
+ # Allows running this workflow manually from the Actions tab
+ workflow_dispatch:
+
+ # Runs at 02:00
+ schedule:
+ - cron: "0 2 * * *"
+
+env:
+ CLOSE_ISSUE_MESSAGE: >
+ This issue was closed because it has been stalled for 14 days with no activity.
+ Feel free to reopen if is still relevant, or to ping a collaborator if you have any questions.
+ CLOSE_PR_MESSAGE: >
+ This PR was closed because it has been stalled for 14 days with no activity.
+ Feel free to reopen if is still relevant, or to ping a collaborator if you have any questions.
+ WARN_ISSUE_MESSAGE: >
+ This issue has been automatically marked as stale because it has not had
+ recent activity (1 year). It will be closed if no further activity occurs.
+ Thank you for your contributions.
+ WARN_PR_MESSAGE: >
+ This PR has been automatically marked as stale because it has not had
+ recent activity (1 year). It will be closed if no further activity occurs.
+ Thank you for your contributions.
+
+jobs:
+ # This job runs the actions/stale action to close stale issues and PRs.
+ stale:
+ name: Close Stale Issues and PRs
+ runs-on: ubuntu-latest
+ permissions:
+ actions: write
+ contents: write # only for delete-branch option
+ issues: write
+ pull-requests: write
+ steps:
+ - uses: actions/stale@v10
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+ stale-issue-label: stale
+ stale-pr-label: stale
+ exempt-issue-labels: never-stale
+ exempt-pr-labels: never-stale
+ days-before-issue-stale: 180 # TODO(Steven): Will modify this to 90 after initial cleanup
+ days-before-issue-close: 14
+ days-before-pr-stale: 180
+ days-before-pr-close: 14
+ delete-branch: true
+ close-issue-message: ${{ env.CLOSE_ISSUE_MESSAGE }}
+ close-pr-message: ${{ env.CLOSE_PR_MESSAGE }}
+ stale-issue-message: ${{ env.WARN_ISSUE_MESSAGE }}
+ stale-pr-message: ${{ env.WARN_PR_MESSAGE }}
+ operations-per-run: 500
diff --git a/README.md b/README.md
index 9fd45a7b7..a3f28f552 100644
--- a/README.md
+++ b/README.md
@@ -227,13 +227,13 @@ Our script can also visualize datasets stored on a distant server. See `python -
A dataset in `LeRobotDataset` format is very simple to use. It can be loaded from a repository on the Hugging Face hub or a local folder simply with e.g. `dataset = LeRobotDataset("lerobot/aloha_static_coffee")` and can be indexed into like any Hugging Face and PyTorch dataset. For instance `dataset[0]` will retrieve a single temporal frame from the dataset containing observation(s) and an action as PyTorch tensors ready to be fed to a model.
-A specificity of `LeRobotDataset` is that, rather than retrieving a single frame by its index, we can retrieve several frames based on their temporal relationship with the indexed frame, by setting `delta_timestamps` to a list of relative times with respect to the indexed frame. For example, with `delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]}` one can retrieve, for a given index, 4 frames: 3 "previous" frames 1 second, 0.5 seconds, and 0.2 seconds before the indexed frame, and the indexed frame itself (corresponding to the 0 entry). See example [1_load_lerobot_dataset.py](https://github.com/huggingface/lerobot/blob/main/examples/1_load_lerobot_dataset.py) for more details on `delta_timestamps`.
+A specificity of `LeRobotDataset` is that, rather than retrieving a single frame by its index, we can retrieve several frames based on their temporal relationship with the indexed frame, by setting `delta_timestamps` to a list of relative times with respect to the indexed frame. For example, with `delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]}` one can retrieve, for a given index, 4 frames: 3 "previous" frames 1 second, 0.5 seconds, and 0.2 seconds before the indexed frame, and the indexed frame itself (corresponding to the 0 entry). See example [1_load_lerobot_dataset.py](https://github.com/huggingface/lerobot/blob/main/examples/dataset/load_lerobot_dataset.py) for more details on `delta_timestamps`.
Under the hood, the `LeRobotDataset` format makes use of several ways to serialize data which can be useful to understand if you plan to work more closely with this format. We tried to make a flexible yet simple dataset format that would cover most type of features and specificities present in reinforcement learning and robotics, in simulation and in real-world, with a focus on cameras and robot states but easily extended to other types of sensory inputs as long as they can be represented by a tensor.
Here are the important details and internal structure organization of a typical `LeRobotDataset` instantiated with `dataset = LeRobotDataset("lerobot/aloha_static_coffee")`. The exact features will change from dataset to dataset but not the main aspects:
-````
+```
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
@@ -269,7 +269,7 @@ dataset attributes:
├ root (Path): local directory where the dataset is stored
├ image_transforms (Callable): optional image transformations to apply to visual modalities
└ delta_timestamps (dict): optional delta timestamps for temporal queries
-decoding videos (e.g., 'pyav', 'torchcodec')
+```
A `LeRobotDataset` is serialised using several widespread file formats for each of its parts, namely:
@@ -279,42 +279,6 @@ A `LeRobotDataset` is serialised using several widespread file formats for each
Dataset can be uploaded/downloaded from the HuggingFace hub seamlessly. To work on a local dataset, you can specify its location with the `root` argument if it's not in the default `~/.cache/huggingface/lerobot` location.
-### Evaluate a pretrained policy
-
-Check out [example 2](https://github.com/huggingface/lerobot/blob/main/examples/2_evaluate_pretrained_policy.py) that illustrates how to download a pretrained policy from Hugging Face hub, and run an evaluation on its corresponding environment.
-
-We also provide a more capable script to parallelize the evaluation over multiple environments during the same rollout. Here is an example with a pretrained model hosted on [lerobot/diffusion_pusht](https://huggingface.co/lerobot/diffusion_pusht):
-
-```bash
-lerobot-eval \
- --policy.path=lerobot/diffusion_pusht \
- --env.type=pusht \
- --eval.batch_size=10 \
- --eval.n_episodes=10 \
- --policy.use_amp=false \
- --policy.device=cuda
-````
-
-Note: After training your own policy, you can re-evaluate the checkpoints with:
-
-```bash
-lerobot-eval --policy.path={OUTPUT_DIR}/checkpoints/last/pretrained_model
-```
-
-See `lerobot-eval --help` for more instructions.
-
-### Train your own policy
-
-Check out [example 3](https://github.com/huggingface/lerobot/blob/main/examples/3_train_policy.py) that illustrates how to train a model using our core library in python, and [example 4](https://github.com/huggingface/lerobot/blob/main/examples/4_train_policy_with_script.md) that shows how to use our training script from command line.
-
-To use wandb for logging training and evaluation curves, make sure you've run `wandb login` as a one-time setup step. Then, when running the training command above, enable WandB in the configuration by adding `--wandb.enable=true`.
-
-A link to the wandb logs for the run will also show up in yellow in your terminal. Here is an example of what they look like in your browser. Please also check [here](https://github.com/huggingface/lerobot/blob/main/examples/4_train_policy_with_script.md#typical-logs-and-metrics) for the explanation of some commonly used metrics in logs.
-
-\ -
-Note: For efficiency, during training every checkpoint is evaluated on a low number of episodes. You may use `--eval.n_episodes=500` to evaluate on more episodes than the default. Or, after training, you may want to re-evaluate your best checkpoints on more episodes or change the evaluation settings. See `lerobot-eval --help` for more instructions.
-
#### Reproduce state-of-the-art (SOTA)
We provide some pretrained policies on our [hub page](https://huggingface.co/lerobot) that can achieve state-of-the-art performances.
@@ -373,3 +337,7 @@ If you want, you can cite this work with:
## Star History
[](https://star-history.com/#huggingface/lerobot&Timeline)
+
+```
+
+```
diff --git a/docker/Dockerfile.internal b/docker/Dockerfile.internal
index 8c77fe497..52becb830 100644
--- a/docker/Dockerfile.internal
+++ b/docker/Dockerfile.internal
@@ -39,6 +39,7 @@ RUN apt-get update && apt-get install -y --no-install-recommends \
software-properties-common build-essential git curl \
libglib2.0-0 libgl1-mesa-glx libegl1-mesa ffmpeg \
libusb-1.0-0-dev speech-dispatcher libgeos-dev portaudio19-dev \
+ cmake pkg-config ninja-build \
&& add-apt-repository -y ppa:deadsnakes/ppa \
&& apt-get update \
&& apt-get install -y --no-install-recommends \
diff --git a/docker/Dockerfile.user b/docker/Dockerfile.user
index bcd067637..59fd3e0b3 100644
--- a/docker/Dockerfile.user
+++ b/docker/Dockerfile.user
@@ -31,6 +31,7 @@ ENV DEBIAN_FRONTEND=noninteractive \
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential git curl libglib2.0-0 libegl1-mesa-dev ffmpeg \
libusb-1.0-0-dev speech-dispatcher libgeos-dev portaudio19-dev \
+ cmake pkg-config ninja-build \
&& curl -LsSf https://astral.sh/uv/install.sh | sh \
&& mv /root/.local/bin/uv /usr/local/bin/uv \
&& useradd --create-home --shell /bin/bash user_lerobot \
diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index 620a03075..36eaea165 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -33,8 +33,9 @@
title: π₀ (Pi0)
- local: pi05
title: π₀.₅ (Pi05)
+ - local: libero
+ title: Using Libero
title: "Policies"
-
- sections:
- local: introduction_processors
title: Introduction to Robot Processors
diff --git a/docs/source/lerobot-dataset-v3.mdx b/docs/source/lerobot-dataset-v3.mdx
index 4f33d9a25..09fb17fad 100644
--- a/docs/source/lerobot-dataset-v3.mdx
+++ b/docs/source/lerobot-dataset-v3.mdx
@@ -8,6 +8,7 @@ This docs will guide you to:
- Record a dataset and push it to the Hub
- Load datasets for training with `LeRobotDataset`
- Stream datasets without downloading using `StreamingLeRobotDataset`
+- Apply image transforms for data augmentation during training
- Migrate existing `v2.1` datasets to `v3.0`
## What’s new in `v3`
@@ -150,6 +151,117 @@ dataset = StreamingLeRobotDataset(repo_id) # streams directly from the Hub
+## Image transforms
+
+Image transforms are data augmentations applied to camera frames during training to improve model robustness and generalization. LeRobot supports various transforms including brightness, contrast, saturation, hue, and sharpness adjustments.
+
+### Using transforms during dataset creation/recording
+
+Currently, transforms are applied during **training time only**, not during recording. When you create or record a dataset, the raw images are stored without transforms. This allows you to experiment with different augmentations later without re-recording data.
+
+### Adding transforms to existing datasets (API)
+
+Use the `image_transforms` parameter when loading a dataset for training:
+
+```python
+from lerobot.datasets.lerobot_dataset import LeRobotDataset
+from lerobot.datasets.transforms import ImageTransforms, ImageTransformsConfig, ImageTransformConfig
+
+# Option 1: Use default transform configuration (disabled by default)
+transforms_config = ImageTransformsConfig(
+ enable=True, # Enable transforms
+ max_num_transforms=3, # Apply up to 3 transforms per frame
+ random_order=False, # Apply in standard order
+)
+transforms = ImageTransforms(transforms_config)
+
+dataset = LeRobotDataset(
+ repo_id="your-username/your-dataset",
+ image_transforms=transforms
+)
+
+# Option 2: Create custom transform configuration
+custom_transforms_config = ImageTransformsConfig(
+ enable=True,
+ max_num_transforms=2,
+ random_order=True,
+ tfs={
+ "brightness": ImageTransformConfig(
+ weight=1.0,
+ type="ColorJitter",
+ kwargs={"brightness": (0.7, 1.3)} # Adjust brightness range
+ ),
+ "contrast": ImageTransformConfig(
+ weight=2.0, # Higher weight = more likely to be selected
+ type="ColorJitter",
+ kwargs={"contrast": (0.8, 1.2)}
+ ),
+ "sharpness": ImageTransformConfig(
+ weight=0.5, # Lower weight = less likely to be selected
+ type="SharpnessJitter",
+ kwargs={"sharpness": (0.3, 2.0)}
+ ),
+ }
+)
+
+dataset = LeRobotDataset(
+ repo_id="your-username/your-dataset",
+ image_transforms=ImageTransforms(custom_transforms_config)
+)
+
+# Option 3: Use pure torchvision transforms
+from torchvision.transforms import v2
+
+torchvision_transforms = v2.Compose([
+ v2.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
+ v2.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
+])
+
+dataset = LeRobotDataset(
+ repo_id="your-username/your-dataset",
+ image_transforms=torchvision_transforms
+)
+```
+
+### Available transform types
+
+LeRobot provides several transform types:
+
+- **`ColorJitter`**: Adjusts brightness, contrast, saturation, and hue
+- **`SharpnessJitter`**: Randomly adjusts image sharpness
+- **`Identity`**: No transformation (useful for testing)
+
+You can also use any `torchvision.transforms.v2` transform by passing it directly to the `image_transforms` parameter.
+
+### Configuration options
+
+- **`enable`**: Enable/disable transforms (default: `False`)
+- **`max_num_transforms`**: Maximum number of transforms applied per frame (default: `3`)
+- **`random_order`**: Apply transforms in random order vs. standard order (default: `False`)
+- **`weight`**: Sampling probability for each transform (higher = more likely, if sum of weights is not 1, they will be normalized)
+- **`kwargs`**: Transform-specific parameters (e.g., brightness range)
+
+### Visualizing transforms
+
+Use the visualization script to preview how transforms affect your data:
+
+```bash
+python -m lerobot.scripts.visualize_image_transforms \
+ --repo-id=your-username/your-dataset \
+ --output-dir=./transform_examples \
+ --n-examples=5
+```
+
+This saves example images showing the effect of each transform, helping you tune parameters.
+
+### Best practices
+
+- **Start conservative**: Begin with small ranges (e.g., brightness 0.9-1.1) and increase gradually
+- **Test first**: Use the visualization script to ensure transforms look reasonable
+- **Monitor training**: Strong augmentations can hurt performance if too aggressive
+- **Match your domain**: If your robot operates in varying lighting, use brightness/contrast transforms
+- **Combine wisely**: Using too many transforms simultaneously can make training unstable
+
## Migrate `v2.1` → `v3.0`
A converter aggregates per‑episode files into larger shards and writes episode offsets/metadata. Convert your dataset using the instructions below.
diff --git a/docs/source/libero.mdx b/docs/source/libero.mdx
new file mode 100644
index 000000000..488c02ce0
--- /dev/null
+++ b/docs/source/libero.mdx
@@ -0,0 +1,126 @@
+# LIBERO
+
+**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers.
+
+- 📄 [LIBERO paper](https://arxiv.org/abs/2306.03310)
+- 💻 [Original LIBERO repo](https://github.com/Lifelong-Robot-Learning/LIBERO)
+
+To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
+
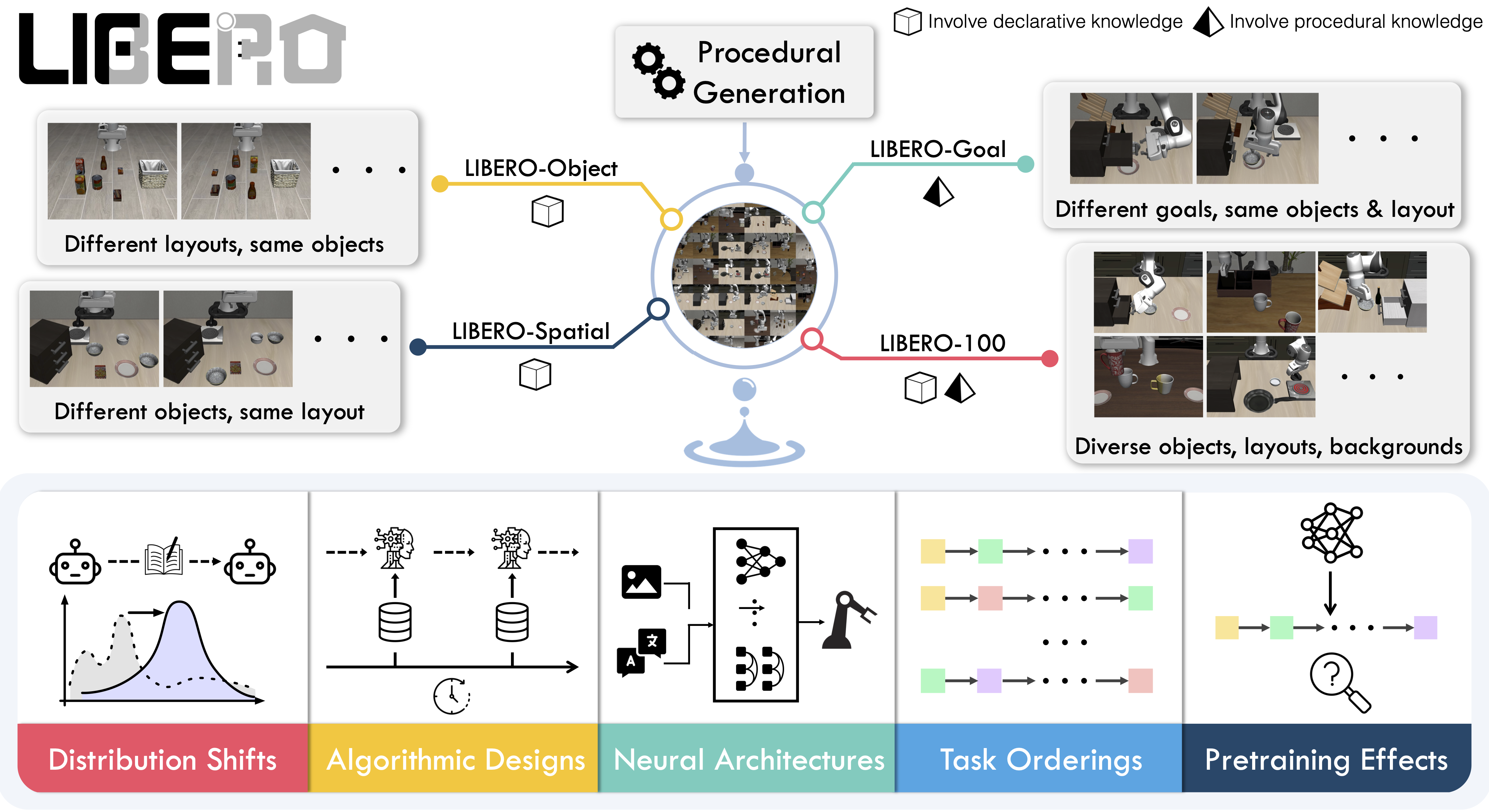
+LIBERO includes **five task suites**:
+
+- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
+- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
+- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
+- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
+- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
+
+Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
+
+
+
+## Evaluating with LIBERO
+
+At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it mainly to **evaluate [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model.
+
+LIBERO is now part of our **multi-eval supported simulation**, meaning you can benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a flag.
+
+To Install LIBERO, after following LeRobot official instructions, just do:
+`pip install -e ".[libero]"`
+
+### Single-suite evaluation
+
+Evaluate a policy on one LIBERO suite:
+
+```bash
+python src/lerobot/scripts/eval.py \
+ --policy.path="your-policy-id" \
+ --env.type=libero \
+ --env.task=libero_object \
+ --eval.batch_size=2 \
+ --eval.n_episodes=3
+```
+
+- `--env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
+- `--eval.batch_size` controls how many environments run in parallel.
+- `--eval.n_episodes` sets how many episodes to run in total.
+
+---
+
+### Multi-suite evaluation
+
+Benchmark a policy across multiple suites at once:
+
+```bash
+python src/lerobot/scripts/eval.py \
+ --policy.path="your-policy-id" \
+ --env.type=libero \
+ --env.task=libero_object,libero_spatial \
+ --eval.batch_size=1 \
+ --eval.n_episodes=2
+```
+
+- Pass a comma-separated list to `--env.task` for multi-suite evaluation.
+
+### Policy inputs and outputs
+
+When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
+
+- **Observations**
+ - `observation.state` – proprioceptive features (agent state).
+ - `observation.images.image` – main camera view (`agentview_image`).
+ - `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
+
+ ⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any multi-modal visual features. Always ensure that your policy config `input_features` use the same naming keys, and that your dataset metadata keys follow this convention during evaluation.
+ If your data contains different keys, you must rename the observations to match what the policy expects, since naming keys are encoded inside the normalization statistics layer.
+ This will be fixed with the upcoming Pipeline PR.
+
+- **Actions**
+ - Continuous control values in a `Box(-1, 1, shape=(7,))` space.
+
+We also provide a notebook for quick testing:
+Training with LIBERO
+
+## Training with LIBERO
+
+When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
+
+The environment expects:
+
+- `observation.state` → 8-dim agent state
+- `observation.images.image` → main camera (`agentview_image`)
+- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
+
+⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code.
+To avoid potential mismatches and key errors, we provide a **preprocessed LIBERO dataset** that is fully compatible with the current LeRobot codebase and requires no additional manipulation:
+👉 [HuggingFaceVLA/libero](https://huggingface.co/datasets/HuggingFaceVLA/libero)
+
+For reference, here is the **original dataset** published by Physical Intelligence:
+👉 [physical-intelligence/libero](https://huggingface.co/datasets/physical-intelligence/libero)
+
+---
+
+### Example training command
+
+```bash
+python src/lerobot/scripts/train.py \
+ --policy.type=smolvla \
+ --policy.repo_id=${HF_USER}/libero-test \
+ --dataset.repo_id=jadechoghari/smol-libero3 \
+ --env.type=libero \
+ --env.task=libero_10 \
+ --output_dir=./outputs/ \
+ --steps=100000 \
+ --batch_size=4 \
+ --eval.batch_size=1 \
+ --eval.n_episodes=1 \
+ --eval_freq=1000 \
+```
+
+---
+
+### Note on rendering
+
+LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
+
+- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
diff --git a/docs/source/phone_teleop.mdx b/docs/source/phone_teleop.mdx
index 71d5457fb..bab0ac28e 100644
--- a/docs/source/phone_teleop.mdx
+++ b/docs/source/phone_teleop.mdx
@@ -36,7 +36,7 @@ Links:
- iOS: Analog input `A3` controls the gripper as velocity input.
- Android: Buttons `A` and `B` act like increment/decrement (A opens, B closes). You can tune velocity in the `GripperVelocityToJoint` step.
-
-
-Note: For efficiency, during training every checkpoint is evaluated on a low number of episodes. You may use `--eval.n_episodes=500` to evaluate on more episodes than the default. Or, after training, you may want to re-evaluate your best checkpoints on more episodes or change the evaluation settings. See `lerobot-eval --help` for more instructions.
-
#### Reproduce state-of-the-art (SOTA)
We provide some pretrained policies on our [hub page](https://huggingface.co/lerobot) that can achieve state-of-the-art performances.
@@ -373,3 +337,7 @@ If you want, you can cite this work with:
## Star History
[](https://star-history.com/#huggingface/lerobot&Timeline)
+
+```
+
+```
diff --git a/docker/Dockerfile.internal b/docker/Dockerfile.internal
index 8c77fe497..52becb830 100644
--- a/docker/Dockerfile.internal
+++ b/docker/Dockerfile.internal
@@ -39,6 +39,7 @@ RUN apt-get update && apt-get install -y --no-install-recommends \
software-properties-common build-essential git curl \
libglib2.0-0 libgl1-mesa-glx libegl1-mesa ffmpeg \
libusb-1.0-0-dev speech-dispatcher libgeos-dev portaudio19-dev \
+ cmake pkg-config ninja-build \
&& add-apt-repository -y ppa:deadsnakes/ppa \
&& apt-get update \
&& apt-get install -y --no-install-recommends \
diff --git a/docker/Dockerfile.user b/docker/Dockerfile.user
index bcd067637..59fd3e0b3 100644
--- a/docker/Dockerfile.user
+++ b/docker/Dockerfile.user
@@ -31,6 +31,7 @@ ENV DEBIAN_FRONTEND=noninteractive \
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential git curl libglib2.0-0 libegl1-mesa-dev ffmpeg \
libusb-1.0-0-dev speech-dispatcher libgeos-dev portaudio19-dev \
+ cmake pkg-config ninja-build \
&& curl -LsSf https://astral.sh/uv/install.sh | sh \
&& mv /root/.local/bin/uv /usr/local/bin/uv \
&& useradd --create-home --shell /bin/bash user_lerobot \
diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index 620a03075..36eaea165 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -33,8 +33,9 @@
title: π₀ (Pi0)
- local: pi05
title: π₀.₅ (Pi05)
+ - local: libero
+ title: Using Libero
title: "Policies"
-
- sections:
- local: introduction_processors
title: Introduction to Robot Processors
diff --git a/docs/source/lerobot-dataset-v3.mdx b/docs/source/lerobot-dataset-v3.mdx
index 4f33d9a25..09fb17fad 100644
--- a/docs/source/lerobot-dataset-v3.mdx
+++ b/docs/source/lerobot-dataset-v3.mdx
@@ -8,6 +8,7 @@ This docs will guide you to:
- Record a dataset and push it to the Hub
- Load datasets for training with `LeRobotDataset`
- Stream datasets without downloading using `StreamingLeRobotDataset`
+- Apply image transforms for data augmentation during training
- Migrate existing `v2.1` datasets to `v3.0`
## What’s new in `v3`
@@ -150,6 +151,117 @@ dataset = StreamingLeRobotDataset(repo_id) # streams directly from the Hub
+## Image transforms
+
+Image transforms are data augmentations applied to camera frames during training to improve model robustness and generalization. LeRobot supports various transforms including brightness, contrast, saturation, hue, and sharpness adjustments.
+
+### Using transforms during dataset creation/recording
+
+Currently, transforms are applied during **training time only**, not during recording. When you create or record a dataset, the raw images are stored without transforms. This allows you to experiment with different augmentations later without re-recording data.
+
+### Adding transforms to existing datasets (API)
+
+Use the `image_transforms` parameter when loading a dataset for training:
+
+```python
+from lerobot.datasets.lerobot_dataset import LeRobotDataset
+from lerobot.datasets.transforms import ImageTransforms, ImageTransformsConfig, ImageTransformConfig
+
+# Option 1: Use default transform configuration (disabled by default)
+transforms_config = ImageTransformsConfig(
+ enable=True, # Enable transforms
+ max_num_transforms=3, # Apply up to 3 transforms per frame
+ random_order=False, # Apply in standard order
+)
+transforms = ImageTransforms(transforms_config)
+
+dataset = LeRobotDataset(
+ repo_id="your-username/your-dataset",
+ image_transforms=transforms
+)
+
+# Option 2: Create custom transform configuration
+custom_transforms_config = ImageTransformsConfig(
+ enable=True,
+ max_num_transforms=2,
+ random_order=True,
+ tfs={
+ "brightness": ImageTransformConfig(
+ weight=1.0,
+ type="ColorJitter",
+ kwargs={"brightness": (0.7, 1.3)} # Adjust brightness range
+ ),
+ "contrast": ImageTransformConfig(
+ weight=2.0, # Higher weight = more likely to be selected
+ type="ColorJitter",
+ kwargs={"contrast": (0.8, 1.2)}
+ ),
+ "sharpness": ImageTransformConfig(
+ weight=0.5, # Lower weight = less likely to be selected
+ type="SharpnessJitter",
+ kwargs={"sharpness": (0.3, 2.0)}
+ ),
+ }
+)
+
+dataset = LeRobotDataset(
+ repo_id="your-username/your-dataset",
+ image_transforms=ImageTransforms(custom_transforms_config)
+)
+
+# Option 3: Use pure torchvision transforms
+from torchvision.transforms import v2
+
+torchvision_transforms = v2.Compose([
+ v2.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
+ v2.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
+])
+
+dataset = LeRobotDataset(
+ repo_id="your-username/your-dataset",
+ image_transforms=torchvision_transforms
+)
+```
+
+### Available transform types
+
+LeRobot provides several transform types:
+
+- **`ColorJitter`**: Adjusts brightness, contrast, saturation, and hue
+- **`SharpnessJitter`**: Randomly adjusts image sharpness
+- **`Identity`**: No transformation (useful for testing)
+
+You can also use any `torchvision.transforms.v2` transform by passing it directly to the `image_transforms` parameter.
+
+### Configuration options
+
+- **`enable`**: Enable/disable transforms (default: `False`)
+- **`max_num_transforms`**: Maximum number of transforms applied per frame (default: `3`)
+- **`random_order`**: Apply transforms in random order vs. standard order (default: `False`)
+- **`weight`**: Sampling probability for each transform (higher = more likely, if sum of weights is not 1, they will be normalized)
+- **`kwargs`**: Transform-specific parameters (e.g., brightness range)
+
+### Visualizing transforms
+
+Use the visualization script to preview how transforms affect your data:
+
+```bash
+python -m lerobot.scripts.visualize_image_transforms \
+ --repo-id=your-username/your-dataset \
+ --output-dir=./transform_examples \
+ --n-examples=5
+```
+
+This saves example images showing the effect of each transform, helping you tune parameters.
+
+### Best practices
+
+- **Start conservative**: Begin with small ranges (e.g., brightness 0.9-1.1) and increase gradually
+- **Test first**: Use the visualization script to ensure transforms look reasonable
+- **Monitor training**: Strong augmentations can hurt performance if too aggressive
+- **Match your domain**: If your robot operates in varying lighting, use brightness/contrast transforms
+- **Combine wisely**: Using too many transforms simultaneously can make training unstable
+
## Migrate `v2.1` → `v3.0`
A converter aggregates per‑episode files into larger shards and writes episode offsets/metadata. Convert your dataset using the instructions below.
diff --git a/docs/source/libero.mdx b/docs/source/libero.mdx
new file mode 100644
index 000000000..488c02ce0
--- /dev/null
+++ b/docs/source/libero.mdx
@@ -0,0 +1,126 @@
+# LIBERO
+
+**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers.
+
+- 📄 [LIBERO paper](https://arxiv.org/abs/2306.03310)
+- 💻 [Original LIBERO repo](https://github.com/Lifelong-Robot-Learning/LIBERO)
+
+To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
+
+LIBERO includes **five task suites**:
+
+- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
+- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
+- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
+- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
+- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
+
+Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
+
+
+
+## Evaluating with LIBERO
+
+At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it mainly to **evaluate [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model.
+
+LIBERO is now part of our **multi-eval supported simulation**, meaning you can benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a flag.
+
+To Install LIBERO, after following LeRobot official instructions, just do:
+`pip install -e ".[libero]"`
+
+### Single-suite evaluation
+
+Evaluate a policy on one LIBERO suite:
+
+```bash
+python src/lerobot/scripts/eval.py \
+ --policy.path="your-policy-id" \
+ --env.type=libero \
+ --env.task=libero_object \
+ --eval.batch_size=2 \
+ --eval.n_episodes=3
+```
+
+- `--env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
+- `--eval.batch_size` controls how many environments run in parallel.
+- `--eval.n_episodes` sets how many episodes to run in total.
+
+---
+
+### Multi-suite evaluation
+
+Benchmark a policy across multiple suites at once:
+
+```bash
+python src/lerobot/scripts/eval.py \
+ --policy.path="your-policy-id" \
+ --env.type=libero \
+ --env.task=libero_object,libero_spatial \
+ --eval.batch_size=1 \
+ --eval.n_episodes=2
+```
+
+- Pass a comma-separated list to `--env.task` for multi-suite evaluation.
+
+### Policy inputs and outputs
+
+When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
+
+- **Observations**
+ - `observation.state` – proprioceptive features (agent state).
+ - `observation.images.image` – main camera view (`agentview_image`).
+ - `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
+
+ ⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any multi-modal visual features. Always ensure that your policy config `input_features` use the same naming keys, and that your dataset metadata keys follow this convention during evaluation.
+ If your data contains different keys, you must rename the observations to match what the policy expects, since naming keys are encoded inside the normalization statistics layer.
+ This will be fixed with the upcoming Pipeline PR.
+
+- **Actions**
+ - Continuous control values in a `Box(-1, 1, shape=(7,))` space.
+
+We also provide a notebook for quick testing:
+Training with LIBERO
+
+## Training with LIBERO
+
+When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
+
+The environment expects:
+
+- `observation.state` → 8-dim agent state
+- `observation.images.image` → main camera (`agentview_image`)
+- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
+
+⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code.
+To avoid potential mismatches and key errors, we provide a **preprocessed LIBERO dataset** that is fully compatible with the current LeRobot codebase and requires no additional manipulation:
+👉 [HuggingFaceVLA/libero](https://huggingface.co/datasets/HuggingFaceVLA/libero)
+
+For reference, here is the **original dataset** published by Physical Intelligence:
+👉 [physical-intelligence/libero](https://huggingface.co/datasets/physical-intelligence/libero)
+
+---
+
+### Example training command
+
+```bash
+python src/lerobot/scripts/train.py \
+ --policy.type=smolvla \
+ --policy.repo_id=${HF_USER}/libero-test \
+ --dataset.repo_id=jadechoghari/smol-libero3 \
+ --env.type=libero \
+ --env.task=libero_10 \
+ --output_dir=./outputs/ \
+ --steps=100000 \
+ --batch_size=4 \
+ --eval.batch_size=1 \
+ --eval.n_episodes=1 \
+ --eval_freq=1000 \
+```
+
+---
+
+### Note on rendering
+
+LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
+
+- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
diff --git a/docs/source/phone_teleop.mdx b/docs/source/phone_teleop.mdx
index 71d5457fb..bab0ac28e 100644
--- a/docs/source/phone_teleop.mdx
+++ b/docs/source/phone_teleop.mdx
@@ -36,7 +36,7 @@ Links:
- iOS: Analog input `A3` controls the gripper as velocity input.
- Android: Buttons `A` and `B` act like increment/decrement (A opens, B closes). You can tune velocity in the `GripperVelocityToJoint` step.
- +
+ ### Step 1: Choose the platform
diff --git a/examples/2_evaluate_pretrained_policy.py b/examples/2_evaluate_pretrained_policy.py
deleted file mode 100644
index c0c7845e8..000000000
--- a/examples/2_evaluate_pretrained_policy.py
+++ /dev/null
@@ -1,139 +0,0 @@
-# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-This script demonstrates how to evaluate a pretrained policy from the HuggingFace Hub or from your local
-training outputs directory. In the latter case, you might want to run examples/3_train_policy.py first.
-
-It requires the installation of the 'gym_pusht' simulation environment. Install it by running:
-```bash
-pip install -e ".[pusht]"
-```
-"""
-
-from pathlib import Path
-
-import gym_pusht # noqa: F401
-import gymnasium as gym
-import imageio
-import numpy
-import torch
-
-from lerobot.policies.diffusion.modeling_diffusion import DiffusionPolicy
-
-# Create a directory to store the video of the evaluation
-output_directory = Path("outputs/eval/example_pusht_diffusion")
-output_directory.mkdir(parents=True, exist_ok=True)
-
-# Select your device
-device = "cuda"
-
-# Provide the [hugging face repo id](https://huggingface.co/lerobot/diffusion_pusht):
-pretrained_policy_path = "lerobot/diffusion_pusht"
-# OR a path to a local outputs/train folder.
-# pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")
-
-policy = DiffusionPolicy.from_pretrained(pretrained_policy_path)
-
-# Initialize evaluation environment to render two observation types:
-# an image of the scene and state/position of the agent. The environment
-# also automatically stops running after 300 interactions/steps.
-env = gym.make(
- "gym_pusht/PushT-v0",
- obs_type="pixels_agent_pos",
- max_episode_steps=300,
-)
-
-# We can verify that the shapes of the features expected by the policy match the ones from the observations
-# produced by the environment
-print(policy.config.input_features)
-print(env.observation_space)
-
-# Similarly, we can check that the actions produced by the policy will match the actions expected by the
-# environment
-print(policy.config.output_features)
-print(env.action_space)
-
-# Reset the policy and environments to prepare for rollout
-policy.reset()
-numpy_observation, info = env.reset(seed=42)
-
-# Prepare to collect every rewards and all the frames of the episode,
-# from initial state to final state.
-rewards = []
-frames = []
-
-# Render frame of the initial state
-frames.append(env.render())
-
-step = 0
-done = False
-while not done:
- # Prepare observation for the policy running in Pytorch
- state = torch.from_numpy(numpy_observation["agent_pos"])
- image = torch.from_numpy(numpy_observation["pixels"])
-
- # Convert to float32 with image from channel first in [0,255]
- # to channel last in [0,1]
- state = state.to(torch.float32)
- image = image.to(torch.float32) / 255
- image = image.permute(2, 0, 1)
-
- # Send data tensors from CPU to GPU
- state = state.to(device, non_blocking=True)
- image = image.to(device, non_blocking=True)
-
- # Add extra (empty) batch dimension, required to forward the policy
- state = state.unsqueeze(0)
- image = image.unsqueeze(0)
-
- # Create the policy input dictionary
- observation = {
- "observation.state": state,
- "observation.image": image,
- }
-
- # Predict the next action with respect to the current observation
- with torch.inference_mode():
- action = policy.select_action(observation)
-
- # Prepare the action for the environment
- numpy_action = action.squeeze(0).to("cpu").numpy()
-
- # Step through the environment and receive a new observation
- numpy_observation, reward, terminated, truncated, info = env.step(numpy_action)
- print(f"{step=} {reward=} {terminated=}")
-
- # Keep track of all the rewards and frames
- rewards.append(reward)
- frames.append(env.render())
-
- # The rollout is considered done when the success state is reached (i.e. terminated is True),
- # or the maximum number of iterations is reached (i.e. truncated is True)
- done = terminated | truncated | done
- step += 1
-
-if terminated:
- print("Success!")
-else:
- print("Failure!")
-
-# Get the speed of environment (i.e. its number of frames per second).
-fps = env.metadata["render_fps"]
-
-# Encode all frames into a mp4 video.
-video_path = output_directory / "rollout.mp4"
-imageio.mimsave(str(video_path), numpy.stack(frames), fps=fps)
-
-print(f"Video of the evaluation is available in '{video_path}'.")
diff --git a/examples/4_train_policy_with_script.md b/examples/4_train_policy_with_script.md
deleted file mode 100644
index ffa7de66e..000000000
--- a/examples/4_train_policy_with_script.md
+++ /dev/null
@@ -1,311 +0,0 @@
-This tutorial will explain the training script, how to use it, and particularly how to configure everything needed for the training run.
-
-> **Note:** The following assumes you're running these commands on a machine equipped with a cuda GPU. If you don't have one (or if you're using a Mac), you can add `--policy.device=cpu` (`--policy.device=mps` respectively). However, be advised that the code executes much slower on cpu.
-
-## The training script
-
-LeRobot offers a training script at [`lerobot/scripts/train.py`](../src/lerobot/scripts/train.py). At a high level it does the following:
-
-- Initialize/load a configuration for the following steps using.
-- Instantiates a dataset.
-- (Optional) Instantiates a simulation environment corresponding to that dataset.
-- Instantiates a policy.
-- Runs a standard training loop with forward pass, backward pass, optimization step, and occasional logging, evaluation (of the policy on the environment), and checkpointing.
-
-## Overview of the configuration system
-
-In the training script, the main function `train` expects a `TrainPipelineConfig` object:
-
-
-```python
-# train.py
-@parser.wrap()
-def train(cfg: TrainPipelineConfig):
-```
-
-
-You can inspect the `TrainPipelineConfig` defined in [`lerobot/configs/train.py`](../src/lerobot/configs/train.py) (which is heavily commented and meant to be a reference to understand any option)
-
-When running the script, inputs for the command line are parsed thanks to the `@parser.wrap()` decorator and an instance of this class is automatically generated. Under the hood, this is done with [Draccus](https://github.com/dlwh/draccus) which is a tool dedicated to this purpose. If you're familiar with Hydra, Draccus can similarly load configurations from config files (.json, .yaml) and also override their values through command line inputs. Unlike Hydra, these configurations are pre-defined in the code through dataclasses rather than being defined entirely in config files. This allows for more rigorous serialization/deserialization, typing, and to manipulate configuration as objects directly in the code and not as dictionaries or namespaces (which enables nice features in an IDE such as autocomplete, jump-to-def, etc.)
-
-Let's have a look at a simplified example. Amongst other attributes, the training config has the following attributes:
-
-
-```python
-@dataclass
-class TrainPipelineConfig:
- dataset: DatasetConfig
- env: envs.EnvConfig | None = None
- policy: PreTrainedConfig | None = None
-```
-
-
-in which `DatasetConfig` for example is defined as such:
-
-
-```python
-@dataclass
-class DatasetConfig:
- repo_id: str
- episodes: list[int] | None = None
- video_backend: str = "pyav"
-```
-
-
-This creates a hierarchical relationship where, for example assuming we have a `cfg` instance of `TrainPipelineConfig`, we can access the `repo_id` value with `cfg.dataset.repo_id`.
-From the command line, we can specify this value by using a very similar syntax `--dataset.repo_id=repo/id`.
-
-By default, every field takes its default value specified in the dataclass. If a field doesn't have a default value, it needs to be specified either from the command line or from a config file – which path is also given in the command line (more in this below). In the example above, the `dataset` field doesn't have a default value which means it must be specified.
-
-## Specifying values from the CLI
-
-Let's say that we want to train [Diffusion Policy](../src/lerobot/policies/diffusion) on the [pusht](https://huggingface.co/datasets/lerobot/pusht) dataset, using the [gym_pusht](https://github.com/huggingface/gym-pusht) environment for evaluation. The command to do so would look like this:
-
-```bash
-lerobot-train \
- --dataset.repo_id=lerobot/pusht \
- --policy.type=diffusion \
- --env.type=pusht
-```
-
-Let's break this down:
-
-- To specify the dataset, we just need to specify its `repo_id` on the hub which is the only required argument in the `DatasetConfig`. The rest of the fields have default values and in this case we are fine with those so we can just add the option `--dataset.repo_id=lerobot/pusht`.
-- To specify the policy, we can just select diffusion policy using `--policy` appended with `.type`. Here, `.type` is a special argument which allows us to select config classes inheriting from `draccus.ChoiceRegistry` and that have been decorated with the `register_subclass()` method. To have a better explanation of this feature, have a look at this [Draccus demo](https://github.com/dlwh/draccus?tab=readme-ov-file#more-flexible-configuration-with-choice-types). In our code, we use this mechanism mainly to select policies, environments, robots, and some other components like optimizers. The policies available to select are located in [lerobot/policies](../src/lerobot/policies)
-- Similarly, we select the environment with `--env.type=pusht`. The different environment configs are available in [`lerobot/envs/configs.py`](../src/lerobot/envs/configs.py)
-
-Let's see another example. Let's say you've been training [ACT](../src/lerobot/policies/act) on [lerobot/aloha_sim_insertion_human](https://huggingface.co/datasets/lerobot/aloha_sim_insertion_human) using the [gym-aloha](https://github.com/huggingface/gym-aloha) environment for evaluation with:
-
-```bash
-lerobot-train \
- --policy.type=act \
- --dataset.repo_id=lerobot/aloha_sim_insertion_human \
- --env.type=aloha \
- --output_dir=outputs/train/act_aloha_insertion
-```
-
-> Notice we added `--output_dir` to explicitly tell where to write outputs from this run (checkpoints, training state, configs etc.). This is not mandatory and if you don't specify it, a default directory will be created from the current date and time, env.type and policy.type. This will typically look like `outputs/train/2025-01-24/16-10-05_aloha_act`.
-
-We now want to train a different policy for aloha on another task. We'll change the dataset and use [lerobot/aloha_sim_transfer_cube_human](https://huggingface.co/datasets/lerobot/aloha_sim_transfer_cube_human) instead. Of course, we also need to change the task of the environment as well to match this other task.
-Looking at the [`AlohaEnv`](../src/lerobot/envs/configs.py) config, the task is `"AlohaInsertion-v0"` by default, which corresponds to the task we trained on in the command above. The [gym-aloha](https://github.com/huggingface/gym-aloha?tab=readme-ov-file#description) environment also has the `AlohaTransferCube-v0` task which corresponds to this other task we want to train on. Putting this together, we can train this new policy on this different task using:
-
-```bash
-lerobot-train \
- --policy.type=act \
- --dataset.repo_id=lerobot/aloha_sim_transfer_cube_human \
- --env.type=aloha \
- --env.task=AlohaTransferCube-v0 \
- --output_dir=outputs/train/act_aloha_transfer
-```
-
-## Loading from a config file
-
-Now, let's assume that we want to reproduce the run just above. That run has produced a `train_config.json` file in its checkpoints, which serializes the `TrainPipelineConfig` instance it used:
-
-```json
-{
- "dataset": {
- "repo_id": "lerobot/aloha_sim_transfer_cube_human",
- "episodes": null,
- ...
- },
- "env": {
- "type": "aloha",
- "task": "AlohaTransferCube-v0",
- "fps": 50,
- ...
- },
- "policy": {
- "type": "act",
- "n_obs_steps": 1,
- ...
- },
- ...
-}
-```
-
-We can then simply load the config values from this file using:
-
-```bash
-lerobot-train \
- --config_path=outputs/train/act_aloha_transfer/checkpoints/last/pretrained_model/ \
- --output_dir=outputs/train/act_aloha_transfer_2
-```
-
-`--config_path` is also a special argument which allows to initialize the config from a local config file. It can point to a directory that contains `train_config.json` or to the config file itself directly.
-
-Similarly to Hydra, we can still override some parameters in the CLI if we want to, e.g.:
-
-```bash
-lerobot-train \
- --config_path=outputs/train/act_aloha_transfer/checkpoints/last/pretrained_model/ \
- --output_dir=outputs/train/act_aloha_transfer_2
- --policy.n_action_steps=80
-```
-
-> Note: While `--output_dir` is not required in general, in this case we need to specify it since it will otherwise take the value from the `train_config.json` (which is `outputs/train/act_aloha_transfer`). In order to prevent accidental deletion of previous run checkpoints, we raise an error if you're trying to write in an existing directory. This is not the case when resuming a run, which is what you'll learn next.
-
-`--config_path` can also accept the repo_id of a repo on the hub that contains a `train_config.json` file, e.g. running:
-
-```bash
-lerobot-train --config_path=lerobot/diffusion_pusht
-```
-
-will start a training run with the same configuration used for training [lerobot/diffusion_pusht](https://huggingface.co/lerobot/diffusion_pusht)
-
-## Resume training
-
-Being able to resume a training run is important in case it crashed or aborted for any reason. We'll demonstrate how to do that here.
-
-Let's reuse the command from the previous run and add a few more options:
-
-```bash
-lerobot-train \
- --policy.type=act \
- --dataset.repo_id=lerobot/aloha_sim_transfer_cube_human \
- --env.type=aloha \
- --env.task=AlohaTransferCube-v0 \
- --log_freq=25 \
- --save_freq=100 \
- --output_dir=outputs/train/run_resumption
-```
-
-Here we've taken care to set up the log frequency and checkpointing frequency to low numbers so we can showcase resumption. You should be able to see some logging and have a first checkpoint within 1 minute (depending on hardware). Wait for the first checkpoint to happen, you should see a line that looks like this in your terminal:
-
-```
-INFO 2025-01-24 16:10:56 ts/train.py:263 Checkpoint policy after step 100
-```
-
-Now let's simulate a crash by killing the process (hit `ctrl`+`c`). We can then simply resume this run from the last checkpoint available with:
-
-```bash
-lerobot-train \
- --config_path=outputs/train/run_resumption/checkpoints/last/pretrained_model/ \
- --resume=true
-```
-
-You should see from the logging that your training picks up from where it left off.
-
-Another reason for which you might want to resume a run is simply to extend training and add more training steps. The number of training steps is set by the option `--steps`, which is 100 000 by default.
-You could double the number of steps of the previous run with:
-
-```bash
-lerobot-train \
- --config_path=outputs/train/run_resumption/checkpoints/last/pretrained_model/ \
- --resume=true \
- --steps=200000
-```
-
-## Outputs of a run
-
-In the output directory, there will be a folder called `checkpoints` with the following structure:
-
-```bash
-outputs/train/run_resumption/checkpoints
-├── 000100 # checkpoint_dir for training step 100
-│ ├── pretrained_model/
-│ │ ├── config.json # policy config
-│ │ ├── model.safetensors # policy weights
-│ │ └── train_config.json # train config
-│ └── training_state/
-│ ├── optimizer_param_groups.json # optimizer param groups
-│ ├── optimizer_state.safetensors # optimizer state
-│ ├── rng_state.safetensors # rng states
-│ ├── scheduler_state.json # scheduler state
-│ └── training_step.json # training step
-├── 000200
-└── last -> 000200 # symlink to the last available checkpoint
-```
-
-## Fine-tuning a pre-trained policy
-
-In addition to the features currently in Draccus, we've added a special `.path` argument for the policy, which allows to load a policy as you would with `PreTrainedPolicy.from_pretrained()`. In that case, `path` can be a local directory that contains a checkpoint or a repo_id pointing to a pretrained policy on the hub.
-
-For example, we could fine-tune a [policy pre-trained on the aloha transfer task](https://huggingface.co/lerobot/act_aloha_sim_transfer_cube_human) on the aloha insertion task. We can achieve this with:
-
-```bash
-lerobot-train \
- --policy.path=lerobot/act_aloha_sim_transfer_cube_human \
- --dataset.repo_id=lerobot/aloha_sim_insertion_human \
- --env.type=aloha \
- --env.task=AlohaInsertion-v0
-```
-
-When doing so, keep in mind that the features of the fine-tuning dataset would have to match the input/output features of the pretrained policy.
-
-## Typical logs and metrics
-
-When you start the training process, you will first see your full configuration being printed in the terminal. You can check it to make sure that you configured your run correctly. The final configuration will also be saved with the checkpoint.
-
-After that, you will see training log like this one:
-
-```
-INFO 2024-08-14 13:35:12 ts/train.py:192 step:0 smpl:64 ep:1 epch:0.00 loss:1.112 grdn:15.387 lr:2.0e-07 updt_s:1.738 data_s:4.774
-```
-
-or evaluation log:
-
-```
-INFO 2024-08-14 13:38:45 ts/train.py:226 step:100 smpl:6K ep:52 epch:0.25 ∑rwrd:20.693 success:0.0% eval_s:120.266
-```
-
-These logs will also be saved in wandb if `wandb.enable` is set to `true`. Here are the meaning of some abbreviations:
-
-- `smpl`: number of samples seen during training.
-- `ep`: number of episodes seen during training. An episode contains multiple samples in a complete manipulation task.
-- `epch`: number of time all unique samples are seen (epoch).
-- `grdn`: gradient norm.
-- `∑rwrd`: compute the sum of rewards in every evaluation episode and then take an average of them.
-- `success`: average success rate of eval episodes. Reward and success are usually different except for the sparsing reward setting, where reward=1 only when the task is completed successfully.
-- `eval_s`: time to evaluate the policy in the environment, in second.
-- `updt_s`: time to update the network parameters, in second.
-- `data_s`: time to load a batch of data, in second.
-
-Some metrics are useful for initial performance profiling. For example, if you find the current GPU utilization is low via the `nvidia-smi` command and `data_s` sometimes is too high, you may need to modify batch size or number of dataloading workers to accelerate dataloading. We also recommend [pytorch profiler](https://github.com/huggingface/lerobot?tab=readme-ov-file#improve-your-code-with-profiling) for detailed performance probing.
-
-## In short
-
-We'll summarize here the main use cases to remember from this tutorial.
-
-#### Train a policy from scratch – CLI
-
-```bash
-lerobot-train \
- --policy.type=act \ # <- select 'act' policy
- --env.type=pusht \ # <- select 'pusht' environment
- --dataset.repo_id=lerobot/pusht # <- train on this dataset
-```
-
-#### Train a policy from scratch - config file + CLI
-
-```bash
-lerobot-train \
- --config_path=path/to/pretrained_model \ # <- can also be a repo_id
- --policy.n_action_steps=80 # <- you may still override values
-```
-
-#### Resume/continue a training run
-
-```bash
-lerobot-train \
- --config_path=checkpoint/pretrained_model/ \
- --resume=true \
- --steps=200000 # <- you can change some training parameters
-```
-
-#### Fine-tuning
-
-```bash
-lerobot-train \
- --policy.path=lerobot/act_aloha_sim_transfer_cube_human \ # <- can also be a local path to a checkpoint
- --dataset.repo_id=lerobot/aloha_sim_insertion_human \
- --env.type=aloha \
- --env.task=AlohaInsertion-v0
-```
-
----
-
-Now that you know the basics of how to train a policy, you might want to know how to apply this knowledge to actual robots, or how to record your own datasets and train policies on your specific task?
-If that's the case, head over to the next tutorial [`7_get_started_with_real_robot.md`](./7_get_started_with_real_robot.md).
-
-Or in the meantime, happy training! 🤗
diff --git a/examples/1_load_lerobot_dataset.py b/examples/dataset/load_lerobot_dataset.py
similarity index 99%
rename from examples/1_load_lerobot_dataset.py
rename to examples/dataset/load_lerobot_dataset.py
index ac4a843c7..a96c170cf 100644
--- a/examples/1_load_lerobot_dataset.py
+++ b/examples/dataset/load_lerobot_dataset.py
@@ -136,7 +136,7 @@ print(f"{dataset[0]['action'].shape=}\n") # (64, c)
# PyTorch datasets.
dataloader = torch.utils.data.DataLoader(
dataset,
- num_workers=0,
+ num_workers=4,
batch_size=32,
shuffle=True,
)
diff --git a/examples/dataset/use_dataset_image_transforms.py b/examples/dataset/use_dataset_image_transforms.py
new file mode 100644
index 000000000..c28f2ef0c
--- /dev/null
+++ b/examples/dataset/use_dataset_image_transforms.py
@@ -0,0 +1,177 @@
+#!/usr/bin/env python
+
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""
+This example demonstrates how to use image transforms with LeRobot datasets for data augmentation during training.
+
+Image transforms are applied to camera frames to improve model robustness and generalization. They are applied
+at training time only, not during dataset recording, allowing you to experiment with different augmentations
+without re-recording data.
+"""
+
+import torch
+from torchvision.transforms import v2
+from torchvision.transforms.functional import to_pil_image
+
+from lerobot.datasets.lerobot_dataset import LeRobotDataset
+from lerobot.datasets.transforms import ImageTransformConfig, ImageTransforms, ImageTransformsConfig
+
+
+def save_image(tensor, filename):
+ """Helper function to save a tensor as an image file."""
+ if tensor.dim() == 3: # [C, H, W]
+ if tensor.max() > 1.0:
+ tensor = tensor / 255.0
+ tensor = torch.clamp(tensor, 0.0, 1.0)
+ pil_image = to_pil_image(tensor)
+ pil_image.save(filename)
+ print(f"Saved: {filename}")
+ else:
+ print(f"Skipped {filename}: unexpected tensor shape {tensor.shape}")
+
+
+def example_1_default_transforms():
+ """Example 1: Use default transform configuration and save original vs transformed images"""
+ print("\n Example 1: Default Transform Configuration with Image Saving")
+
+ repo_id = "pepijn223/record_main_0" # Example dataset
+
+ try:
+ # Load dataset without transforms (original)
+ dataset_original = LeRobotDataset(repo_id=repo_id)
+
+ # Load dataset with transforms enabled
+ transforms_config = ImageTransformsConfig(
+ enable=True, # Enable transforms (disabled by default)
+ max_num_transforms=2, # Apply up to 2 transforms per frame
+ random_order=False, # Apply in standard order
+ )
+ dataset_with_transforms = LeRobotDataset(
+ repo_id=repo_id, image_transforms=ImageTransforms(transforms_config)
+ )
+
+ # Save original and transformed images for comparison
+ if len(dataset_original) > 0:
+ frame_idx = 0 # Use first frame
+ original_sample = dataset_original[frame_idx]
+ transformed_sample = dataset_with_transforms[frame_idx]
+
+ print(f"Saving comparison images (frame {frame_idx}):")
+
+ for cam_key in dataset_original.meta.camera_keys:
+ if cam_key in original_sample and cam_key in transformed_sample:
+ cam_name = cam_key.replace(".", "_").replace("/", "_")
+
+ # Save original and transformed images
+ save_image(original_sample[cam_key], f"{cam_name}_original.png")
+ save_image(transformed_sample[cam_key], f"{cam_name}_transformed.png")
+
+ except Exception as e:
+ print(f"Could not load dataset '{repo_id}': {e}")
+
+
+def example_2_custom_transforms():
+ """Example 2: Create custom transform configuration and save examples"""
+ print("\n Example 2: Custom Transform Configuration")
+
+ repo_id = "pepijn223/record_main_0" # Example dataset
+
+ try:
+ # Create custom transform configuration with strong effects
+ custom_transforms_config = ImageTransformsConfig(
+ enable=True,
+ max_num_transforms=2, # Apply up to 2 transforms per frame
+ random_order=True, # Apply transforms in random order
+ tfs={
+ "brightness": ImageTransformConfig(
+ weight=1.0,
+ type="ColorJitter",
+ kwargs={"brightness": (0.5, 1.5)}, # Strong brightness range
+ ),
+ "contrast": ImageTransformConfig(
+ weight=1.0, # Higher weight = more likely to be selected
+ type="ColorJitter",
+ kwargs={"contrast": (0.6, 1.4)}, # Strong contrast
+ ),
+ "sharpness": ImageTransformConfig(
+ weight=0.5, # Lower weight = less likely to be selected
+ type="SharpnessJitter",
+ kwargs={"sharpness": (0.2, 2.0)}, # Strong sharpness variation
+ ),
+ },
+ )
+
+ dataset_with_custom_transforms = LeRobotDataset(
+ repo_id=repo_id, image_transforms=ImageTransforms(custom_transforms_config)
+ )
+
+ # Save examples with strong transforms
+ if len(dataset_with_custom_transforms) > 0:
+ sample = dataset_with_custom_transforms[0]
+ print("Saving custom transform examples:")
+
+ for cam_key in dataset_with_custom_transforms.meta.camera_keys:
+ if cam_key in sample:
+ cam_name = cam_key.replace(".", "_").replace("/", "_")
+ save_image(sample[cam_key], f"{cam_name}_custom_transforms.png")
+
+ except Exception as e:
+ print(f"Could not load dataset '{repo_id}': {e}")
+
+
+def example_3_torchvision_transforms():
+ """Example 3: Use pure torchvision transforms and save examples"""
+ print("\n Example 3: Pure Torchvision Transforms")
+
+ repo_id = "pepijn223/record_main_0" # Example dataset
+
+ try:
+ # Create torchvision transform pipeline
+ torchvision_transforms = v2.Compose(
+ [
+ v2.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.1),
+ v2.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
+ v2.RandomRotation(degrees=10), # Small rotation
+ ]
+ )
+
+ dataset_with_torchvision = LeRobotDataset(repo_id=repo_id, image_transforms=torchvision_transforms)
+
+ # Save examples with torchvision transforms
+ if len(dataset_with_torchvision) > 0:
+ sample = dataset_with_torchvision[0]
+ print("Saving torchvision transform examples:")
+
+ for cam_key in dataset_with_torchvision.meta.camera_keys:
+ if cam_key in sample:
+ cam_name = cam_key.replace(".", "_").replace("/", "_")
+ save_image(sample[cam_key], f"{cam_name}_torchvision.png")
+
+ except Exception as e:
+ print(f"Could not load dataset '{repo_id}': {e}")
+
+
+def main():
+ """Run all examples"""
+ print("LeRobot Dataset Image Transforms Examples")
+
+ example_1_default_transforms()
+ example_2_custom_transforms()
+ example_3_torchvision_transforms()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/examples/3_train_policy.py b/examples/training/train_policy.py
similarity index 97%
rename from examples/3_train_policy.py
rename to examples/training/train_policy.py
index 7f3fad36c..16f2a4d87 100644
--- a/examples/3_train_policy.py
+++ b/examples/training/train_policy.py
@@ -12,11 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-"""This script demonstrates how to train Diffusion Policy on the PushT environment.
-
-Once you have trained a model with this script, you can try to evaluate it on
-examples/2_evaluate_pretrained_policy.py
-"""
+"""This script demonstrates how to train Diffusion Policy on the PushT environment."""
from pathlib import Path
diff --git a/examples/5_train_with_streaming.py b/examples/training/train_with_streaming.py
similarity index 93%
rename from examples/5_train_with_streaming.py
rename to examples/training/train_with_streaming.py
index 93d13535f..e7edc17f8 100644
--- a/examples/5_train_with_streaming.py
+++ b/examples/training/train_with_streaming.py
@@ -13,11 +13,7 @@
# limitations under the License.
"""This script demonstrates how to train a Diffusion Policy on the PushT environment,
-using a dataset processed in streaming mode.
-
-Once you have trained a model with this script, you can try to evaluate it on
-examples/2_evaluate_pretrained_policy.py
-"""
+using a dataset processed in streaming mode."""
from pathlib import Path
@@ -51,9 +47,7 @@ def main():
training_steps = 10
log_freq = 1
- dataset_id = (
- "aractingi/droid_1.0.1" # 26M frames! Would require 4TB of disk space if installed locally (:
- )
+ dataset_id = "lerobot/droid_1.0.1" # 26M frames! Would require 4TB of disk space if installed locally (:
dataset_metadata = LeRobotDatasetMetadata(dataset_id)
features = dataset_to_policy_features(dataset_metadata.features)
output_features = {key: ft for key, ft in features.items() if ft.type is FeatureType.ACTION}
diff --git a/pyproject.toml b/pyproject.toml
index 98ccc7b9b..45c4146f0 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -59,7 +59,7 @@ keywords = ["lerobot", "huggingface", "robotics", "machine learning", "artifici
dependencies = [
# Hugging Face dependencies
- "datasets>=2.19.0,<=3.6.0", # TODO: Bumb dependency
+ "datasets>=4.0.0",
"diffusers>=0.27.2",
"huggingface-hub[hf-transfer,cli]>=0.34.2",
@@ -121,7 +121,7 @@ phone = ["hebi-py>=2.8.0", "teleop>=0.1.0"]
# Policies
pi = ["lerobot[transformers-dep]"]
smolvla = ["lerobot[transformers-dep]", "num2words>=0.5.14", "accelerate>=1.7.0", "safetensors>=0.4.3"]
-hilserl = ["lerobot[transformers-dep]", "gym-hil>=0.1.9", "lerobot[grpcio-dep]", "lerobot[placo-dep]"]
+hilserl = ["lerobot[transformers-dep]", "gym-hil>=0.1.11", "lerobot[grpcio-dep]", "lerobot[placo-dep]"]
# Features
async = ["lerobot[grpcio-dep]", "matplotlib>=3.10.3"]
@@ -135,6 +135,8 @@ video_benchmark = ["scikit-image>=0.23.2", "pandas>=2.2.2"]
aloha = ["gym-aloha>=0.1.1"]
pusht = ["gym-pusht>=0.1.5", "pymunk>=6.6.0,<7.0.0"] # TODO: Fix pymunk version in gym-pusht instead
xarm = ["gym-xarm>=0.1.1"]
+libero = ["lerobot[transformers-dep]", "libero @ git+https://github.com/huggingface/lerobot-libero.git@main#egg=libero"]
+
# All
all = [
@@ -157,6 +159,7 @@ all = [
"lerobot[pusht]",
"lerobot[xarm]",
"lerobot[phone]",
+ "lerobot[libero]",
]
[project.scripts]
diff --git a/src/lerobot/envs/configs.py b/src/lerobot/envs/configs.py
index f71aca70d..8c66b278e 100644
--- a/src/lerobot/envs/configs.py
+++ b/src/lerobot/envs/configs.py
@@ -30,6 +30,8 @@ class EnvConfig(draccus.ChoiceRegistry, abc.ABC):
fps: int = 30
features: dict[str, PolicyFeature] = field(default_factory=dict)
features_map: dict[str, str] = field(default_factory=dict)
+ max_parallel_tasks: int = 1
+ disable_env_checker: bool = True
@property
def type(self) -> str:
@@ -242,3 +244,55 @@ class HILSerlRobotEnvConfig(EnvConfig):
@property
def gym_kwargs(self) -> dict:
return {}
+
+
+@EnvConfig.register_subclass("libero")
+@dataclass
+class LiberoEnv(EnvConfig):
+ task: str = "libero_10" # can also choose libero_spatial, libero_object, etc.
+ fps: int = 30
+ episode_length: int = 520
+ obs_type: str = "pixels_agent_pos"
+ render_mode: str = "rgb_array"
+ camera_name: str = "agentview_image,robot0_eye_in_hand_image"
+ init_states: bool = True
+ camera_name_mapping: dict[str, str] | None = (None,)
+ features: dict[str, PolicyFeature] = field(
+ default_factory=lambda: {
+ "action": PolicyFeature(type=FeatureType.ACTION, shape=(7,)),
+ }
+ )
+ features_map: dict[str, str] = field(
+ default_factory=lambda: {
+ "action": ACTION,
+ "agent_pos": OBS_STATE,
+ "pixels/agentview_image": f"{OBS_IMAGES}.image",
+ "pixels/robot0_eye_in_hand_image": f"{OBS_IMAGES}.image2",
+ }
+ )
+
+ def __post_init__(self):
+ if self.obs_type == "pixels":
+ self.features["pixels/agentview_image"] = PolicyFeature(
+ type=FeatureType.VISUAL, shape=(360, 360, 3)
+ )
+ self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
+ type=FeatureType.VISUAL, shape=(360, 360, 3)
+ )
+ elif self.obs_type == "pixels_agent_pos":
+ self.features["agent_pos"] = PolicyFeature(type=FeatureType.STATE, shape=(8,))
+ self.features["pixels/agentview_image"] = PolicyFeature(
+ type=FeatureType.VISUAL, shape=(360, 360, 3)
+ )
+ self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
+ type=FeatureType.VISUAL, shape=(360, 360, 3)
+ )
+ else:
+ raise ValueError(f"Unsupported obs_type: {self.obs_type}")
+
+ @property
+ def gym_kwargs(self) -> dict:
+ return {
+ "obs_type": self.obs_type,
+ "render_mode": self.render_mode,
+ }
diff --git a/src/lerobot/envs/factory.py b/src/lerobot/envs/factory.py
index af8f5eaf5..9b172854c 100644
--- a/src/lerobot/envs/factory.py
+++ b/src/lerobot/envs/factory.py
@@ -17,7 +17,7 @@ import importlib
import gymnasium as gym
-from lerobot.envs.configs import AlohaEnv, EnvConfig, PushtEnv, XarmEnv
+from lerobot.envs.configs import AlohaEnv, EnvConfig, LiberoEnv, PushtEnv, XarmEnv
def make_env_config(env_type: str, **kwargs) -> EnvConfig:
@@ -27,11 +27,15 @@ def make_env_config(env_type: str, **kwargs) -> EnvConfig:
return PushtEnv(**kwargs)
elif env_type == "xarm":
return XarmEnv(**kwargs)
+ elif env_type == "libero":
+ return LiberoEnv(**kwargs)
else:
raise ValueError(f"Policy type '{env_type}' is not available.")
-def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> gym.vector.VectorEnv | None:
+def make_env(
+ cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False
+) -> dict[str, dict[int, gym.vector.VectorEnv]]:
"""Makes a gym vector environment according to the config.
Args:
@@ -45,13 +49,30 @@ def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> g
ModuleNotFoundError: If the requested env package is not installed
Returns:
- gym.vector.VectorEnv: The parallelized gym.env instance.
+ dict[str, dict[int, gym.vector.VectorEnv]]:
+ A mapping from suite name to indexed vectorized environments.
+ - For multi-task benchmarks (e.g., LIBERO): one entry per suite, and one vec env per task_id.
+ - For single-task environments: a single suite entry (cfg.type) with task_id=0.
+
"""
if n_envs < 1:
- raise ValueError("`n_envs must be at least 1")
+ raise ValueError("`n_envs` must be at least 1")
+
+ env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
+
+ if "libero" in cfg.type:
+ from lerobot.envs.libero import create_libero_envs
+
+ return create_libero_envs(
+ task=cfg.task,
+ n_envs=n_envs,
+ camera_name=cfg.camera_name,
+ init_states=cfg.init_states,
+ gym_kwargs=cfg.gym_kwargs,
+ env_cls=env_cls,
+ )
package_name = f"gym_{cfg.type}"
-
try:
importlib.import_module(package_name)
except ModuleNotFoundError as e:
@@ -60,10 +81,11 @@ def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> g
gym_handle = f"{package_name}/{cfg.task}"
- # batched version of the env that returns an observation of shape (b, c)
- env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
- env = env_cls(
- [lambda: gym.make(gym_handle, disable_env_checker=True, **cfg.gym_kwargs) for _ in range(n_envs)]
- )
+ def _make_one():
+ return gym.make(gym_handle, disable_env_checker=cfg.disable_env_checker, **(cfg.gym_kwargs or {}))
- return env
+ vec = env_cls([_make_one for _ in range(n_envs)])
+
+ # normalize to {suite: {task_id: vec_env}} for consistency
+ suite_name = cfg.type # e.g., "pusht", "aloha"
+ return {suite_name: {0: vec}}
diff --git a/src/lerobot/envs/libero.py b/src/lerobot/envs/libero.py
new file mode 100644
index 000000000..466796975
--- /dev/null
+++ b/src/lerobot/envs/libero.py
@@ -0,0 +1,377 @@
+#!/usr/bin/env python
+
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import annotations
+
+import os
+from collections import defaultdict
+from collections.abc import Callable, Iterable, Mapping, Sequence
+from functools import partial
+from pathlib import Path
+from typing import Any
+
+import gymnasium as gym
+import numpy as np
+import torch
+from gymnasium import spaces
+from libero.libero import benchmark, get_libero_path
+from libero.libero.envs import OffScreenRenderEnv
+from robosuite.utils.transform_utils import quat2axisangle
+
+
+def _parse_camera_names(camera_name: str | Sequence[str]) -> list[str]:
+ """Normalize camera_name into a non-empty list of strings."""
+ if isinstance(camera_name, str):
+ cams = [c.strip() for c in camera_name.split(",") if c.strip()]
+ elif isinstance(camera_name, (list, tuple)):
+ cams = [str(c).strip() for c in camera_name if str(c).strip()]
+ else:
+ raise TypeError(f"camera_name must be str or sequence[str], got {type(camera_name).__name__}")
+ if not cams:
+ raise ValueError("camera_name resolved to an empty list.")
+ return cams
+
+
+def _get_suite(name: str) -> benchmark.Benchmark:
+ """Instantiate a LIBERO suite by name with clear validation."""
+ bench = benchmark.get_benchmark_dict()
+ if name not in bench:
+ raise ValueError(f"Unknown LIBERO suite '{name}'. Available: {', '.join(sorted(bench.keys()))}")
+ suite = bench[name]()
+ if not getattr(suite, "tasks", None):
+ raise ValueError(f"Suite '{name}' has no tasks.")
+ return suite
+
+
+def _select_task_ids(total_tasks: int, task_ids: Iterable[int] | None) -> list[int]:
+ """Validate/normalize task ids. If None → all tasks."""
+ if task_ids is None:
+ return list(range(total_tasks))
+ ids = sorted({int(t) for t in task_ids})
+ for t in ids:
+ if t < 0 or t >= total_tasks:
+ raise ValueError(f"task_id {t} out of range [0, {total_tasks - 1}].")
+ return ids
+
+
+def get_task_init_states(task_suite: Any, i: int) -> np.ndarray:
+ init_states_path = (
+ Path(get_libero_path("init_states"))
+ / task_suite.tasks[i].problem_folder
+ / task_suite.tasks[i].init_states_file
+ )
+ init_states = torch.load(init_states_path, weights_only=False) # nosec B614
+ return init_states
+
+
+def get_libero_dummy_action():
+ """Get dummy/no-op action, used to roll out the simulation while the robot does nothing."""
+ return [0, 0, 0, 0, 0, 0, -1]
+
+
+OBS_STATE_DIM = 8
+ACTION_DIM = 7
+AGENT_POS_LOW = -1000.0
+AGENT_POS_HIGH = 1000.0
+ACTION_LOW = -1.0
+ACTION_HIGH = 1.0
+TASK_SUITE_MAX_STEPS: dict[str, int] = {
+ "libero_spatial": 280, # longest training demo has 193 steps
+ "libero_object": 280, # longest training demo has 254 steps
+ "libero_goal": 300, # longest training demo has 270 steps
+ "libero_10": 520, # longest training demo has 505 steps
+ "libero_90": 400, # longest training demo has 373 steps
+}
+
+
+class LiberoEnv(gym.Env):
+ metadata = {"render_modes": ["rgb_array"], "render_fps": 80}
+
+ def __init__(
+ self,
+ task_suite: Any,
+ task_id: int,
+ task_suite_name: str,
+ camera_name: str | Sequence[str] = "agentview_image,robot0_eye_in_hand_image",
+ obs_type: str = "pixels",
+ render_mode: str = "rgb_array",
+ observation_width: int = 256,
+ observation_height: int = 256,
+ visualization_width: int = 640,
+ visualization_height: int = 480,
+ init_states: bool = True,
+ episode_index: int = 0,
+ camera_name_mapping: dict[str, str] | None = None,
+ num_steps_wait: int = 10,
+ ):
+ super().__init__()
+ self.task_id = task_id
+ self.obs_type = obs_type
+ self.render_mode = render_mode
+ self.observation_width = observation_width
+ self.observation_height = observation_height
+ self.visualization_width = visualization_width
+ self.visualization_height = visualization_height
+ self.init_states = init_states
+ self.camera_name = _parse_camera_names(
+ camera_name
+ ) # agentview_image (main) or robot0_eye_in_hand_image (wrist)
+
+ # Map raw camera names to "image1" and "image2".
+ # The preprocessing step `preprocess_observation` will then prefix these with `.images.*`,
+ # following the LeRobot convention (e.g., `observation.images.image`, `observation.images.image2`).
+ # This ensures the policy consistently receives observations in the
+ # expected format regardless of the original camera naming.
+ if camera_name_mapping is None:
+ camera_name_mapping = {
+ "agentview_image": "image",
+ "robot0_eye_in_hand_image": "image2",
+ }
+ self.camera_name_mapping = camera_name_mapping
+ self.num_steps_wait = num_steps_wait
+ self.episode_index = episode_index
+ # Load once and keep
+ self._init_states = get_task_init_states(task_suite, self.task_id) if self.init_states else None
+ self._init_state_id = self.episode_index # tie each sub-env to a fixed init state
+
+ self._env = self._make_envs_task(task_suite, self.task_id)
+ default_steps = 500
+ self._max_episode_steps = TASK_SUITE_MAX_STEPS.get(task_suite_name, default_steps)
+
+ images = {}
+ for cam in self.camera_name:
+ images[self.camera_name_mapping[cam]] = spaces.Box(
+ low=0,
+ high=255,
+ shape=(self.observation_height, self.observation_width, 3),
+ dtype=np.uint8,
+ )
+
+ if self.obs_type == "state":
+ raise NotImplementedError(
+ "The 'state' observation type is not supported in LiberoEnv. "
+ "Please switch to an image-based obs_type (e.g. 'pixels', 'pixels_agent_pos')."
+ )
+
+ elif self.obs_type == "pixels":
+ self.observation_space = spaces.Dict(
+ {
+ "pixels": spaces.Dict(images),
+ }
+ )
+ elif self.obs_type == "pixels_agent_pos":
+ self.observation_space = spaces.Dict(
+ {
+ "pixels": spaces.Dict(images),
+ "agent_pos": spaces.Box(
+ low=AGENT_POS_LOW,
+ high=AGENT_POS_HIGH,
+ shape=(OBS_STATE_DIM,),
+ dtype=np.float64,
+ ),
+ }
+ )
+
+ self.action_space = spaces.Box(
+ low=ACTION_LOW, high=ACTION_HIGH, shape=(ACTION_DIM,), dtype=np.float32
+ )
+
+ def render(self):
+ raw_obs = self._env.env._get_observations()
+ image = self._format_raw_obs(raw_obs)["pixels"]["image"]
+ return image
+
+ def _make_envs_task(self, task_suite: Any, task_id: int = 0):
+ task = task_suite.get_task(task_id)
+ self.task = task.name
+ self.task_description = task.language
+ task_bddl_file = os.path.join(get_libero_path("bddl_files"), task.problem_folder, task.bddl_file)
+
+ env_args = {
+ "bddl_file_name": task_bddl_file,
+ "camera_heights": self.observation_height,
+ "camera_widths": self.observation_width,
+ }
+ env = OffScreenRenderEnv(**env_args)
+ env.reset()
+ return env
+
+ def _format_raw_obs(self, raw_obs: dict[str, Any]) -> dict[str, Any]:
+ images = {}
+ for camera_name in self.camera_name:
+ image = raw_obs[camera_name]
+ image = image[::-1, ::-1] # rotate 180 degrees
+ images[self.camera_name_mapping[camera_name]] = image
+ state = np.concatenate(
+ (
+ raw_obs["robot0_eef_pos"],
+ quat2axisangle(raw_obs["robot0_eef_quat"]),
+ raw_obs["robot0_gripper_qpos"],
+ )
+ )
+ agent_pos = state
+ if self.obs_type == "pixels":
+ return {"pixels": images.copy()}
+ if self.obs_type == "pixels_agent_pos":
+ return {
+ "pixels": images.copy(),
+ "agent_pos": agent_pos,
+ }
+ raise NotImplementedError(
+ f"The observation type '{self.obs_type}' is not supported in LiberoEnv. "
+ "Please switch to an image-based obs_type (e.g. 'pixels', 'pixels_agent_pos')."
+ )
+
+ def reset(self, seed=None, **kwargs):
+ super().reset(seed=seed)
+ self._env.seed(seed)
+ if self.init_states and self._init_states is not None:
+ self._env.set_init_state(self._init_states[self._init_state_id])
+ raw_obs = self._env.reset()
+
+ # After reset, objects may be unstable (slightly floating, intersecting, etc.).
+ # Step the simulator with a no-op action for a few frames so everything settles.
+ # Increasing this value can improve determinism and reproducibility across resets.
+ for _ in range(self.num_steps_wait):
+ raw_obs, _, _, _ = self._env.step(get_libero_dummy_action())
+ observation = self._format_raw_obs(raw_obs)
+ info = {"is_success": False}
+ return observation, info
+
+ def step(self, action: np.ndarray) -> tuple[dict[str, Any], float, bool, bool, dict[str, Any]]:
+ if action.ndim != 1:
+ raise ValueError(
+ f"Expected action to be 1-D (shape (action_dim,)), "
+ f"but got shape {action.shape} with ndim={action.ndim}"
+ )
+ raw_obs, reward, done, info = self._env.step(action)
+
+ is_success = self._env.check_success()
+ terminated = done or is_success
+ info["is_success"] = is_success
+
+ observation = self._format_raw_obs(raw_obs)
+ if done:
+ self.reset()
+ info.update(
+ {
+ "task": self.task,
+ "task_id": self.task_id,
+ "done": done,
+ "is_success": is_success,
+ }
+ )
+ truncated = False
+ return observation, reward, terminated, truncated, info
+
+ def close(self):
+ self._env.close()
+
+
+def _make_env_fns(
+ *,
+ suite,
+ suite_name: str,
+ task_id: int,
+ n_envs: int,
+ camera_names: list[str],
+ init_states: bool,
+ gym_kwargs: Mapping[str, Any],
+) -> list[Callable[[], LiberoEnv]]:
+ """Build n_envs factory callables for a single (suite, task_id)."""
+
+ def _make_env(episode_index: int, **kwargs) -> LiberoEnv:
+ local_kwargs = dict(kwargs)
+ return LiberoEnv(
+ task_suite=suite,
+ task_id=task_id,
+ task_suite_name=suite_name,
+ camera_name=camera_names,
+ init_states=init_states,
+ episode_index=episode_index,
+ **local_kwargs,
+ )
+
+ fns: list[Callable[[], LiberoEnv]] = []
+ for episode_index in range(n_envs):
+ fns.append(partial(_make_env, episode_index, **gym_kwargs))
+ return fns
+
+
+# ---- Main API ----------------------------------------------------------------
+
+
+def create_libero_envs(
+ task: str,
+ n_envs: int,
+ gym_kwargs: dict[str, Any] | None = None,
+ camera_name: str | Sequence[str] = "agentview_image,robot0_eye_in_hand_image",
+ init_states: bool = True,
+ env_cls: Callable[[Sequence[Callable[[], Any]]], Any] | None = None,
+) -> dict[str, dict[int, Any]]:
+ """
+ Create vectorized LIBERO environments with a consistent return shape.
+
+ Returns:
+ dict[suite_name][task_id] -> vec_env (env_cls([...]) with exactly n_envs factories)
+ Notes:
+ - n_envs is the number of rollouts *per task* (episode_index = 0..n_envs-1).
+ - `task` can be a single suite or a comma-separated list of suites.
+ - You may pass `task_ids` (list[int]) inside `gym_kwargs` to restrict tasks per suite.
+ """
+ if env_cls is None or not callable(env_cls):
+ raise ValueError("env_cls must be a callable that wraps a list of environment factory callables.")
+ if not isinstance(n_envs, int) or n_envs <= 0:
+ raise ValueError(f"n_envs must be a positive int; got {n_envs}.")
+
+ gym_kwargs = dict(gym_kwargs or {})
+ task_ids_filter = gym_kwargs.pop("task_ids", None) # optional: limit to specific tasks
+
+ camera_names = _parse_camera_names(camera_name)
+ suite_names = [s.strip() for s in str(task).split(",") if s.strip()]
+ if not suite_names:
+ raise ValueError("`task` must contain at least one LIBERO suite name.")
+
+ print(
+ f"Creating LIBERO envs | suites={suite_names} | n_envs(per task)={n_envs} | init_states={init_states}"
+ )
+ if task_ids_filter is not None:
+ print(f"Restricting to task_ids={task_ids_filter}")
+
+ out: dict[str, dict[int, Any]] = defaultdict(dict)
+
+ for suite_name in suite_names:
+ suite = _get_suite(suite_name)
+ total = len(suite.tasks)
+ selected = _select_task_ids(total, task_ids_filter)
+
+ if not selected:
+ raise ValueError(f"No tasks selected for suite '{suite_name}' (available: {total}).")
+
+ for tid in selected:
+ fns = _make_env_fns(
+ suite=suite,
+ suite_name=suite_name,
+ task_id=tid,
+ n_envs=n_envs,
+ camera_names=camera_names,
+ init_states=init_states,
+ gym_kwargs=gym_kwargs,
+ )
+ out[suite_name][tid] = env_cls(fns)
+ print(f"Built vec env | suite={suite_name} | task_id={tid} | n_envs={n_envs}")
+
+ # return plain dicts for predictability
+ return {suite: dict(task_map) for suite, task_map in out.items()}
diff --git a/src/lerobot/envs/utils.py b/src/lerobot/envs/utils.py
index b4f65ee9c..f0aa0b5c6 100644
--- a/src/lerobot/envs/utils.py
+++ b/src/lerobot/envs/utils.py
@@ -14,6 +14,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import warnings
+from collections.abc import Mapping, Sequence
+from functools import singledispatch
from typing import Any
import einops
@@ -154,3 +156,41 @@ def add_envs_task(env: gym.vector.VectorEnv, observation: dict[str, Any]) -> dic
num_envs = observation[list(observation.keys())[0]].shape[0]
observation["task"] = ["" for _ in range(num_envs)]
return observation
+
+
+def _close_single_env(env: Any) -> None:
+ try:
+ env.close()
+ except Exception as exc:
+ print(f"Exception while closing env {env}: {exc}")
+
+
+@singledispatch
+def close_envs(obj: Any) -> None:
+ """Default: raise if the type is not recognized."""
+ raise NotImplementedError(f"close_envs not implemented for type {type(obj).__name__}")
+
+
+@close_envs.register
+def _(env: Mapping) -> None:
+ for v in env.values():
+ if isinstance(v, Mapping):
+ close_envs(v)
+ elif hasattr(v, "close"):
+ _close_single_env(v)
+
+
+@close_envs.register
+def _(envs: Sequence) -> None:
+ if isinstance(envs, (str, bytes)):
+ return
+ for v in envs:
+ if isinstance(v, Mapping) or isinstance(v, Sequence) and not isinstance(v, (str, bytes)):
+ close_envs(v)
+ elif hasattr(v, "close"):
+ _close_single_env(v)
+
+
+@close_envs.register
+def _(env: gym.Env) -> None:
+ _close_single_env(env)
diff --git a/src/lerobot/robots/stretch3/README.md b/src/lerobot/robots/stretch3/README.md
index 724732286..027f12d65 100644
--- a/src/lerobot/robots/stretch3/README.md
+++ b/src/lerobot/robots/stretch3/README.md
@@ -170,8 +170,4 @@ python lerobot/scripts/control_robot.py \
--control.episode=0
```
-Follow [previous tutorial](https://github.com/huggingface/lerobot/blob/main/examples/7_get_started_with_real_robot.md#4-train-a-policy-on-your-data) to train a policy on your data and run inference on your robot. You will need to adapt the code for Stretch.
-
-> TODO(rcadene, aliberts): Add already setup environment and policy yaml configuration files
-
If you need help, please reach out on Discord in the channel `#stretch3-mobile-arm`.
diff --git a/src/lerobot/robots/viperx/README.md b/src/lerobot/robots/viperx/README.md
index 5b57d61f5..f6386215a 100644
--- a/src/lerobot/robots/viperx/README.md
+++ b/src/lerobot/robots/viperx/README.md
@@ -193,6 +193,4 @@ As you can see, it's almost the same command as previously used to record your t
## More
-Follow this [previous tutorial](https://github.com/huggingface/lerobot/blob/main/examples/7_get_started_with_real_robot.md#4-train-a-policy-on-your-data) for a more in-depth explanation.
-
If you have any question or need help, please reach out on Discord in the channel `#aloha-arm`.
diff --git a/src/lerobot/scripts/eval.py b/src/lerobot/scripts/eval.py
index bf398a0a9..ca900f8df 100644
--- a/src/lerobot/scripts/eval.py
+++ b/src/lerobot/scripts/eval.py
@@ -46,17 +46,20 @@ Note that in both examples, the repo/folder should contain at least `config.json
You can learn about the CLI options for this script in the `EvalPipelineConfig` in lerobot/configs/eval.py
"""
+import concurrent.futures as cf
import json
import logging
import threading
import time
+from collections import defaultdict
from collections.abc import Callable
from contextlib import nullcontext
from copy import deepcopy
from dataclasses import asdict
+from functools import partial
from pathlib import Path
from pprint import pformat
-from typing import Any
+from typing import Any, TypedDict
import einops
import gymnasium as gym
@@ -69,7 +72,12 @@ from tqdm import trange
from lerobot.configs import parser
from lerobot.configs.eval import EvalPipelineConfig
from lerobot.envs.factory import make_env
-from lerobot.envs.utils import add_envs_task, check_env_attributes_and_types, preprocess_observation
+from lerobot.envs.utils import (
+ add_envs_task,
+ check_env_attributes_and_types,
+ close_envs,
+ preprocess_observation,
+)
from lerobot.policies.factory import make_policy, make_pre_post_processors
from lerobot.policies.pretrained import PreTrainedPolicy
from lerobot.processor import PolicyAction, PolicyProcessorPipeline
@@ -147,7 +155,7 @@ def rollout(
leave=False,
)
check_env_attributes_and_types(env)
- while not np.all(done):
+ while not np.all(done) and step < max_steps:
# Numpy array to tensor and changing dictionary keys to LeRobot policy format.
observation = preprocess_observation(observation)
if return_observations:
@@ -178,7 +186,12 @@ def rollout(
successes = [False] * env.num_envs
# Keep track of which environments are done so far.
+ # Mark the episode as done if we reach the maximum step limit.
+ # This ensures that the rollout always terminates cleanly at `max_steps`,
+ # and allows logging/saving (e.g., videos) to be triggered consistently.
done = terminated | truncated | done
+ if step + 1 == max_steps:
+ done = np.ones_like(done, dtype=bool)
all_actions.append(torch.from_numpy(action_numpy))
all_rewards.append(torch.from_numpy(reward))
@@ -474,7 +487,7 @@ def eval_main(cfg: EvalPipelineConfig):
logging.info(colored("Output dir:", "yellow", attrs=["bold"]) + f" {cfg.output_dir}")
logging.info("Making environment.")
- env = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
+ envs = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
logging.info("Making policy.")
@@ -490,10 +503,9 @@ def eval_main(cfg: EvalPipelineConfig):
# The inference device is automatically set to match the detected hardware, overriding any previous device settings from training to ensure compatibility.
preprocessor_overrides={"device_processor": {"device": str(policy.config.device)}},
)
-
with torch.no_grad(), torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext():
- info = eval_policy(
- env=env,
+ info = eval_policy_all(
+ envs=envs,
policy=policy,
preprocessor=preprocessor,
postprocessor=postprocessor,
@@ -501,18 +513,237 @@ def eval_main(cfg: EvalPipelineConfig):
max_episodes_rendered=10,
videos_dir=Path(cfg.output_dir) / "videos",
start_seed=cfg.seed,
+ max_parallel_tasks=cfg.env.max_parallel_tasks,
)
- print(info["aggregated"])
+ print("Overall Aggregated Metrics:")
+ print(info["overall"])
+
+ # Print per-suite stats
+ for task_group, task_group_info in info.items():
+ print(f"\nAggregated Metrics for {task_group}:")
+ print(task_group_info)
+ # Close all vec envs
+ close_envs(envs)
# Save info
with open(Path(cfg.output_dir) / "eval_info.json", "w") as f:
json.dump(info, f, indent=2)
- env.close()
-
logging.info("End of eval")
+# ---- typed payload returned by one task eval ----
+class TaskMetrics(TypedDict):
+ sum_rewards: list[float]
+ max_rewards: list[float]
+ successes: list[bool]
+ video_paths: list[str]
+
+
+ACC_KEYS = ("sum_rewards", "max_rewards", "successes", "video_paths")
+
+
+def eval_one(
+ env: gym.vector.VectorEnv,
+ *,
+ policy: PreTrainedPolicy,
+ preprocessor: PolicyProcessorPipeline[dict[str, Any], dict[str, Any]],
+ postprocessor: PolicyProcessorPipeline[PolicyAction, PolicyAction],
+ n_episodes: int,
+ max_episodes_rendered: int,
+ videos_dir: Path | None,
+ return_episode_data: bool,
+ start_seed: int | None,
+) -> TaskMetrics:
+ """Evaluates one task_id of one suite using the provided vec env."""
+
+ task_videos_dir = videos_dir
+
+ task_result = eval_policy(
+ env=env,
+ policy=policy,
+ preprocessor=preprocessor,
+ postprocessor=postprocessor,
+ n_episodes=n_episodes,
+ max_episodes_rendered=max_episodes_rendered,
+ videos_dir=task_videos_dir,
+ return_episode_data=return_episode_data,
+ start_seed=start_seed,
+ )
+
+ per_episode = task_result["per_episode"]
+ return TaskMetrics(
+ sum_rewards=[ep["sum_reward"] for ep in per_episode],
+ max_rewards=[ep["max_reward"] for ep in per_episode],
+ successes=[ep["success"] for ep in per_episode],
+ video_paths=task_result.get("video_paths", []),
+ )
+
+
+def run_one(
+ task_group: str,
+ task_id: int,
+ env,
+ *,
+ policy,
+ preprocessor,
+ postprocessor,
+ n_episodes: int,
+ max_episodes_rendered: int,
+ videos_dir: Path | None,
+ return_episode_data: bool,
+ start_seed: int | None,
+):
+ """
+ Run eval_one for a single (task_group, task_id, env).
+ Returns (task_group, task_id, task_metrics_dict).
+ This function is intentionally module-level to make it easy to test.
+ """
+ task_videos_dir = None
+ if videos_dir is not None:
+ task_videos_dir = videos_dir / f"{task_group}_{task_id}"
+ task_videos_dir.mkdir(parents=True, exist_ok=True)
+
+ # Call the existing eval_one (assumed to return TaskMetrics-like dict)
+ metrics = eval_one(
+ env,
+ policy=policy,
+ preprocessor=preprocessor,
+ postprocessor=postprocessor,
+ n_episodes=n_episodes,
+ max_episodes_rendered=max_episodes_rendered,
+ videos_dir=task_videos_dir,
+ return_episode_data=return_episode_data,
+ start_seed=start_seed,
+ )
+ # ensure we always provide video_paths key to simplify accumulation
+ if max_episodes_rendered > 0:
+ metrics.setdefault("video_paths", [])
+ return task_group, task_id, metrics
+
+
+def eval_policy_all(
+ envs: dict[str, dict[int, gym.vector.VectorEnv]],
+ policy,
+ preprocessor: PolicyProcessorPipeline[dict[str, Any], dict[str, Any]],
+ postprocessor: PolicyProcessorPipeline[PolicyAction, PolicyAction],
+ n_episodes: int,
+ *,
+ max_episodes_rendered: int = 0,
+ videos_dir: Path | None = None,
+ return_episode_data: bool = False,
+ start_seed: int | None = None,
+ max_parallel_tasks: int = 1,
+) -> dict:
+ """
+ Evaluate a nested `envs` dict: {task_group: {task_id: vec_env}}.
+ This implementation flattens tasks, runs them sequentially or via ThreadPoolExecutor,
+ accumulates per-group and overall statistics, and returns the same aggregate metrics
+ schema as the single-env evaluator (avg_sum_reward / avg_max_reward / pc_success / timings)
+ plus per-task infos.
+ """
+ start_t = time.time()
+
+ # Flatten envs into list of (task_group, task_id, env)
+ tasks = [(tg, tid, vec) for tg, group in envs.items() for tid, vec in group.items()]
+
+ # accumulators: track metrics at both per-group level and across all groups
+ group_acc: dict[str, dict[str, list]] = defaultdict(lambda: {k: [] for k in ACC_KEYS})
+ overall: dict[str, list] = {k: [] for k in ACC_KEYS}
+ per_task_infos: list[dict] = []
+
+ # small inline helper to accumulate one task's metrics into accumulators
+ def _accumulate_to(group: str, metrics: dict):
+ # metrics expected to contain 'sum_rewards', 'max_rewards', 'successes', optionally 'video_paths'
+ # but eval_one may store per-episode lists; we assume metrics uses scalars averaged per task as before.
+ # To be robust, accept scalars or lists.
+ def _append(key, value):
+ if value is None:
+ return
+ if isinstance(value, list):
+ group_acc[group][key].extend(value)
+ overall[key].extend(value)
+ else:
+ group_acc[group][key].append(value)
+ overall[key].append(value)
+
+ _append("sum_rewards", metrics.get("sum_rewards"))
+ _append("max_rewards", metrics.get("max_rewards"))
+ _append("successes", metrics.get("successes"))
+ # video_paths is list-like
+ paths = metrics.get("video_paths", [])
+ if paths:
+ group_acc[group]["video_paths"].extend(paths)
+ overall["video_paths"].extend(paths)
+
+ # Choose runner (sequential vs threaded)
+ task_runner = partial(
+ run_one,
+ policy=policy,
+ preprocessor=preprocessor,
+ postprocessor=postprocessor,
+ n_episodes=n_episodes,
+ max_episodes_rendered=max_episodes_rendered,
+ videos_dir=videos_dir,
+ return_episode_data=return_episode_data,
+ start_seed=start_seed,
+ )
+
+ if max_parallel_tasks <= 1:
+ # sequential path (single accumulator path on the main thread)
+ # NOTE: keeping a single-threaded accumulator avoids concurrent list appends or locks
+ for task_group, task_id, env in tasks:
+ tg, tid, metrics = task_runner(task_group, task_id, env)
+ _accumulate_to(tg, metrics)
+ per_task_infos.append({"task_group": tg, "task_id": tid, "metrics": metrics})
+ else:
+ # threaded path: submit all tasks, consume completions on main thread and accumulate there
+ with cf.ThreadPoolExecutor(max_workers=max_parallel_tasks) as executor:
+ fut2meta = {}
+ for task_group, task_id, env in tasks:
+ fut = executor.submit(task_runner, task_group, task_id, env)
+ fut2meta[fut] = (task_group, task_id)
+ for fut in cf.as_completed(fut2meta):
+ tg, tid, metrics = fut.result()
+ _accumulate_to(tg, metrics)
+ per_task_infos.append({"task_group": tg, "task_id": tid, "metrics": metrics})
+
+ # compute aggregated metrics helper (robust to lists/scalars)
+ def _agg_from_list(xs):
+ if not xs:
+ return float("nan")
+ arr = np.array(xs, dtype=float)
+ return float(np.nanmean(arr))
+
+ # compute per-group aggregates
+ groups_aggregated = {}
+ for group, acc in group_acc.items():
+ groups_aggregated[group] = {
+ "avg_sum_reward": _agg_from_list(acc["sum_rewards"]),
+ "avg_max_reward": _agg_from_list(acc["max_rewards"]),
+ "pc_success": _agg_from_list(acc["successes"]) * 100 if acc["successes"] else float("nan"),
+ "n_episodes": len(acc["sum_rewards"]),
+ "video_paths": list(acc["video_paths"]),
+ }
+
+ # overall aggregates
+ overall_agg = {
+ "avg_sum_reward": _agg_from_list(overall["sum_rewards"]),
+ "avg_max_reward": _agg_from_list(overall["max_rewards"]),
+ "pc_success": _agg_from_list(overall["successes"]) * 100 if overall["successes"] else float("nan"),
+ "n_episodes": len(overall["sum_rewards"]),
+ "eval_s": time.time() - start_t,
+ "eval_ep_s": (time.time() - start_t) / max(1, len(overall["sum_rewards"])),
+ "video_paths": list(overall["video_paths"]),
+ }
+
+ return {
+ "per_task": per_task_infos,
+ "per_group": groups_aggregated,
+ "overall": overall_agg,
+ }
+
+
def main():
init_logging()
eval_main()
diff --git a/src/lerobot/scripts/train.py b/src/lerobot/scripts/train.py
index 485fc9275..21da62bbb 100644
--- a/src/lerobot/scripts/train.py
+++ b/src/lerobot/scripts/train.py
@@ -30,11 +30,12 @@ from lerobot.datasets.factory import make_dataset
from lerobot.datasets.sampler import EpisodeAwareSampler
from lerobot.datasets.utils import cycle
from lerobot.envs.factory import make_env
+from lerobot.envs.utils import close_envs
from lerobot.optim.factory import make_optimizer_and_scheduler
from lerobot.policies.factory import make_policy, make_pre_post_processors
from lerobot.policies.pretrained import PreTrainedPolicy
from lerobot.policies.utils import get_device_from_parameters
-from lerobot.scripts.eval import eval_policy
+from lerobot.scripts.eval import eval_policy_all
from lerobot.utils.logging_utils import AverageMeter, MetricsTracker
from lerobot.utils.random_utils import set_seed
from lerobot.utils.train_utils import (
@@ -183,6 +184,9 @@ def train(cfg: TrainPipelineConfig):
# Only provide dataset_stats when not resuming from saved processor state
processor_kwargs["dataset_stats"] = dataset.meta.stats
+ if cfg.policy.pretrained_path is not None:
+ processor_kwargs["preprocessor_overrides"] = {"device_processor": {"device": device.type}}
+
preprocessor, postprocessor = make_pre_post_processors(
policy_cfg=cfg.policy, pretrained_path=cfg.policy.pretrained_path, **processor_kwargs
)
@@ -299,8 +303,8 @@ def train(cfg: TrainPipelineConfig):
torch.no_grad(),
torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext(),
):
- eval_info = eval_policy(
- env=eval_env,
+ eval_info = eval_policy_all(
+ envs=eval_env, # dict[suite][task_id] -> vec_env
policy=policy,
preprocessor=preprocessor,
postprocessor=postprocessor,
@@ -308,8 +312,16 @@ def train(cfg: TrainPipelineConfig):
videos_dir=cfg.output_dir / "eval" / f"videos_step_{step_id}",
max_episodes_rendered=4,
start_seed=cfg.seed,
+ max_parallel_tasks=cfg.env.max_parallel_tasks,
)
+ # overall metrics (suite-agnostic)
+ aggregated = eval_info["overall"]
+ # optional: per-suite logging
+ for suite, suite_info in eval_info.items():
+ logging.info("Suite %s aggregated: %s", suite, suite_info)
+
+ # meters/tracker
eval_metrics = {
"avg_sum_reward": AverageMeter("∑rwrd", ":.3f"),
"pc_success": AverageMeter("success", ":.1f"),
@@ -318,17 +330,16 @@ def train(cfg: TrainPipelineConfig):
eval_tracker = MetricsTracker(
cfg.batch_size, dataset.num_frames, dataset.num_episodes, eval_metrics, initial_step=step
)
- eval_tracker.eval_s = eval_info["aggregated"].pop("eval_s")
- eval_tracker.avg_sum_reward = eval_info["aggregated"].pop("avg_sum_reward")
- eval_tracker.pc_success = eval_info["aggregated"].pop("pc_success")
- logging.info(eval_tracker)
+ eval_tracker.eval_s = aggregated.pop("eval_s")
+ eval_tracker.avg_sum_reward = aggregated.pop("avg_sum_reward")
+ eval_tracker.pc_success = aggregated.pop("pc_success")
if wandb_logger:
wandb_log_dict = {**eval_tracker.to_dict(), **eval_info}
wandb_logger.log_dict(wandb_log_dict, step, mode="eval")
- wandb_logger.log_video(eval_info["video_paths"][0], step, mode="eval")
+ wandb_logger.log_video(eval_info["overall"]["video_paths"][0], step, mode="eval")
if eval_env:
- eval_env.close()
+ close_envs(eval_env)
logging.info("End of training")
if cfg.policy.push_to_hub:
diff --git a/tests/envs/test_envs.py b/tests/envs/test_envs.py
index 140e9dfb9..51ea564e5 100644
--- a/tests/envs/test_envs.py
+++ b/tests/envs/test_envs.py
@@ -46,7 +46,10 @@ def test_env(env_name, env_task, obs_type):
@require_env
def test_factory(env_name):
cfg = make_env_config(env_name)
- env = make_env(cfg, n_envs=1)
+ envs = make_env(cfg, n_envs=1)
+ suite_name = next(iter(envs))
+ task_id = next(iter(envs[suite_name]))
+ env = envs[suite_name][task_id]
obs, _ = env.reset()
obs = preprocess_observation(obs)
diff --git a/tests/examples/test_examples.py b/tests/examples/test_examples.py
deleted file mode 100644
index aabec69a6..000000000
--- a/tests/examples/test_examples.py
+++ /dev/null
@@ -1,147 +0,0 @@
-#!/usr/bin/env python
-
-# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import io
-import subprocess
-import sys
-from pathlib import Path
-
-import pytest
-
-from tests.fixtures.constants import DUMMY_REPO_ID
-from tests.utils import require_package
-
-
-def _find_and_replace(text: str, finds_and_replaces: list[tuple[str, str]]) -> str:
- for f, r in finds_and_replaces:
- assert f in text
- text = text.replace(f, r)
- return text
-
-
-# TODO(aliberts): Remove usage of subprocess calls and patch code with fixtures
-def _run_script(path):
- subprocess.run([sys.executable, path], check=True)
-
-
-def _read_file(path):
- with open(path) as file:
- return file.read()
-
-
-@pytest.mark.skip("TODO Fix and remove subprocess / excec calls")
-def test_example_1(tmp_path, lerobot_dataset_factory):
- _ = lerobot_dataset_factory(root=tmp_path, repo_id=DUMMY_REPO_ID)
- path = "examples/1_load_lerobot_dataset.py"
- file_contents = _read_file(path)
- file_contents = _find_and_replace(
- file_contents,
- [
- ('repo_id = "lerobot/pusht"', f'repo_id = "{DUMMY_REPO_ID}"'),
- (
- "LeRobotDataset(repo_id",
- f"LeRobotDataset(repo_id, root='{str(tmp_path)}'",
- ),
- ],
- )
- exec(file_contents, {})
- assert Path("outputs/examples/1_load_lerobot_dataset/episode_0.mp4").exists()
-
-
-@pytest.mark.skip("TODO Fix and remove subprocess / excec calls")
-@require_package("gym_pusht")
-def test_examples_basic2_basic3_advanced1():
- """
- Train a model with example 3, check the outputs.
- Evaluate the trained model with example 2, check the outputs.
- Calculate the validation loss with advanced example 1, check the outputs.
- """
-
- ### Test example 3
- file_contents = _read_file("examples/3_train_policy.py")
-
- # Do fewer steps, use smaller batch, use CPU, and don't complicate things with dataloader workers.
- file_contents = _find_and_replace(
- file_contents,
- [
- ("training_steps = 5000", "training_steps = 1"),
- ("num_workers=4", "num_workers=0"),
- ('device = torch.device("cuda")', 'device = torch.device("cpu")'),
- ("batch_size=64", "batch_size=1"),
- ],
- )
-
- # Pass empty globals to allow dictionary comprehension https://stackoverflow.com/a/32897127/4391249.
- exec(file_contents, {})
-
- for file_name in ["model.safetensors", "config.json"]:
- assert Path(f"outputs/train/example_pusht_diffusion/{file_name}").exists()
-
- ### Test example 2
- file_contents = _read_file("examples/2_evaluate_pretrained_policy.py")
-
- # Do fewer evals, use CPU, and use the local model.
- file_contents = _find_and_replace(
- file_contents,
- [
- (
- 'pretrained_policy_path = Path(snapshot_download("lerobot/diffusion_pusht"))',
- "",
- ),
- (
- '# pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")',
- 'pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")',
- ),
- ('device = torch.device("cuda")', 'device = torch.device("cpu")'),
- ("step += 1", "break"),
- ],
- )
-
- exec(file_contents, {})
-
- assert Path("outputs/eval/example_pusht_diffusion/rollout.mp4").exists()
-
- ## Test example 4
- file_contents = _read_file("examples/advanced/2_calculate_validation_loss.py")
-
- # Run on a single example from the last episode, use CPU, and use the local model.
- file_contents = _find_and_replace(
- file_contents,
- [
- (
- 'pretrained_policy_path = Path(snapshot_download("lerobot/diffusion_pusht"))',
- "",
- ),
- (
- '# pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")',
- 'pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")',
- ),
- ("train_episodes = episodes[:num_train_episodes]", "train_episodes = [0]"),
- ("val_episodes = episodes[num_train_episodes:]", "val_episodes = [1]"),
- ("num_workers=4", "num_workers=0"),
- ('device = torch.device("cuda")', 'device = torch.device("cpu")'),
- ("batch_size=64", "batch_size=1"),
- ],
- )
-
- # Capture the output of the script
- output_buffer = io.StringIO()
- sys.stdout = output_buffer
- exec(file_contents, {})
- printed_output = output_buffer.getvalue()
- # Restore stdout to its original state
- sys.stdout = sys.__stdout__
- assert "Average loss on validation set" in printed_output
diff --git a/tests/policies/test_policies.py b/tests/policies/test_policies.py
index ef09bcd22..28c395bfc 100644
--- a/tests/policies/test_policies.py
+++ b/tests/policies/test_policies.py
@@ -159,7 +159,7 @@ def test_policy(ds_repo_id, env_name, env_kwargs, policy_name, policy_kwargs):
assert isinstance(policy, PreTrainedPolicy)
# Check that we run select_actions and get the appropriate output.
- env = make_env(train_cfg.env, n_envs=2)
+ envs = make_env(train_cfg.env, n_envs=2)
dataloader = torch.utils.data.DataLoader(
dataset,
@@ -188,6 +188,12 @@ def test_policy(ds_repo_id, env_name, env_kwargs, policy_name, policy_kwargs):
# reset the policy and environment
policy.reset()
+ # For testing purposes, we only need a single environment instance.
+ # So here we unwrap the first suite_name and first task_id to grab
+ # the actual env object (SyncVectorEnv) that exposes `.reset()`.
+ suite_name = next(iter(envs))
+ task_id = next(iter(envs[suite_name]))
+ env = envs[suite_name][task_id]
observation, _ = env.reset(seed=train_cfg.seed)
# apply transform to normalize the observations
### Step 1: Choose the platform
diff --git a/examples/2_evaluate_pretrained_policy.py b/examples/2_evaluate_pretrained_policy.py
deleted file mode 100644
index c0c7845e8..000000000
--- a/examples/2_evaluate_pretrained_policy.py
+++ /dev/null
@@ -1,139 +0,0 @@
-# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-This script demonstrates how to evaluate a pretrained policy from the HuggingFace Hub or from your local
-training outputs directory. In the latter case, you might want to run examples/3_train_policy.py first.
-
-It requires the installation of the 'gym_pusht' simulation environment. Install it by running:
-```bash
-pip install -e ".[pusht]"
-```
-"""
-
-from pathlib import Path
-
-import gym_pusht # noqa: F401
-import gymnasium as gym
-import imageio
-import numpy
-import torch
-
-from lerobot.policies.diffusion.modeling_diffusion import DiffusionPolicy
-
-# Create a directory to store the video of the evaluation
-output_directory = Path("outputs/eval/example_pusht_diffusion")
-output_directory.mkdir(parents=True, exist_ok=True)
-
-# Select your device
-device = "cuda"
-
-# Provide the [hugging face repo id](https://huggingface.co/lerobot/diffusion_pusht):
-pretrained_policy_path = "lerobot/diffusion_pusht"
-# OR a path to a local outputs/train folder.
-# pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")
-
-policy = DiffusionPolicy.from_pretrained(pretrained_policy_path)
-
-# Initialize evaluation environment to render two observation types:
-# an image of the scene and state/position of the agent. The environment
-# also automatically stops running after 300 interactions/steps.
-env = gym.make(
- "gym_pusht/PushT-v0",
- obs_type="pixels_agent_pos",
- max_episode_steps=300,
-)
-
-# We can verify that the shapes of the features expected by the policy match the ones from the observations
-# produced by the environment
-print(policy.config.input_features)
-print(env.observation_space)
-
-# Similarly, we can check that the actions produced by the policy will match the actions expected by the
-# environment
-print(policy.config.output_features)
-print(env.action_space)
-
-# Reset the policy and environments to prepare for rollout
-policy.reset()
-numpy_observation, info = env.reset(seed=42)
-
-# Prepare to collect every rewards and all the frames of the episode,
-# from initial state to final state.
-rewards = []
-frames = []
-
-# Render frame of the initial state
-frames.append(env.render())
-
-step = 0
-done = False
-while not done:
- # Prepare observation for the policy running in Pytorch
- state = torch.from_numpy(numpy_observation["agent_pos"])
- image = torch.from_numpy(numpy_observation["pixels"])
-
- # Convert to float32 with image from channel first in [0,255]
- # to channel last in [0,1]
- state = state.to(torch.float32)
- image = image.to(torch.float32) / 255
- image = image.permute(2, 0, 1)
-
- # Send data tensors from CPU to GPU
- state = state.to(device, non_blocking=True)
- image = image.to(device, non_blocking=True)
-
- # Add extra (empty) batch dimension, required to forward the policy
- state = state.unsqueeze(0)
- image = image.unsqueeze(0)
-
- # Create the policy input dictionary
- observation = {
- "observation.state": state,
- "observation.image": image,
- }
-
- # Predict the next action with respect to the current observation
- with torch.inference_mode():
- action = policy.select_action(observation)
-
- # Prepare the action for the environment
- numpy_action = action.squeeze(0).to("cpu").numpy()
-
- # Step through the environment and receive a new observation
- numpy_observation, reward, terminated, truncated, info = env.step(numpy_action)
- print(f"{step=} {reward=} {terminated=}")
-
- # Keep track of all the rewards and frames
- rewards.append(reward)
- frames.append(env.render())
-
- # The rollout is considered done when the success state is reached (i.e. terminated is True),
- # or the maximum number of iterations is reached (i.e. truncated is True)
- done = terminated | truncated | done
- step += 1
-
-if terminated:
- print("Success!")
-else:
- print("Failure!")
-
-# Get the speed of environment (i.e. its number of frames per second).
-fps = env.metadata["render_fps"]
-
-# Encode all frames into a mp4 video.
-video_path = output_directory / "rollout.mp4"
-imageio.mimsave(str(video_path), numpy.stack(frames), fps=fps)
-
-print(f"Video of the evaluation is available in '{video_path}'.")
diff --git a/examples/4_train_policy_with_script.md b/examples/4_train_policy_with_script.md
deleted file mode 100644
index ffa7de66e..000000000
--- a/examples/4_train_policy_with_script.md
+++ /dev/null
@@ -1,311 +0,0 @@
-This tutorial will explain the training script, how to use it, and particularly how to configure everything needed for the training run.
-
-> **Note:** The following assumes you're running these commands on a machine equipped with a cuda GPU. If you don't have one (or if you're using a Mac), you can add `--policy.device=cpu` (`--policy.device=mps` respectively). However, be advised that the code executes much slower on cpu.
-
-## The training script
-
-LeRobot offers a training script at [`lerobot/scripts/train.py`](../src/lerobot/scripts/train.py). At a high level it does the following:
-
-- Initialize/load a configuration for the following steps using.
-- Instantiates a dataset.
-- (Optional) Instantiates a simulation environment corresponding to that dataset.
-- Instantiates a policy.
-- Runs a standard training loop with forward pass, backward pass, optimization step, and occasional logging, evaluation (of the policy on the environment), and checkpointing.
-
-## Overview of the configuration system
-
-In the training script, the main function `train` expects a `TrainPipelineConfig` object:
-
-
-```python
-# train.py
-@parser.wrap()
-def train(cfg: TrainPipelineConfig):
-```
-
-
-You can inspect the `TrainPipelineConfig` defined in [`lerobot/configs/train.py`](../src/lerobot/configs/train.py) (which is heavily commented and meant to be a reference to understand any option)
-
-When running the script, inputs for the command line are parsed thanks to the `@parser.wrap()` decorator and an instance of this class is automatically generated. Under the hood, this is done with [Draccus](https://github.com/dlwh/draccus) which is a tool dedicated to this purpose. If you're familiar with Hydra, Draccus can similarly load configurations from config files (.json, .yaml) and also override their values through command line inputs. Unlike Hydra, these configurations are pre-defined in the code through dataclasses rather than being defined entirely in config files. This allows for more rigorous serialization/deserialization, typing, and to manipulate configuration as objects directly in the code and not as dictionaries or namespaces (which enables nice features in an IDE such as autocomplete, jump-to-def, etc.)
-
-Let's have a look at a simplified example. Amongst other attributes, the training config has the following attributes:
-
-
-```python
-@dataclass
-class TrainPipelineConfig:
- dataset: DatasetConfig
- env: envs.EnvConfig | None = None
- policy: PreTrainedConfig | None = None
-```
-
-
-in which `DatasetConfig` for example is defined as such:
-
-
-```python
-@dataclass
-class DatasetConfig:
- repo_id: str
- episodes: list[int] | None = None
- video_backend: str = "pyav"
-```
-
-
-This creates a hierarchical relationship where, for example assuming we have a `cfg` instance of `TrainPipelineConfig`, we can access the `repo_id` value with `cfg.dataset.repo_id`.
-From the command line, we can specify this value by using a very similar syntax `--dataset.repo_id=repo/id`.
-
-By default, every field takes its default value specified in the dataclass. If a field doesn't have a default value, it needs to be specified either from the command line or from a config file – which path is also given in the command line (more in this below). In the example above, the `dataset` field doesn't have a default value which means it must be specified.
-
-## Specifying values from the CLI
-
-Let's say that we want to train [Diffusion Policy](../src/lerobot/policies/diffusion) on the [pusht](https://huggingface.co/datasets/lerobot/pusht) dataset, using the [gym_pusht](https://github.com/huggingface/gym-pusht) environment for evaluation. The command to do so would look like this:
-
-```bash
-lerobot-train \
- --dataset.repo_id=lerobot/pusht \
- --policy.type=diffusion \
- --env.type=pusht
-```
-
-Let's break this down:
-
-- To specify the dataset, we just need to specify its `repo_id` on the hub which is the only required argument in the `DatasetConfig`. The rest of the fields have default values and in this case we are fine with those so we can just add the option `--dataset.repo_id=lerobot/pusht`.
-- To specify the policy, we can just select diffusion policy using `--policy` appended with `.type`. Here, `.type` is a special argument which allows us to select config classes inheriting from `draccus.ChoiceRegistry` and that have been decorated with the `register_subclass()` method. To have a better explanation of this feature, have a look at this [Draccus demo](https://github.com/dlwh/draccus?tab=readme-ov-file#more-flexible-configuration-with-choice-types). In our code, we use this mechanism mainly to select policies, environments, robots, and some other components like optimizers. The policies available to select are located in [lerobot/policies](../src/lerobot/policies)
-- Similarly, we select the environment with `--env.type=pusht`. The different environment configs are available in [`lerobot/envs/configs.py`](../src/lerobot/envs/configs.py)
-
-Let's see another example. Let's say you've been training [ACT](../src/lerobot/policies/act) on [lerobot/aloha_sim_insertion_human](https://huggingface.co/datasets/lerobot/aloha_sim_insertion_human) using the [gym-aloha](https://github.com/huggingface/gym-aloha) environment for evaluation with:
-
-```bash
-lerobot-train \
- --policy.type=act \
- --dataset.repo_id=lerobot/aloha_sim_insertion_human \
- --env.type=aloha \
- --output_dir=outputs/train/act_aloha_insertion
-```
-
-> Notice we added `--output_dir` to explicitly tell where to write outputs from this run (checkpoints, training state, configs etc.). This is not mandatory and if you don't specify it, a default directory will be created from the current date and time, env.type and policy.type. This will typically look like `outputs/train/2025-01-24/16-10-05_aloha_act`.
-
-We now want to train a different policy for aloha on another task. We'll change the dataset and use [lerobot/aloha_sim_transfer_cube_human](https://huggingface.co/datasets/lerobot/aloha_sim_transfer_cube_human) instead. Of course, we also need to change the task of the environment as well to match this other task.
-Looking at the [`AlohaEnv`](../src/lerobot/envs/configs.py) config, the task is `"AlohaInsertion-v0"` by default, which corresponds to the task we trained on in the command above. The [gym-aloha](https://github.com/huggingface/gym-aloha?tab=readme-ov-file#description) environment also has the `AlohaTransferCube-v0` task which corresponds to this other task we want to train on. Putting this together, we can train this new policy on this different task using:
-
-```bash
-lerobot-train \
- --policy.type=act \
- --dataset.repo_id=lerobot/aloha_sim_transfer_cube_human \
- --env.type=aloha \
- --env.task=AlohaTransferCube-v0 \
- --output_dir=outputs/train/act_aloha_transfer
-```
-
-## Loading from a config file
-
-Now, let's assume that we want to reproduce the run just above. That run has produced a `train_config.json` file in its checkpoints, which serializes the `TrainPipelineConfig` instance it used:
-
-```json
-{
- "dataset": {
- "repo_id": "lerobot/aloha_sim_transfer_cube_human",
- "episodes": null,
- ...
- },
- "env": {
- "type": "aloha",
- "task": "AlohaTransferCube-v0",
- "fps": 50,
- ...
- },
- "policy": {
- "type": "act",
- "n_obs_steps": 1,
- ...
- },
- ...
-}
-```
-
-We can then simply load the config values from this file using:
-
-```bash
-lerobot-train \
- --config_path=outputs/train/act_aloha_transfer/checkpoints/last/pretrained_model/ \
- --output_dir=outputs/train/act_aloha_transfer_2
-```
-
-`--config_path` is also a special argument which allows to initialize the config from a local config file. It can point to a directory that contains `train_config.json` or to the config file itself directly.
-
-Similarly to Hydra, we can still override some parameters in the CLI if we want to, e.g.:
-
-```bash
-lerobot-train \
- --config_path=outputs/train/act_aloha_transfer/checkpoints/last/pretrained_model/ \
- --output_dir=outputs/train/act_aloha_transfer_2
- --policy.n_action_steps=80
-```
-
-> Note: While `--output_dir` is not required in general, in this case we need to specify it since it will otherwise take the value from the `train_config.json` (which is `outputs/train/act_aloha_transfer`). In order to prevent accidental deletion of previous run checkpoints, we raise an error if you're trying to write in an existing directory. This is not the case when resuming a run, which is what you'll learn next.
-
-`--config_path` can also accept the repo_id of a repo on the hub that contains a `train_config.json` file, e.g. running:
-
-```bash
-lerobot-train --config_path=lerobot/diffusion_pusht
-```
-
-will start a training run with the same configuration used for training [lerobot/diffusion_pusht](https://huggingface.co/lerobot/diffusion_pusht)
-
-## Resume training
-
-Being able to resume a training run is important in case it crashed or aborted for any reason. We'll demonstrate how to do that here.
-
-Let's reuse the command from the previous run and add a few more options:
-
-```bash
-lerobot-train \
- --policy.type=act \
- --dataset.repo_id=lerobot/aloha_sim_transfer_cube_human \
- --env.type=aloha \
- --env.task=AlohaTransferCube-v0 \
- --log_freq=25 \
- --save_freq=100 \
- --output_dir=outputs/train/run_resumption
-```
-
-Here we've taken care to set up the log frequency and checkpointing frequency to low numbers so we can showcase resumption. You should be able to see some logging and have a first checkpoint within 1 minute (depending on hardware). Wait for the first checkpoint to happen, you should see a line that looks like this in your terminal:
-
-```
-INFO 2025-01-24 16:10:56 ts/train.py:263 Checkpoint policy after step 100
-```
-
-Now let's simulate a crash by killing the process (hit `ctrl`+`c`). We can then simply resume this run from the last checkpoint available with:
-
-```bash
-lerobot-train \
- --config_path=outputs/train/run_resumption/checkpoints/last/pretrained_model/ \
- --resume=true
-```
-
-You should see from the logging that your training picks up from where it left off.
-
-Another reason for which you might want to resume a run is simply to extend training and add more training steps. The number of training steps is set by the option `--steps`, which is 100 000 by default.
-You could double the number of steps of the previous run with:
-
-```bash
-lerobot-train \
- --config_path=outputs/train/run_resumption/checkpoints/last/pretrained_model/ \
- --resume=true \
- --steps=200000
-```
-
-## Outputs of a run
-
-In the output directory, there will be a folder called `checkpoints` with the following structure:
-
-```bash
-outputs/train/run_resumption/checkpoints
-├── 000100 # checkpoint_dir for training step 100
-│ ├── pretrained_model/
-│ │ ├── config.json # policy config
-│ │ ├── model.safetensors # policy weights
-│ │ └── train_config.json # train config
-│ └── training_state/
-│ ├── optimizer_param_groups.json # optimizer param groups
-│ ├── optimizer_state.safetensors # optimizer state
-│ ├── rng_state.safetensors # rng states
-│ ├── scheduler_state.json # scheduler state
-│ └── training_step.json # training step
-├── 000200
-└── last -> 000200 # symlink to the last available checkpoint
-```
-
-## Fine-tuning a pre-trained policy
-
-In addition to the features currently in Draccus, we've added a special `.path` argument for the policy, which allows to load a policy as you would with `PreTrainedPolicy.from_pretrained()`. In that case, `path` can be a local directory that contains a checkpoint or a repo_id pointing to a pretrained policy on the hub.
-
-For example, we could fine-tune a [policy pre-trained on the aloha transfer task](https://huggingface.co/lerobot/act_aloha_sim_transfer_cube_human) on the aloha insertion task. We can achieve this with:
-
-```bash
-lerobot-train \
- --policy.path=lerobot/act_aloha_sim_transfer_cube_human \
- --dataset.repo_id=lerobot/aloha_sim_insertion_human \
- --env.type=aloha \
- --env.task=AlohaInsertion-v0
-```
-
-When doing so, keep in mind that the features of the fine-tuning dataset would have to match the input/output features of the pretrained policy.
-
-## Typical logs and metrics
-
-When you start the training process, you will first see your full configuration being printed in the terminal. You can check it to make sure that you configured your run correctly. The final configuration will also be saved with the checkpoint.
-
-After that, you will see training log like this one:
-
-```
-INFO 2024-08-14 13:35:12 ts/train.py:192 step:0 smpl:64 ep:1 epch:0.00 loss:1.112 grdn:15.387 lr:2.0e-07 updt_s:1.738 data_s:4.774
-```
-
-or evaluation log:
-
-```
-INFO 2024-08-14 13:38:45 ts/train.py:226 step:100 smpl:6K ep:52 epch:0.25 ∑rwrd:20.693 success:0.0% eval_s:120.266
-```
-
-These logs will also be saved in wandb if `wandb.enable` is set to `true`. Here are the meaning of some abbreviations:
-
-- `smpl`: number of samples seen during training.
-- `ep`: number of episodes seen during training. An episode contains multiple samples in a complete manipulation task.
-- `epch`: number of time all unique samples are seen (epoch).
-- `grdn`: gradient norm.
-- `∑rwrd`: compute the sum of rewards in every evaluation episode and then take an average of them.
-- `success`: average success rate of eval episodes. Reward and success are usually different except for the sparsing reward setting, where reward=1 only when the task is completed successfully.
-- `eval_s`: time to evaluate the policy in the environment, in second.
-- `updt_s`: time to update the network parameters, in second.
-- `data_s`: time to load a batch of data, in second.
-
-Some metrics are useful for initial performance profiling. For example, if you find the current GPU utilization is low via the `nvidia-smi` command and `data_s` sometimes is too high, you may need to modify batch size or number of dataloading workers to accelerate dataloading. We also recommend [pytorch profiler](https://github.com/huggingface/lerobot?tab=readme-ov-file#improve-your-code-with-profiling) for detailed performance probing.
-
-## In short
-
-We'll summarize here the main use cases to remember from this tutorial.
-
-#### Train a policy from scratch – CLI
-
-```bash
-lerobot-train \
- --policy.type=act \ # <- select 'act' policy
- --env.type=pusht \ # <- select 'pusht' environment
- --dataset.repo_id=lerobot/pusht # <- train on this dataset
-```
-
-#### Train a policy from scratch - config file + CLI
-
-```bash
-lerobot-train \
- --config_path=path/to/pretrained_model \ # <- can also be a repo_id
- --policy.n_action_steps=80 # <- you may still override values
-```
-
-#### Resume/continue a training run
-
-```bash
-lerobot-train \
- --config_path=checkpoint/pretrained_model/ \
- --resume=true \
- --steps=200000 # <- you can change some training parameters
-```
-
-#### Fine-tuning
-
-```bash
-lerobot-train \
- --policy.path=lerobot/act_aloha_sim_transfer_cube_human \ # <- can also be a local path to a checkpoint
- --dataset.repo_id=lerobot/aloha_sim_insertion_human \
- --env.type=aloha \
- --env.task=AlohaInsertion-v0
-```
-
----
-
-Now that you know the basics of how to train a policy, you might want to know how to apply this knowledge to actual robots, or how to record your own datasets and train policies on your specific task?
-If that's the case, head over to the next tutorial [`7_get_started_with_real_robot.md`](./7_get_started_with_real_robot.md).
-
-Or in the meantime, happy training! 🤗
diff --git a/examples/1_load_lerobot_dataset.py b/examples/dataset/load_lerobot_dataset.py
similarity index 99%
rename from examples/1_load_lerobot_dataset.py
rename to examples/dataset/load_lerobot_dataset.py
index ac4a843c7..a96c170cf 100644
--- a/examples/1_load_lerobot_dataset.py
+++ b/examples/dataset/load_lerobot_dataset.py
@@ -136,7 +136,7 @@ print(f"{dataset[0]['action'].shape=}\n") # (64, c)
# PyTorch datasets.
dataloader = torch.utils.data.DataLoader(
dataset,
- num_workers=0,
+ num_workers=4,
batch_size=32,
shuffle=True,
)
diff --git a/examples/dataset/use_dataset_image_transforms.py b/examples/dataset/use_dataset_image_transforms.py
new file mode 100644
index 000000000..c28f2ef0c
--- /dev/null
+++ b/examples/dataset/use_dataset_image_transforms.py
@@ -0,0 +1,177 @@
+#!/usr/bin/env python
+
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""
+This example demonstrates how to use image transforms with LeRobot datasets for data augmentation during training.
+
+Image transforms are applied to camera frames to improve model robustness and generalization. They are applied
+at training time only, not during dataset recording, allowing you to experiment with different augmentations
+without re-recording data.
+"""
+
+import torch
+from torchvision.transforms import v2
+from torchvision.transforms.functional import to_pil_image
+
+from lerobot.datasets.lerobot_dataset import LeRobotDataset
+from lerobot.datasets.transforms import ImageTransformConfig, ImageTransforms, ImageTransformsConfig
+
+
+def save_image(tensor, filename):
+ """Helper function to save a tensor as an image file."""
+ if tensor.dim() == 3: # [C, H, W]
+ if tensor.max() > 1.0:
+ tensor = tensor / 255.0
+ tensor = torch.clamp(tensor, 0.0, 1.0)
+ pil_image = to_pil_image(tensor)
+ pil_image.save(filename)
+ print(f"Saved: {filename}")
+ else:
+ print(f"Skipped {filename}: unexpected tensor shape {tensor.shape}")
+
+
+def example_1_default_transforms():
+ """Example 1: Use default transform configuration and save original vs transformed images"""
+ print("\n Example 1: Default Transform Configuration with Image Saving")
+
+ repo_id = "pepijn223/record_main_0" # Example dataset
+
+ try:
+ # Load dataset without transforms (original)
+ dataset_original = LeRobotDataset(repo_id=repo_id)
+
+ # Load dataset with transforms enabled
+ transforms_config = ImageTransformsConfig(
+ enable=True, # Enable transforms (disabled by default)
+ max_num_transforms=2, # Apply up to 2 transforms per frame
+ random_order=False, # Apply in standard order
+ )
+ dataset_with_transforms = LeRobotDataset(
+ repo_id=repo_id, image_transforms=ImageTransforms(transforms_config)
+ )
+
+ # Save original and transformed images for comparison
+ if len(dataset_original) > 0:
+ frame_idx = 0 # Use first frame
+ original_sample = dataset_original[frame_idx]
+ transformed_sample = dataset_with_transforms[frame_idx]
+
+ print(f"Saving comparison images (frame {frame_idx}):")
+
+ for cam_key in dataset_original.meta.camera_keys:
+ if cam_key in original_sample and cam_key in transformed_sample:
+ cam_name = cam_key.replace(".", "_").replace("/", "_")
+
+ # Save original and transformed images
+ save_image(original_sample[cam_key], f"{cam_name}_original.png")
+ save_image(transformed_sample[cam_key], f"{cam_name}_transformed.png")
+
+ except Exception as e:
+ print(f"Could not load dataset '{repo_id}': {e}")
+
+
+def example_2_custom_transforms():
+ """Example 2: Create custom transform configuration and save examples"""
+ print("\n Example 2: Custom Transform Configuration")
+
+ repo_id = "pepijn223/record_main_0" # Example dataset
+
+ try:
+ # Create custom transform configuration with strong effects
+ custom_transforms_config = ImageTransformsConfig(
+ enable=True,
+ max_num_transforms=2, # Apply up to 2 transforms per frame
+ random_order=True, # Apply transforms in random order
+ tfs={
+ "brightness": ImageTransformConfig(
+ weight=1.0,
+ type="ColorJitter",
+ kwargs={"brightness": (0.5, 1.5)}, # Strong brightness range
+ ),
+ "contrast": ImageTransformConfig(
+ weight=1.0, # Higher weight = more likely to be selected
+ type="ColorJitter",
+ kwargs={"contrast": (0.6, 1.4)}, # Strong contrast
+ ),
+ "sharpness": ImageTransformConfig(
+ weight=0.5, # Lower weight = less likely to be selected
+ type="SharpnessJitter",
+ kwargs={"sharpness": (0.2, 2.0)}, # Strong sharpness variation
+ ),
+ },
+ )
+
+ dataset_with_custom_transforms = LeRobotDataset(
+ repo_id=repo_id, image_transforms=ImageTransforms(custom_transforms_config)
+ )
+
+ # Save examples with strong transforms
+ if len(dataset_with_custom_transforms) > 0:
+ sample = dataset_with_custom_transforms[0]
+ print("Saving custom transform examples:")
+
+ for cam_key in dataset_with_custom_transforms.meta.camera_keys:
+ if cam_key in sample:
+ cam_name = cam_key.replace(".", "_").replace("/", "_")
+ save_image(sample[cam_key], f"{cam_name}_custom_transforms.png")
+
+ except Exception as e:
+ print(f"Could not load dataset '{repo_id}': {e}")
+
+
+def example_3_torchvision_transforms():
+ """Example 3: Use pure torchvision transforms and save examples"""
+ print("\n Example 3: Pure Torchvision Transforms")
+
+ repo_id = "pepijn223/record_main_0" # Example dataset
+
+ try:
+ # Create torchvision transform pipeline
+ torchvision_transforms = v2.Compose(
+ [
+ v2.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.1),
+ v2.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
+ v2.RandomRotation(degrees=10), # Small rotation
+ ]
+ )
+
+ dataset_with_torchvision = LeRobotDataset(repo_id=repo_id, image_transforms=torchvision_transforms)
+
+ # Save examples with torchvision transforms
+ if len(dataset_with_torchvision) > 0:
+ sample = dataset_with_torchvision[0]
+ print("Saving torchvision transform examples:")
+
+ for cam_key in dataset_with_torchvision.meta.camera_keys:
+ if cam_key in sample:
+ cam_name = cam_key.replace(".", "_").replace("/", "_")
+ save_image(sample[cam_key], f"{cam_name}_torchvision.png")
+
+ except Exception as e:
+ print(f"Could not load dataset '{repo_id}': {e}")
+
+
+def main():
+ """Run all examples"""
+ print("LeRobot Dataset Image Transforms Examples")
+
+ example_1_default_transforms()
+ example_2_custom_transforms()
+ example_3_torchvision_transforms()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/examples/3_train_policy.py b/examples/training/train_policy.py
similarity index 97%
rename from examples/3_train_policy.py
rename to examples/training/train_policy.py
index 7f3fad36c..16f2a4d87 100644
--- a/examples/3_train_policy.py
+++ b/examples/training/train_policy.py
@@ -12,11 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-"""This script demonstrates how to train Diffusion Policy on the PushT environment.
-
-Once you have trained a model with this script, you can try to evaluate it on
-examples/2_evaluate_pretrained_policy.py
-"""
+"""This script demonstrates how to train Diffusion Policy on the PushT environment."""
from pathlib import Path
diff --git a/examples/5_train_with_streaming.py b/examples/training/train_with_streaming.py
similarity index 93%
rename from examples/5_train_with_streaming.py
rename to examples/training/train_with_streaming.py
index 93d13535f..e7edc17f8 100644
--- a/examples/5_train_with_streaming.py
+++ b/examples/training/train_with_streaming.py
@@ -13,11 +13,7 @@
# limitations under the License.
"""This script demonstrates how to train a Diffusion Policy on the PushT environment,
-using a dataset processed in streaming mode.
-
-Once you have trained a model with this script, you can try to evaluate it on
-examples/2_evaluate_pretrained_policy.py
-"""
+using a dataset processed in streaming mode."""
from pathlib import Path
@@ -51,9 +47,7 @@ def main():
training_steps = 10
log_freq = 1
- dataset_id = (
- "aractingi/droid_1.0.1" # 26M frames! Would require 4TB of disk space if installed locally (:
- )
+ dataset_id = "lerobot/droid_1.0.1" # 26M frames! Would require 4TB of disk space if installed locally (:
dataset_metadata = LeRobotDatasetMetadata(dataset_id)
features = dataset_to_policy_features(dataset_metadata.features)
output_features = {key: ft for key, ft in features.items() if ft.type is FeatureType.ACTION}
diff --git a/pyproject.toml b/pyproject.toml
index 98ccc7b9b..45c4146f0 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -59,7 +59,7 @@ keywords = ["lerobot", "huggingface", "robotics", "machine learning", "artifici
dependencies = [
# Hugging Face dependencies
- "datasets>=2.19.0,<=3.6.0", # TODO: Bumb dependency
+ "datasets>=4.0.0",
"diffusers>=0.27.2",
"huggingface-hub[hf-transfer,cli]>=0.34.2",
@@ -121,7 +121,7 @@ phone = ["hebi-py>=2.8.0", "teleop>=0.1.0"]
# Policies
pi = ["lerobot[transformers-dep]"]
smolvla = ["lerobot[transformers-dep]", "num2words>=0.5.14", "accelerate>=1.7.0", "safetensors>=0.4.3"]
-hilserl = ["lerobot[transformers-dep]", "gym-hil>=0.1.9", "lerobot[grpcio-dep]", "lerobot[placo-dep]"]
+hilserl = ["lerobot[transformers-dep]", "gym-hil>=0.1.11", "lerobot[grpcio-dep]", "lerobot[placo-dep]"]
# Features
async = ["lerobot[grpcio-dep]", "matplotlib>=3.10.3"]
@@ -135,6 +135,8 @@ video_benchmark = ["scikit-image>=0.23.2", "pandas>=2.2.2"]
aloha = ["gym-aloha>=0.1.1"]
pusht = ["gym-pusht>=0.1.5", "pymunk>=6.6.0,<7.0.0"] # TODO: Fix pymunk version in gym-pusht instead
xarm = ["gym-xarm>=0.1.1"]
+libero = ["lerobot[transformers-dep]", "libero @ git+https://github.com/huggingface/lerobot-libero.git@main#egg=libero"]
+
# All
all = [
@@ -157,6 +159,7 @@ all = [
"lerobot[pusht]",
"lerobot[xarm]",
"lerobot[phone]",
+ "lerobot[libero]",
]
[project.scripts]
diff --git a/src/lerobot/envs/configs.py b/src/lerobot/envs/configs.py
index f71aca70d..8c66b278e 100644
--- a/src/lerobot/envs/configs.py
+++ b/src/lerobot/envs/configs.py
@@ -30,6 +30,8 @@ class EnvConfig(draccus.ChoiceRegistry, abc.ABC):
fps: int = 30
features: dict[str, PolicyFeature] = field(default_factory=dict)
features_map: dict[str, str] = field(default_factory=dict)
+ max_parallel_tasks: int = 1
+ disable_env_checker: bool = True
@property
def type(self) -> str:
@@ -242,3 +244,55 @@ class HILSerlRobotEnvConfig(EnvConfig):
@property
def gym_kwargs(self) -> dict:
return {}
+
+
+@EnvConfig.register_subclass("libero")
+@dataclass
+class LiberoEnv(EnvConfig):
+ task: str = "libero_10" # can also choose libero_spatial, libero_object, etc.
+ fps: int = 30
+ episode_length: int = 520
+ obs_type: str = "pixels_agent_pos"
+ render_mode: str = "rgb_array"
+ camera_name: str = "agentview_image,robot0_eye_in_hand_image"
+ init_states: bool = True
+ camera_name_mapping: dict[str, str] | None = (None,)
+ features: dict[str, PolicyFeature] = field(
+ default_factory=lambda: {
+ "action": PolicyFeature(type=FeatureType.ACTION, shape=(7,)),
+ }
+ )
+ features_map: dict[str, str] = field(
+ default_factory=lambda: {
+ "action": ACTION,
+ "agent_pos": OBS_STATE,
+ "pixels/agentview_image": f"{OBS_IMAGES}.image",
+ "pixels/robot0_eye_in_hand_image": f"{OBS_IMAGES}.image2",
+ }
+ )
+
+ def __post_init__(self):
+ if self.obs_type == "pixels":
+ self.features["pixels/agentview_image"] = PolicyFeature(
+ type=FeatureType.VISUAL, shape=(360, 360, 3)
+ )
+ self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
+ type=FeatureType.VISUAL, shape=(360, 360, 3)
+ )
+ elif self.obs_type == "pixels_agent_pos":
+ self.features["agent_pos"] = PolicyFeature(type=FeatureType.STATE, shape=(8,))
+ self.features["pixels/agentview_image"] = PolicyFeature(
+ type=FeatureType.VISUAL, shape=(360, 360, 3)
+ )
+ self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
+ type=FeatureType.VISUAL, shape=(360, 360, 3)
+ )
+ else:
+ raise ValueError(f"Unsupported obs_type: {self.obs_type}")
+
+ @property
+ def gym_kwargs(self) -> dict:
+ return {
+ "obs_type": self.obs_type,
+ "render_mode": self.render_mode,
+ }
diff --git a/src/lerobot/envs/factory.py b/src/lerobot/envs/factory.py
index af8f5eaf5..9b172854c 100644
--- a/src/lerobot/envs/factory.py
+++ b/src/lerobot/envs/factory.py
@@ -17,7 +17,7 @@ import importlib
import gymnasium as gym
-from lerobot.envs.configs import AlohaEnv, EnvConfig, PushtEnv, XarmEnv
+from lerobot.envs.configs import AlohaEnv, EnvConfig, LiberoEnv, PushtEnv, XarmEnv
def make_env_config(env_type: str, **kwargs) -> EnvConfig:
@@ -27,11 +27,15 @@ def make_env_config(env_type: str, **kwargs) -> EnvConfig:
return PushtEnv(**kwargs)
elif env_type == "xarm":
return XarmEnv(**kwargs)
+ elif env_type == "libero":
+ return LiberoEnv(**kwargs)
else:
raise ValueError(f"Policy type '{env_type}' is not available.")
-def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> gym.vector.VectorEnv | None:
+def make_env(
+ cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False
+) -> dict[str, dict[int, gym.vector.VectorEnv]]:
"""Makes a gym vector environment according to the config.
Args:
@@ -45,13 +49,30 @@ def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> g
ModuleNotFoundError: If the requested env package is not installed
Returns:
- gym.vector.VectorEnv: The parallelized gym.env instance.
+ dict[str, dict[int, gym.vector.VectorEnv]]:
+ A mapping from suite name to indexed vectorized environments.
+ - For multi-task benchmarks (e.g., LIBERO): one entry per suite, and one vec env per task_id.
+ - For single-task environments: a single suite entry (cfg.type) with task_id=0.
+
"""
if n_envs < 1:
- raise ValueError("`n_envs must be at least 1")
+ raise ValueError("`n_envs` must be at least 1")
+
+ env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
+
+ if "libero" in cfg.type:
+ from lerobot.envs.libero import create_libero_envs
+
+ return create_libero_envs(
+ task=cfg.task,
+ n_envs=n_envs,
+ camera_name=cfg.camera_name,
+ init_states=cfg.init_states,
+ gym_kwargs=cfg.gym_kwargs,
+ env_cls=env_cls,
+ )
package_name = f"gym_{cfg.type}"
-
try:
importlib.import_module(package_name)
except ModuleNotFoundError as e:
@@ -60,10 +81,11 @@ def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> g
gym_handle = f"{package_name}/{cfg.task}"
- # batched version of the env that returns an observation of shape (b, c)
- env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
- env = env_cls(
- [lambda: gym.make(gym_handle, disable_env_checker=True, **cfg.gym_kwargs) for _ in range(n_envs)]
- )
+ def _make_one():
+ return gym.make(gym_handle, disable_env_checker=cfg.disable_env_checker, **(cfg.gym_kwargs or {}))
- return env
+ vec = env_cls([_make_one for _ in range(n_envs)])
+
+ # normalize to {suite: {task_id: vec_env}} for consistency
+ suite_name = cfg.type # e.g., "pusht", "aloha"
+ return {suite_name: {0: vec}}
diff --git a/src/lerobot/envs/libero.py b/src/lerobot/envs/libero.py
new file mode 100644
index 000000000..466796975
--- /dev/null
+++ b/src/lerobot/envs/libero.py
@@ -0,0 +1,377 @@
+#!/usr/bin/env python
+
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import annotations
+
+import os
+from collections import defaultdict
+from collections.abc import Callable, Iterable, Mapping, Sequence
+from functools import partial
+from pathlib import Path
+from typing import Any
+
+import gymnasium as gym
+import numpy as np
+import torch
+from gymnasium import spaces
+from libero.libero import benchmark, get_libero_path
+from libero.libero.envs import OffScreenRenderEnv
+from robosuite.utils.transform_utils import quat2axisangle
+
+
+def _parse_camera_names(camera_name: str | Sequence[str]) -> list[str]:
+ """Normalize camera_name into a non-empty list of strings."""
+ if isinstance(camera_name, str):
+ cams = [c.strip() for c in camera_name.split(",") if c.strip()]
+ elif isinstance(camera_name, (list, tuple)):
+ cams = [str(c).strip() for c in camera_name if str(c).strip()]
+ else:
+ raise TypeError(f"camera_name must be str or sequence[str], got {type(camera_name).__name__}")
+ if not cams:
+ raise ValueError("camera_name resolved to an empty list.")
+ return cams
+
+
+def _get_suite(name: str) -> benchmark.Benchmark:
+ """Instantiate a LIBERO suite by name with clear validation."""
+ bench = benchmark.get_benchmark_dict()
+ if name not in bench:
+ raise ValueError(f"Unknown LIBERO suite '{name}'. Available: {', '.join(sorted(bench.keys()))}")
+ suite = bench[name]()
+ if not getattr(suite, "tasks", None):
+ raise ValueError(f"Suite '{name}' has no tasks.")
+ return suite
+
+
+def _select_task_ids(total_tasks: int, task_ids: Iterable[int] | None) -> list[int]:
+ """Validate/normalize task ids. If None → all tasks."""
+ if task_ids is None:
+ return list(range(total_tasks))
+ ids = sorted({int(t) for t in task_ids})
+ for t in ids:
+ if t < 0 or t >= total_tasks:
+ raise ValueError(f"task_id {t} out of range [0, {total_tasks - 1}].")
+ return ids
+
+
+def get_task_init_states(task_suite: Any, i: int) -> np.ndarray:
+ init_states_path = (
+ Path(get_libero_path("init_states"))
+ / task_suite.tasks[i].problem_folder
+ / task_suite.tasks[i].init_states_file
+ )
+ init_states = torch.load(init_states_path, weights_only=False) # nosec B614
+ return init_states
+
+
+def get_libero_dummy_action():
+ """Get dummy/no-op action, used to roll out the simulation while the robot does nothing."""
+ return [0, 0, 0, 0, 0, 0, -1]
+
+
+OBS_STATE_DIM = 8
+ACTION_DIM = 7
+AGENT_POS_LOW = -1000.0
+AGENT_POS_HIGH = 1000.0
+ACTION_LOW = -1.0
+ACTION_HIGH = 1.0
+TASK_SUITE_MAX_STEPS: dict[str, int] = {
+ "libero_spatial": 280, # longest training demo has 193 steps
+ "libero_object": 280, # longest training demo has 254 steps
+ "libero_goal": 300, # longest training demo has 270 steps
+ "libero_10": 520, # longest training demo has 505 steps
+ "libero_90": 400, # longest training demo has 373 steps
+}
+
+
+class LiberoEnv(gym.Env):
+ metadata = {"render_modes": ["rgb_array"], "render_fps": 80}
+
+ def __init__(
+ self,
+ task_suite: Any,
+ task_id: int,
+ task_suite_name: str,
+ camera_name: str | Sequence[str] = "agentview_image,robot0_eye_in_hand_image",
+ obs_type: str = "pixels",
+ render_mode: str = "rgb_array",
+ observation_width: int = 256,
+ observation_height: int = 256,
+ visualization_width: int = 640,
+ visualization_height: int = 480,
+ init_states: bool = True,
+ episode_index: int = 0,
+ camera_name_mapping: dict[str, str] | None = None,
+ num_steps_wait: int = 10,
+ ):
+ super().__init__()
+ self.task_id = task_id
+ self.obs_type = obs_type
+ self.render_mode = render_mode
+ self.observation_width = observation_width
+ self.observation_height = observation_height
+ self.visualization_width = visualization_width
+ self.visualization_height = visualization_height
+ self.init_states = init_states
+ self.camera_name = _parse_camera_names(
+ camera_name
+ ) # agentview_image (main) or robot0_eye_in_hand_image (wrist)
+
+ # Map raw camera names to "image1" and "image2".
+ # The preprocessing step `preprocess_observation` will then prefix these with `.images.*`,
+ # following the LeRobot convention (e.g., `observation.images.image`, `observation.images.image2`).
+ # This ensures the policy consistently receives observations in the
+ # expected format regardless of the original camera naming.
+ if camera_name_mapping is None:
+ camera_name_mapping = {
+ "agentview_image": "image",
+ "robot0_eye_in_hand_image": "image2",
+ }
+ self.camera_name_mapping = camera_name_mapping
+ self.num_steps_wait = num_steps_wait
+ self.episode_index = episode_index
+ # Load once and keep
+ self._init_states = get_task_init_states(task_suite, self.task_id) if self.init_states else None
+ self._init_state_id = self.episode_index # tie each sub-env to a fixed init state
+
+ self._env = self._make_envs_task(task_suite, self.task_id)
+ default_steps = 500
+ self._max_episode_steps = TASK_SUITE_MAX_STEPS.get(task_suite_name, default_steps)
+
+ images = {}
+ for cam in self.camera_name:
+ images[self.camera_name_mapping[cam]] = spaces.Box(
+ low=0,
+ high=255,
+ shape=(self.observation_height, self.observation_width, 3),
+ dtype=np.uint8,
+ )
+
+ if self.obs_type == "state":
+ raise NotImplementedError(
+ "The 'state' observation type is not supported in LiberoEnv. "
+ "Please switch to an image-based obs_type (e.g. 'pixels', 'pixels_agent_pos')."
+ )
+
+ elif self.obs_type == "pixels":
+ self.observation_space = spaces.Dict(
+ {
+ "pixels": spaces.Dict(images),
+ }
+ )
+ elif self.obs_type == "pixels_agent_pos":
+ self.observation_space = spaces.Dict(
+ {
+ "pixels": spaces.Dict(images),
+ "agent_pos": spaces.Box(
+ low=AGENT_POS_LOW,
+ high=AGENT_POS_HIGH,
+ shape=(OBS_STATE_DIM,),
+ dtype=np.float64,
+ ),
+ }
+ )
+
+ self.action_space = spaces.Box(
+ low=ACTION_LOW, high=ACTION_HIGH, shape=(ACTION_DIM,), dtype=np.float32
+ )
+
+ def render(self):
+ raw_obs = self._env.env._get_observations()
+ image = self._format_raw_obs(raw_obs)["pixels"]["image"]
+ return image
+
+ def _make_envs_task(self, task_suite: Any, task_id: int = 0):
+ task = task_suite.get_task(task_id)
+ self.task = task.name
+ self.task_description = task.language
+ task_bddl_file = os.path.join(get_libero_path("bddl_files"), task.problem_folder, task.bddl_file)
+
+ env_args = {
+ "bddl_file_name": task_bddl_file,
+ "camera_heights": self.observation_height,
+ "camera_widths": self.observation_width,
+ }
+ env = OffScreenRenderEnv(**env_args)
+ env.reset()
+ return env
+
+ def _format_raw_obs(self, raw_obs: dict[str, Any]) -> dict[str, Any]:
+ images = {}
+ for camera_name in self.camera_name:
+ image = raw_obs[camera_name]
+ image = image[::-1, ::-1] # rotate 180 degrees
+ images[self.camera_name_mapping[camera_name]] = image
+ state = np.concatenate(
+ (
+ raw_obs["robot0_eef_pos"],
+ quat2axisangle(raw_obs["robot0_eef_quat"]),
+ raw_obs["robot0_gripper_qpos"],
+ )
+ )
+ agent_pos = state
+ if self.obs_type == "pixels":
+ return {"pixels": images.copy()}
+ if self.obs_type == "pixels_agent_pos":
+ return {
+ "pixels": images.copy(),
+ "agent_pos": agent_pos,
+ }
+ raise NotImplementedError(
+ f"The observation type '{self.obs_type}' is not supported in LiberoEnv. "
+ "Please switch to an image-based obs_type (e.g. 'pixels', 'pixels_agent_pos')."
+ )
+
+ def reset(self, seed=None, **kwargs):
+ super().reset(seed=seed)
+ self._env.seed(seed)
+ if self.init_states and self._init_states is not None:
+ self._env.set_init_state(self._init_states[self._init_state_id])
+ raw_obs = self._env.reset()
+
+ # After reset, objects may be unstable (slightly floating, intersecting, etc.).
+ # Step the simulator with a no-op action for a few frames so everything settles.
+ # Increasing this value can improve determinism and reproducibility across resets.
+ for _ in range(self.num_steps_wait):
+ raw_obs, _, _, _ = self._env.step(get_libero_dummy_action())
+ observation = self._format_raw_obs(raw_obs)
+ info = {"is_success": False}
+ return observation, info
+
+ def step(self, action: np.ndarray) -> tuple[dict[str, Any], float, bool, bool, dict[str, Any]]:
+ if action.ndim != 1:
+ raise ValueError(
+ f"Expected action to be 1-D (shape (action_dim,)), "
+ f"but got shape {action.shape} with ndim={action.ndim}"
+ )
+ raw_obs, reward, done, info = self._env.step(action)
+
+ is_success = self._env.check_success()
+ terminated = done or is_success
+ info["is_success"] = is_success
+
+ observation = self._format_raw_obs(raw_obs)
+ if done:
+ self.reset()
+ info.update(
+ {
+ "task": self.task,
+ "task_id": self.task_id,
+ "done": done,
+ "is_success": is_success,
+ }
+ )
+ truncated = False
+ return observation, reward, terminated, truncated, info
+
+ def close(self):
+ self._env.close()
+
+
+def _make_env_fns(
+ *,
+ suite,
+ suite_name: str,
+ task_id: int,
+ n_envs: int,
+ camera_names: list[str],
+ init_states: bool,
+ gym_kwargs: Mapping[str, Any],
+) -> list[Callable[[], LiberoEnv]]:
+ """Build n_envs factory callables for a single (suite, task_id)."""
+
+ def _make_env(episode_index: int, **kwargs) -> LiberoEnv:
+ local_kwargs = dict(kwargs)
+ return LiberoEnv(
+ task_suite=suite,
+ task_id=task_id,
+ task_suite_name=suite_name,
+ camera_name=camera_names,
+ init_states=init_states,
+ episode_index=episode_index,
+ **local_kwargs,
+ )
+
+ fns: list[Callable[[], LiberoEnv]] = []
+ for episode_index in range(n_envs):
+ fns.append(partial(_make_env, episode_index, **gym_kwargs))
+ return fns
+
+
+# ---- Main API ----------------------------------------------------------------
+
+
+def create_libero_envs(
+ task: str,
+ n_envs: int,
+ gym_kwargs: dict[str, Any] | None = None,
+ camera_name: str | Sequence[str] = "agentview_image,robot0_eye_in_hand_image",
+ init_states: bool = True,
+ env_cls: Callable[[Sequence[Callable[[], Any]]], Any] | None = None,
+) -> dict[str, dict[int, Any]]:
+ """
+ Create vectorized LIBERO environments with a consistent return shape.
+
+ Returns:
+ dict[suite_name][task_id] -> vec_env (env_cls([...]) with exactly n_envs factories)
+ Notes:
+ - n_envs is the number of rollouts *per task* (episode_index = 0..n_envs-1).
+ - `task` can be a single suite or a comma-separated list of suites.
+ - You may pass `task_ids` (list[int]) inside `gym_kwargs` to restrict tasks per suite.
+ """
+ if env_cls is None or not callable(env_cls):
+ raise ValueError("env_cls must be a callable that wraps a list of environment factory callables.")
+ if not isinstance(n_envs, int) or n_envs <= 0:
+ raise ValueError(f"n_envs must be a positive int; got {n_envs}.")
+
+ gym_kwargs = dict(gym_kwargs or {})
+ task_ids_filter = gym_kwargs.pop("task_ids", None) # optional: limit to specific tasks
+
+ camera_names = _parse_camera_names(camera_name)
+ suite_names = [s.strip() for s in str(task).split(",") if s.strip()]
+ if not suite_names:
+ raise ValueError("`task` must contain at least one LIBERO suite name.")
+
+ print(
+ f"Creating LIBERO envs | suites={suite_names} | n_envs(per task)={n_envs} | init_states={init_states}"
+ )
+ if task_ids_filter is not None:
+ print(f"Restricting to task_ids={task_ids_filter}")
+
+ out: dict[str, dict[int, Any]] = defaultdict(dict)
+
+ for suite_name in suite_names:
+ suite = _get_suite(suite_name)
+ total = len(suite.tasks)
+ selected = _select_task_ids(total, task_ids_filter)
+
+ if not selected:
+ raise ValueError(f"No tasks selected for suite '{suite_name}' (available: {total}).")
+
+ for tid in selected:
+ fns = _make_env_fns(
+ suite=suite,
+ suite_name=suite_name,
+ task_id=tid,
+ n_envs=n_envs,
+ camera_names=camera_names,
+ init_states=init_states,
+ gym_kwargs=gym_kwargs,
+ )
+ out[suite_name][tid] = env_cls(fns)
+ print(f"Built vec env | suite={suite_name} | task_id={tid} | n_envs={n_envs}")
+
+ # return plain dicts for predictability
+ return {suite: dict(task_map) for suite, task_map in out.items()}
diff --git a/src/lerobot/envs/utils.py b/src/lerobot/envs/utils.py
index b4f65ee9c..f0aa0b5c6 100644
--- a/src/lerobot/envs/utils.py
+++ b/src/lerobot/envs/utils.py
@@ -14,6 +14,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import warnings
+from collections.abc import Mapping, Sequence
+from functools import singledispatch
from typing import Any
import einops
@@ -154,3 +156,41 @@ def add_envs_task(env: gym.vector.VectorEnv, observation: dict[str, Any]) -> dic
num_envs = observation[list(observation.keys())[0]].shape[0]
observation["task"] = ["" for _ in range(num_envs)]
return observation
+
+
+def _close_single_env(env: Any) -> None:
+ try:
+ env.close()
+ except Exception as exc:
+ print(f"Exception while closing env {env}: {exc}")
+
+
+@singledispatch
+def close_envs(obj: Any) -> None:
+ """Default: raise if the type is not recognized."""
+ raise NotImplementedError(f"close_envs not implemented for type {type(obj).__name__}")
+
+
+@close_envs.register
+def _(env: Mapping) -> None:
+ for v in env.values():
+ if isinstance(v, Mapping):
+ close_envs(v)
+ elif hasattr(v, "close"):
+ _close_single_env(v)
+
+
+@close_envs.register
+def _(envs: Sequence) -> None:
+ if isinstance(envs, (str, bytes)):
+ return
+ for v in envs:
+ if isinstance(v, Mapping) or isinstance(v, Sequence) and not isinstance(v, (str, bytes)):
+ close_envs(v)
+ elif hasattr(v, "close"):
+ _close_single_env(v)
+
+
+@close_envs.register
+def _(env: gym.Env) -> None:
+ _close_single_env(env)
diff --git a/src/lerobot/robots/stretch3/README.md b/src/lerobot/robots/stretch3/README.md
index 724732286..027f12d65 100644
--- a/src/lerobot/robots/stretch3/README.md
+++ b/src/lerobot/robots/stretch3/README.md
@@ -170,8 +170,4 @@ python lerobot/scripts/control_robot.py \
--control.episode=0
```
-Follow [previous tutorial](https://github.com/huggingface/lerobot/blob/main/examples/7_get_started_with_real_robot.md#4-train-a-policy-on-your-data) to train a policy on your data and run inference on your robot. You will need to adapt the code for Stretch.
-
-> TODO(rcadene, aliberts): Add already setup environment and policy yaml configuration files
-
If you need help, please reach out on Discord in the channel `#stretch3-mobile-arm`.
diff --git a/src/lerobot/robots/viperx/README.md b/src/lerobot/robots/viperx/README.md
index 5b57d61f5..f6386215a 100644
--- a/src/lerobot/robots/viperx/README.md
+++ b/src/lerobot/robots/viperx/README.md
@@ -193,6 +193,4 @@ As you can see, it's almost the same command as previously used to record your t
## More
-Follow this [previous tutorial](https://github.com/huggingface/lerobot/blob/main/examples/7_get_started_with_real_robot.md#4-train-a-policy-on-your-data) for a more in-depth explanation.
-
If you have any question or need help, please reach out on Discord in the channel `#aloha-arm`.
diff --git a/src/lerobot/scripts/eval.py b/src/lerobot/scripts/eval.py
index bf398a0a9..ca900f8df 100644
--- a/src/lerobot/scripts/eval.py
+++ b/src/lerobot/scripts/eval.py
@@ -46,17 +46,20 @@ Note that in both examples, the repo/folder should contain at least `config.json
You can learn about the CLI options for this script in the `EvalPipelineConfig` in lerobot/configs/eval.py
"""
+import concurrent.futures as cf
import json
import logging
import threading
import time
+from collections import defaultdict
from collections.abc import Callable
from contextlib import nullcontext
from copy import deepcopy
from dataclasses import asdict
+from functools import partial
from pathlib import Path
from pprint import pformat
-from typing import Any
+from typing import Any, TypedDict
import einops
import gymnasium as gym
@@ -69,7 +72,12 @@ from tqdm import trange
from lerobot.configs import parser
from lerobot.configs.eval import EvalPipelineConfig
from lerobot.envs.factory import make_env
-from lerobot.envs.utils import add_envs_task, check_env_attributes_and_types, preprocess_observation
+from lerobot.envs.utils import (
+ add_envs_task,
+ check_env_attributes_and_types,
+ close_envs,
+ preprocess_observation,
+)
from lerobot.policies.factory import make_policy, make_pre_post_processors
from lerobot.policies.pretrained import PreTrainedPolicy
from lerobot.processor import PolicyAction, PolicyProcessorPipeline
@@ -147,7 +155,7 @@ def rollout(
leave=False,
)
check_env_attributes_and_types(env)
- while not np.all(done):
+ while not np.all(done) and step < max_steps:
# Numpy array to tensor and changing dictionary keys to LeRobot policy format.
observation = preprocess_observation(observation)
if return_observations:
@@ -178,7 +186,12 @@ def rollout(
successes = [False] * env.num_envs
# Keep track of which environments are done so far.
+ # Mark the episode as done if we reach the maximum step limit.
+ # This ensures that the rollout always terminates cleanly at `max_steps`,
+ # and allows logging/saving (e.g., videos) to be triggered consistently.
done = terminated | truncated | done
+ if step + 1 == max_steps:
+ done = np.ones_like(done, dtype=bool)
all_actions.append(torch.from_numpy(action_numpy))
all_rewards.append(torch.from_numpy(reward))
@@ -474,7 +487,7 @@ def eval_main(cfg: EvalPipelineConfig):
logging.info(colored("Output dir:", "yellow", attrs=["bold"]) + f" {cfg.output_dir}")
logging.info("Making environment.")
- env = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
+ envs = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
logging.info("Making policy.")
@@ -490,10 +503,9 @@ def eval_main(cfg: EvalPipelineConfig):
# The inference device is automatically set to match the detected hardware, overriding any previous device settings from training to ensure compatibility.
preprocessor_overrides={"device_processor": {"device": str(policy.config.device)}},
)
-
with torch.no_grad(), torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext():
- info = eval_policy(
- env=env,
+ info = eval_policy_all(
+ envs=envs,
policy=policy,
preprocessor=preprocessor,
postprocessor=postprocessor,
@@ -501,18 +513,237 @@ def eval_main(cfg: EvalPipelineConfig):
max_episodes_rendered=10,
videos_dir=Path(cfg.output_dir) / "videos",
start_seed=cfg.seed,
+ max_parallel_tasks=cfg.env.max_parallel_tasks,
)
- print(info["aggregated"])
+ print("Overall Aggregated Metrics:")
+ print(info["overall"])
+
+ # Print per-suite stats
+ for task_group, task_group_info in info.items():
+ print(f"\nAggregated Metrics for {task_group}:")
+ print(task_group_info)
+ # Close all vec envs
+ close_envs(envs)
# Save info
with open(Path(cfg.output_dir) / "eval_info.json", "w") as f:
json.dump(info, f, indent=2)
- env.close()
-
logging.info("End of eval")
+# ---- typed payload returned by one task eval ----
+class TaskMetrics(TypedDict):
+ sum_rewards: list[float]
+ max_rewards: list[float]
+ successes: list[bool]
+ video_paths: list[str]
+
+
+ACC_KEYS = ("sum_rewards", "max_rewards", "successes", "video_paths")
+
+
+def eval_one(
+ env: gym.vector.VectorEnv,
+ *,
+ policy: PreTrainedPolicy,
+ preprocessor: PolicyProcessorPipeline[dict[str, Any], dict[str, Any]],
+ postprocessor: PolicyProcessorPipeline[PolicyAction, PolicyAction],
+ n_episodes: int,
+ max_episodes_rendered: int,
+ videos_dir: Path | None,
+ return_episode_data: bool,
+ start_seed: int | None,
+) -> TaskMetrics:
+ """Evaluates one task_id of one suite using the provided vec env."""
+
+ task_videos_dir = videos_dir
+
+ task_result = eval_policy(
+ env=env,
+ policy=policy,
+ preprocessor=preprocessor,
+ postprocessor=postprocessor,
+ n_episodes=n_episodes,
+ max_episodes_rendered=max_episodes_rendered,
+ videos_dir=task_videos_dir,
+ return_episode_data=return_episode_data,
+ start_seed=start_seed,
+ )
+
+ per_episode = task_result["per_episode"]
+ return TaskMetrics(
+ sum_rewards=[ep["sum_reward"] for ep in per_episode],
+ max_rewards=[ep["max_reward"] for ep in per_episode],
+ successes=[ep["success"] for ep in per_episode],
+ video_paths=task_result.get("video_paths", []),
+ )
+
+
+def run_one(
+ task_group: str,
+ task_id: int,
+ env,
+ *,
+ policy,
+ preprocessor,
+ postprocessor,
+ n_episodes: int,
+ max_episodes_rendered: int,
+ videos_dir: Path | None,
+ return_episode_data: bool,
+ start_seed: int | None,
+):
+ """
+ Run eval_one for a single (task_group, task_id, env).
+ Returns (task_group, task_id, task_metrics_dict).
+ This function is intentionally module-level to make it easy to test.
+ """
+ task_videos_dir = None
+ if videos_dir is not None:
+ task_videos_dir = videos_dir / f"{task_group}_{task_id}"
+ task_videos_dir.mkdir(parents=True, exist_ok=True)
+
+ # Call the existing eval_one (assumed to return TaskMetrics-like dict)
+ metrics = eval_one(
+ env,
+ policy=policy,
+ preprocessor=preprocessor,
+ postprocessor=postprocessor,
+ n_episodes=n_episodes,
+ max_episodes_rendered=max_episodes_rendered,
+ videos_dir=task_videos_dir,
+ return_episode_data=return_episode_data,
+ start_seed=start_seed,
+ )
+ # ensure we always provide video_paths key to simplify accumulation
+ if max_episodes_rendered > 0:
+ metrics.setdefault("video_paths", [])
+ return task_group, task_id, metrics
+
+
+def eval_policy_all(
+ envs: dict[str, dict[int, gym.vector.VectorEnv]],
+ policy,
+ preprocessor: PolicyProcessorPipeline[dict[str, Any], dict[str, Any]],
+ postprocessor: PolicyProcessorPipeline[PolicyAction, PolicyAction],
+ n_episodes: int,
+ *,
+ max_episodes_rendered: int = 0,
+ videos_dir: Path | None = None,
+ return_episode_data: bool = False,
+ start_seed: int | None = None,
+ max_parallel_tasks: int = 1,
+) -> dict:
+ """
+ Evaluate a nested `envs` dict: {task_group: {task_id: vec_env}}.
+ This implementation flattens tasks, runs them sequentially or via ThreadPoolExecutor,
+ accumulates per-group and overall statistics, and returns the same aggregate metrics
+ schema as the single-env evaluator (avg_sum_reward / avg_max_reward / pc_success / timings)
+ plus per-task infos.
+ """
+ start_t = time.time()
+
+ # Flatten envs into list of (task_group, task_id, env)
+ tasks = [(tg, tid, vec) for tg, group in envs.items() for tid, vec in group.items()]
+
+ # accumulators: track metrics at both per-group level and across all groups
+ group_acc: dict[str, dict[str, list]] = defaultdict(lambda: {k: [] for k in ACC_KEYS})
+ overall: dict[str, list] = {k: [] for k in ACC_KEYS}
+ per_task_infos: list[dict] = []
+
+ # small inline helper to accumulate one task's metrics into accumulators
+ def _accumulate_to(group: str, metrics: dict):
+ # metrics expected to contain 'sum_rewards', 'max_rewards', 'successes', optionally 'video_paths'
+ # but eval_one may store per-episode lists; we assume metrics uses scalars averaged per task as before.
+ # To be robust, accept scalars or lists.
+ def _append(key, value):
+ if value is None:
+ return
+ if isinstance(value, list):
+ group_acc[group][key].extend(value)
+ overall[key].extend(value)
+ else:
+ group_acc[group][key].append(value)
+ overall[key].append(value)
+
+ _append("sum_rewards", metrics.get("sum_rewards"))
+ _append("max_rewards", metrics.get("max_rewards"))
+ _append("successes", metrics.get("successes"))
+ # video_paths is list-like
+ paths = metrics.get("video_paths", [])
+ if paths:
+ group_acc[group]["video_paths"].extend(paths)
+ overall["video_paths"].extend(paths)
+
+ # Choose runner (sequential vs threaded)
+ task_runner = partial(
+ run_one,
+ policy=policy,
+ preprocessor=preprocessor,
+ postprocessor=postprocessor,
+ n_episodes=n_episodes,
+ max_episodes_rendered=max_episodes_rendered,
+ videos_dir=videos_dir,
+ return_episode_data=return_episode_data,
+ start_seed=start_seed,
+ )
+
+ if max_parallel_tasks <= 1:
+ # sequential path (single accumulator path on the main thread)
+ # NOTE: keeping a single-threaded accumulator avoids concurrent list appends or locks
+ for task_group, task_id, env in tasks:
+ tg, tid, metrics = task_runner(task_group, task_id, env)
+ _accumulate_to(tg, metrics)
+ per_task_infos.append({"task_group": tg, "task_id": tid, "metrics": metrics})
+ else:
+ # threaded path: submit all tasks, consume completions on main thread and accumulate there
+ with cf.ThreadPoolExecutor(max_workers=max_parallel_tasks) as executor:
+ fut2meta = {}
+ for task_group, task_id, env in tasks:
+ fut = executor.submit(task_runner, task_group, task_id, env)
+ fut2meta[fut] = (task_group, task_id)
+ for fut in cf.as_completed(fut2meta):
+ tg, tid, metrics = fut.result()
+ _accumulate_to(tg, metrics)
+ per_task_infos.append({"task_group": tg, "task_id": tid, "metrics": metrics})
+
+ # compute aggregated metrics helper (robust to lists/scalars)
+ def _agg_from_list(xs):
+ if not xs:
+ return float("nan")
+ arr = np.array(xs, dtype=float)
+ return float(np.nanmean(arr))
+
+ # compute per-group aggregates
+ groups_aggregated = {}
+ for group, acc in group_acc.items():
+ groups_aggregated[group] = {
+ "avg_sum_reward": _agg_from_list(acc["sum_rewards"]),
+ "avg_max_reward": _agg_from_list(acc["max_rewards"]),
+ "pc_success": _agg_from_list(acc["successes"]) * 100 if acc["successes"] else float("nan"),
+ "n_episodes": len(acc["sum_rewards"]),
+ "video_paths": list(acc["video_paths"]),
+ }
+
+ # overall aggregates
+ overall_agg = {
+ "avg_sum_reward": _agg_from_list(overall["sum_rewards"]),
+ "avg_max_reward": _agg_from_list(overall["max_rewards"]),
+ "pc_success": _agg_from_list(overall["successes"]) * 100 if overall["successes"] else float("nan"),
+ "n_episodes": len(overall["sum_rewards"]),
+ "eval_s": time.time() - start_t,
+ "eval_ep_s": (time.time() - start_t) / max(1, len(overall["sum_rewards"])),
+ "video_paths": list(overall["video_paths"]),
+ }
+
+ return {
+ "per_task": per_task_infos,
+ "per_group": groups_aggregated,
+ "overall": overall_agg,
+ }
+
+
def main():
init_logging()
eval_main()
diff --git a/src/lerobot/scripts/train.py b/src/lerobot/scripts/train.py
index 485fc9275..21da62bbb 100644
--- a/src/lerobot/scripts/train.py
+++ b/src/lerobot/scripts/train.py
@@ -30,11 +30,12 @@ from lerobot.datasets.factory import make_dataset
from lerobot.datasets.sampler import EpisodeAwareSampler
from lerobot.datasets.utils import cycle
from lerobot.envs.factory import make_env
+from lerobot.envs.utils import close_envs
from lerobot.optim.factory import make_optimizer_and_scheduler
from lerobot.policies.factory import make_policy, make_pre_post_processors
from lerobot.policies.pretrained import PreTrainedPolicy
from lerobot.policies.utils import get_device_from_parameters
-from lerobot.scripts.eval import eval_policy
+from lerobot.scripts.eval import eval_policy_all
from lerobot.utils.logging_utils import AverageMeter, MetricsTracker
from lerobot.utils.random_utils import set_seed
from lerobot.utils.train_utils import (
@@ -183,6 +184,9 @@ def train(cfg: TrainPipelineConfig):
# Only provide dataset_stats when not resuming from saved processor state
processor_kwargs["dataset_stats"] = dataset.meta.stats
+ if cfg.policy.pretrained_path is not None:
+ processor_kwargs["preprocessor_overrides"] = {"device_processor": {"device": device.type}}
+
preprocessor, postprocessor = make_pre_post_processors(
policy_cfg=cfg.policy, pretrained_path=cfg.policy.pretrained_path, **processor_kwargs
)
@@ -299,8 +303,8 @@ def train(cfg: TrainPipelineConfig):
torch.no_grad(),
torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext(),
):
- eval_info = eval_policy(
- env=eval_env,
+ eval_info = eval_policy_all(
+ envs=eval_env, # dict[suite][task_id] -> vec_env
policy=policy,
preprocessor=preprocessor,
postprocessor=postprocessor,
@@ -308,8 +312,16 @@ def train(cfg: TrainPipelineConfig):
videos_dir=cfg.output_dir / "eval" / f"videos_step_{step_id}",
max_episodes_rendered=4,
start_seed=cfg.seed,
+ max_parallel_tasks=cfg.env.max_parallel_tasks,
)
+ # overall metrics (suite-agnostic)
+ aggregated = eval_info["overall"]
+ # optional: per-suite logging
+ for suite, suite_info in eval_info.items():
+ logging.info("Suite %s aggregated: %s", suite, suite_info)
+
+ # meters/tracker
eval_metrics = {
"avg_sum_reward": AverageMeter("∑rwrd", ":.3f"),
"pc_success": AverageMeter("success", ":.1f"),
@@ -318,17 +330,16 @@ def train(cfg: TrainPipelineConfig):
eval_tracker = MetricsTracker(
cfg.batch_size, dataset.num_frames, dataset.num_episodes, eval_metrics, initial_step=step
)
- eval_tracker.eval_s = eval_info["aggregated"].pop("eval_s")
- eval_tracker.avg_sum_reward = eval_info["aggregated"].pop("avg_sum_reward")
- eval_tracker.pc_success = eval_info["aggregated"].pop("pc_success")
- logging.info(eval_tracker)
+ eval_tracker.eval_s = aggregated.pop("eval_s")
+ eval_tracker.avg_sum_reward = aggregated.pop("avg_sum_reward")
+ eval_tracker.pc_success = aggregated.pop("pc_success")
if wandb_logger:
wandb_log_dict = {**eval_tracker.to_dict(), **eval_info}
wandb_logger.log_dict(wandb_log_dict, step, mode="eval")
- wandb_logger.log_video(eval_info["video_paths"][0], step, mode="eval")
+ wandb_logger.log_video(eval_info["overall"]["video_paths"][0], step, mode="eval")
if eval_env:
- eval_env.close()
+ close_envs(eval_env)
logging.info("End of training")
if cfg.policy.push_to_hub:
diff --git a/tests/envs/test_envs.py b/tests/envs/test_envs.py
index 140e9dfb9..51ea564e5 100644
--- a/tests/envs/test_envs.py
+++ b/tests/envs/test_envs.py
@@ -46,7 +46,10 @@ def test_env(env_name, env_task, obs_type):
@require_env
def test_factory(env_name):
cfg = make_env_config(env_name)
- env = make_env(cfg, n_envs=1)
+ envs = make_env(cfg, n_envs=1)
+ suite_name = next(iter(envs))
+ task_id = next(iter(envs[suite_name]))
+ env = envs[suite_name][task_id]
obs, _ = env.reset()
obs = preprocess_observation(obs)
diff --git a/tests/examples/test_examples.py b/tests/examples/test_examples.py
deleted file mode 100644
index aabec69a6..000000000
--- a/tests/examples/test_examples.py
+++ /dev/null
@@ -1,147 +0,0 @@
-#!/usr/bin/env python
-
-# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import io
-import subprocess
-import sys
-from pathlib import Path
-
-import pytest
-
-from tests.fixtures.constants import DUMMY_REPO_ID
-from tests.utils import require_package
-
-
-def _find_and_replace(text: str, finds_and_replaces: list[tuple[str, str]]) -> str:
- for f, r in finds_and_replaces:
- assert f in text
- text = text.replace(f, r)
- return text
-
-
-# TODO(aliberts): Remove usage of subprocess calls and patch code with fixtures
-def _run_script(path):
- subprocess.run([sys.executable, path], check=True)
-
-
-def _read_file(path):
- with open(path) as file:
- return file.read()
-
-
-@pytest.mark.skip("TODO Fix and remove subprocess / excec calls")
-def test_example_1(tmp_path, lerobot_dataset_factory):
- _ = lerobot_dataset_factory(root=tmp_path, repo_id=DUMMY_REPO_ID)
- path = "examples/1_load_lerobot_dataset.py"
- file_contents = _read_file(path)
- file_contents = _find_and_replace(
- file_contents,
- [
- ('repo_id = "lerobot/pusht"', f'repo_id = "{DUMMY_REPO_ID}"'),
- (
- "LeRobotDataset(repo_id",
- f"LeRobotDataset(repo_id, root='{str(tmp_path)}'",
- ),
- ],
- )
- exec(file_contents, {})
- assert Path("outputs/examples/1_load_lerobot_dataset/episode_0.mp4").exists()
-
-
-@pytest.mark.skip("TODO Fix and remove subprocess / excec calls")
-@require_package("gym_pusht")
-def test_examples_basic2_basic3_advanced1():
- """
- Train a model with example 3, check the outputs.
- Evaluate the trained model with example 2, check the outputs.
- Calculate the validation loss with advanced example 1, check the outputs.
- """
-
- ### Test example 3
- file_contents = _read_file("examples/3_train_policy.py")
-
- # Do fewer steps, use smaller batch, use CPU, and don't complicate things with dataloader workers.
- file_contents = _find_and_replace(
- file_contents,
- [
- ("training_steps = 5000", "training_steps = 1"),
- ("num_workers=4", "num_workers=0"),
- ('device = torch.device("cuda")', 'device = torch.device("cpu")'),
- ("batch_size=64", "batch_size=1"),
- ],
- )
-
- # Pass empty globals to allow dictionary comprehension https://stackoverflow.com/a/32897127/4391249.
- exec(file_contents, {})
-
- for file_name in ["model.safetensors", "config.json"]:
- assert Path(f"outputs/train/example_pusht_diffusion/{file_name}").exists()
-
- ### Test example 2
- file_contents = _read_file("examples/2_evaluate_pretrained_policy.py")
-
- # Do fewer evals, use CPU, and use the local model.
- file_contents = _find_and_replace(
- file_contents,
- [
- (
- 'pretrained_policy_path = Path(snapshot_download("lerobot/diffusion_pusht"))',
- "",
- ),
- (
- '# pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")',
- 'pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")',
- ),
- ('device = torch.device("cuda")', 'device = torch.device("cpu")'),
- ("step += 1", "break"),
- ],
- )
-
- exec(file_contents, {})
-
- assert Path("outputs/eval/example_pusht_diffusion/rollout.mp4").exists()
-
- ## Test example 4
- file_contents = _read_file("examples/advanced/2_calculate_validation_loss.py")
-
- # Run on a single example from the last episode, use CPU, and use the local model.
- file_contents = _find_and_replace(
- file_contents,
- [
- (
- 'pretrained_policy_path = Path(snapshot_download("lerobot/diffusion_pusht"))',
- "",
- ),
- (
- '# pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")',
- 'pretrained_policy_path = Path("outputs/train/example_pusht_diffusion")',
- ),
- ("train_episodes = episodes[:num_train_episodes]", "train_episodes = [0]"),
- ("val_episodes = episodes[num_train_episodes:]", "val_episodes = [1]"),
- ("num_workers=4", "num_workers=0"),
- ('device = torch.device("cuda")', 'device = torch.device("cpu")'),
- ("batch_size=64", "batch_size=1"),
- ],
- )
-
- # Capture the output of the script
- output_buffer = io.StringIO()
- sys.stdout = output_buffer
- exec(file_contents, {})
- printed_output = output_buffer.getvalue()
- # Restore stdout to its original state
- sys.stdout = sys.__stdout__
- assert "Average loss on validation set" in printed_output
diff --git a/tests/policies/test_policies.py b/tests/policies/test_policies.py
index ef09bcd22..28c395bfc 100644
--- a/tests/policies/test_policies.py
+++ b/tests/policies/test_policies.py
@@ -159,7 +159,7 @@ def test_policy(ds_repo_id, env_name, env_kwargs, policy_name, policy_kwargs):
assert isinstance(policy, PreTrainedPolicy)
# Check that we run select_actions and get the appropriate output.
- env = make_env(train_cfg.env, n_envs=2)
+ envs = make_env(train_cfg.env, n_envs=2)
dataloader = torch.utils.data.DataLoader(
dataset,
@@ -188,6 +188,12 @@ def test_policy(ds_repo_id, env_name, env_kwargs, policy_name, policy_kwargs):
# reset the policy and environment
policy.reset()
+ # For testing purposes, we only need a single environment instance.
+ # So here we unwrap the first suite_name and first task_id to grab
+ # the actual env object (SyncVectorEnv) that exposes `.reset()`.
+ suite_name = next(iter(envs))
+ task_id = next(iter(envs[suite_name]))
+ env = envs[suite_name][task_id]
observation, _ = env.reset(seed=train_cfg.seed)
# apply transform to normalize the observations