mirror of
https://github.com/huggingface/lerobot.git
synced 2026-07-25 18:56:09 +00:00
Merge branch 'pr/1676' into feat/validate_pi_libero
This commit is contained in:
@@ -19,6 +19,8 @@
|
|||||||
title: Train RL in Simulation
|
title: Train RL in Simulation
|
||||||
- local: async
|
- local: async
|
||||||
title: Use Async Inference
|
title: Use Async Inference
|
||||||
|
- local: libero
|
||||||
|
title: Using LIBERO
|
||||||
title: "Tutorials"
|
title: "Tutorials"
|
||||||
- sections:
|
- sections:
|
||||||
- local: smolvla
|
- local: smolvla
|
||||||
|
|||||||
@@ -0,0 +1,230 @@
|
|||||||
|
# LIBERO
|
||||||
|
|
||||||
|
**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers. The benchmark was first introduced in the [LIBERO paper](https://arxiv.org/abs/2306.03310) and the [original repository](https://github.com/Lifelong-Robot-Learning/LIBERO).
|
||||||
|
|
||||||
|
To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
|
||||||
|
|
||||||
|
LIBERO includes **five task suites**:
|
||||||
|
|
||||||
|
- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
|
||||||
|
- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
|
||||||
|
- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
|
||||||
|
- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
|
||||||
|
- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
|
||||||
|
|
||||||
|
Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
|
||||||
|
|
||||||
|
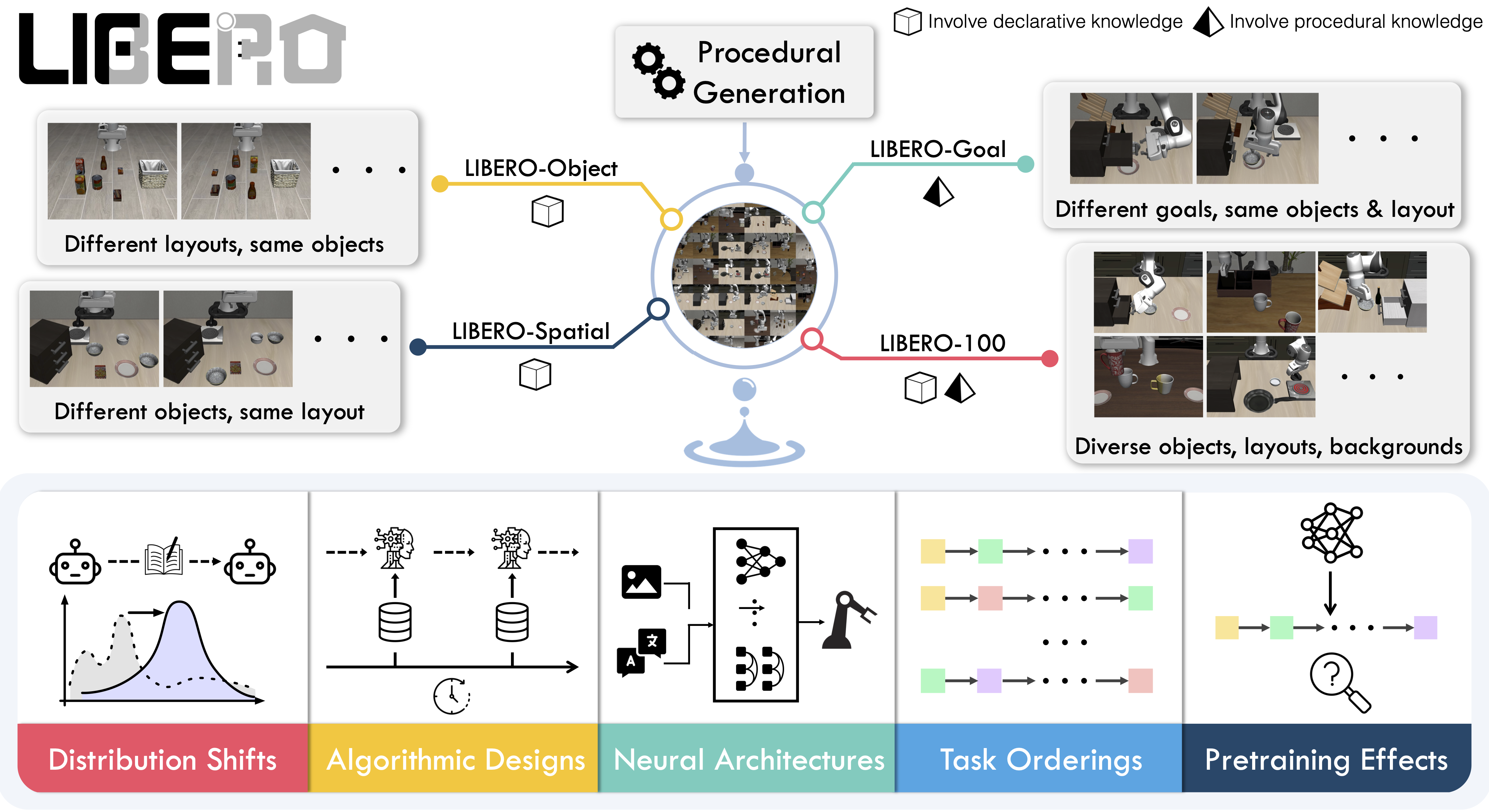
|
||||||
|
_Figure 1: An overview of the LIBERO benchmark._
|
||||||
|
|
||||||
|
## Evaluating with LIBERO
|
||||||
|
|
||||||
|
At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it primarily to **benchmark [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model, comparing it against state-of-the-art VLA models such as Pi0, OpenVLA, Octo, and Diffusion Policy.
|
||||||
|
|
||||||
|
LIBERO is now part of our **multi-eval supported simulation**, allowing you to benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a single flag.
|
||||||
|
|
||||||
|
To install LIBERO, first follow the [LeRobot Installation Guide](https://huggingface.co/docs/lerobot/installation).
|
||||||
|
Once LeRobot is installed, there are two options:
|
||||||
|
|
||||||
|
1. **Install via pip** (recommended):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install "lerobot[libero,smolvla]"
|
||||||
|
```
|
||||||
|
|
||||||
|
2. **Install from source**:
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/huggingface/lerobot.git
|
||||||
|
cd lerobot
|
||||||
|
pip install -e ".[libero,smolvla]"
|
||||||
|
```
|
||||||
|
|
||||||
|
### Single-suite evaluation
|
||||||
|
|
||||||
|
Evaluate a policy on one LIBERO suite:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python src/lerobot/scripts/eval.py \
|
||||||
|
--policy.path="your-policy-id" \
|
||||||
|
--env.type=libero \
|
||||||
|
--env.task=libero_object \
|
||||||
|
--env.multitask_eval=False \
|
||||||
|
--eval.batch_size=2 \
|
||||||
|
--eval.n_episodes=3
|
||||||
|
```
|
||||||
|
|
||||||
|
- `--env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
|
||||||
|
- `--eval.batch_size` controls how many environments run in parallel.
|
||||||
|
- `--eval.n_episodes` sets how many episodes to run in total.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Multi-suite evaluation
|
||||||
|
|
||||||
|
Benchmark a policy across multiple suites at once:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python src/lerobot/scripts/eval.py \
|
||||||
|
--policy.path="your-policy-id" \
|
||||||
|
--env.type=libero \
|
||||||
|
--env.task=libero_object \
|
||||||
|
--env.multitask_eval=True \
|
||||||
|
--eval.batch_size=1 \
|
||||||
|
--eval.n_episodes=2
|
||||||
|
```
|
||||||
|
|
||||||
|
- Pass a comma-separated list to `--env.task` for multi-suite evaluation.
|
||||||
|
- Set `-env.multitask_eval=True` to enable evaluation across all tasks in those suites.
|
||||||
|
|
||||||
|
### Policy inputs and outputs
|
||||||
|
|
||||||
|
When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
|
||||||
|
|
||||||
|
- **Observations**
|
||||||
|
- `observation.state` – proprioceptive features (agent state).
|
||||||
|
- `observation.images.image` – main camera view (`agentview_image`).
|
||||||
|
- `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
|
||||||
|
|
||||||
|
⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any visual features. Make sure your dataset metadata keys match this convention when evaluating.
|
||||||
|
|
||||||
|
## Input Features and Metadata Alignment
|
||||||
|
|
||||||
|
To train or evaluate a policy, you use `make_policy`, which builds a feature-naming dictionary for the observations the policy expects.
|
||||||
|
This mapping can come from:
|
||||||
|
- Dataset metadata
|
||||||
|
- The evaluation environment
|
||||||
|
- The policy path (if a pretrained repo ID is provided)
|
||||||
|
|
||||||
|
### Common Issues
|
||||||
|
|
||||||
|
A common problem is when the keys in the dataset, environment, and policy config do not match. For example:
|
||||||
|
- `wrist_image` vs `observation.images.image2`
|
||||||
|
- `observation.image2` (as in SmolVLA) vs the `.images.*` prefix convention
|
||||||
|
|
||||||
|
Such mismatches will cause `KeyError`s. This may be due to assumptions in `make_policy` or missing error handling.
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
### How to Check Expected Features
|
||||||
|
- Open your policy config (`config.json`), e.g. [example here](https://huggingface.co/jadechoghari/smolvla-libero/blob/main/config.json).
|
||||||
|
- Or add a breakpoint in `train.py` and inspect:
|
||||||
|
|
||||||
|
````python
|
||||||
|
print(policy.config.input_features)
|
||||||
|
To ensure you can just check what your policy expects as `input_features`:
|
||||||
|
|
||||||
|
- Open your policy config (`config.json`), e.g. [example here](https://huggingface.co/jadechoghari/smolvla-libero/blob/main/config.json).
|
||||||
|
- Or add a breakpoint in `train.py` and inspect:
|
||||||
|
```python
|
||||||
|
print(policy.config.input_features)
|
||||||
|
Fixing KeyErrors (Preprocessing Example)
|
||||||
|
````
|
||||||
|
|
||||||
|
## Fixing KeyErrors (Preprocessing Example)
|
||||||
|
|
||||||
|
If your dataset columns do not follow the expected naming, you can rename them in-place before training:
|
||||||
|
|
||||||
|
````python
|
||||||
|
import pyarrow.parquet as pq
|
||||||
|
import shutil
|
||||||
|
|
||||||
|
def rename_columns(parquet_path, rename_map):
|
||||||
|
table = pq.read_table(parquet_path)
|
||||||
|
schema = table.schema
|
||||||
|
new_names = [rename_map.get(name, name) for name in schema.names]
|
||||||
|
renamed_table = table.rename_columns(new_names)
|
||||||
|
backup_path = parquet_path + ".bak"
|
||||||
|
shutil.copy(parquet_path, backup_path)
|
||||||
|
pq.write_table(renamed_table, parquet_path)
|
||||||
|
print(f"patched {parquet_path}, backup at {backup_path}")
|
||||||
|
|
||||||
|
# example mapping: align dataset keys to LeRobot convention
|
||||||
|
rename_map = {
|
||||||
|
"image": "observation.images.image",
|
||||||
|
"wrist_image": "observation.images.image2",
|
||||||
|
}
|
||||||
|
|
||||||
|
rename_columns("episode_000001.parquet", rename_map)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
- **Actions**
|
||||||
|
- Continuous control values in a `Box(-1, 1, shape=(7,))` space.
|
||||||
|
|
||||||
|
We also provide a notebook for quick testing:
|
||||||
|
Training with LIBERO
|
||||||
|
|
||||||
|
## Training with LIBERO
|
||||||
|
|
||||||
|
When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
|
||||||
|
|
||||||
|
The environment expects:
|
||||||
|
|
||||||
|
- `observation.state` → 8-dim agent state
|
||||||
|
- `observation.images.image` → main camera (`agentview_image`)
|
||||||
|
- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
|
||||||
|
|
||||||
|
⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code. We plan to provide a script to easily preprocess such data.
|
||||||
|
To avoid potential mismatches and `KeyError`s, we provide a **preprocessed LIBERO dataset** that is fully compatible with the current LeRobot codebase and requires no additional manipulations.
|
||||||
|
|
||||||
|
- 🔗 [Preprocessed LIBERO dataset (Hugging Face LeRobot org)](https://huggingface.co/datasets/HuggingFaceVLA/libero)
|
||||||
|
- 🔗 [Original LIBERO dataset (physical-intelligence)](https://huggingface.co/datasets/physical-intelligence/libero)
|
||||||
|
|
||||||
|
The preprocessed dataset follows LeRobot naming conventions (e.g., `.images.*` prefix for visual features) and aligns with policy configs out-of-the-box.
|
||||||
|
The original dataset is acknowledged here as the primary source.
|
||||||
|
---
|
||||||
|
|
||||||
|
### Example training command
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python src/lerobot/scripts/train.py \
|
||||||
|
--policy.type=smolvla \
|
||||||
|
--policy.repo_id=${HF_USER}/libero-test \
|
||||||
|
--dataset.repo_id=jadechoghari/smol-libero3 \
|
||||||
|
--env.type=libero \
|
||||||
|
--env.task=libero_10 \
|
||||||
|
--output_dir=./outputs/ \
|
||||||
|
--steps=100000 \
|
||||||
|
--batch_size=4 \
|
||||||
|
--env.multitask_eval=True \
|
||||||
|
--eval.batch_size=1 \
|
||||||
|
--eval.n_episodes=1 \
|
||||||
|
--eval_freq=1000 \
|
||||||
|
````
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Note on rendering
|
||||||
|
|
||||||
|
LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
|
||||||
|
|
||||||
|
- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Colab Note on Parallel Evaluation
|
||||||
|
|
||||||
|
When running evaluation on Colab, you may encounter warnings such as:
|
||||||
|
|
||||||
|
```
|
||||||
|
UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
|
||||||
|
```
|
||||||
|
|
||||||
|
This happens because Colab’s rendering contexts are **not thread-safe**, and `ThreadPoolExecutor(max_workers=num_workers)` can trigger segfaults or leaked semaphore warnings.
|
||||||
|
|
||||||
|
**Colab Note:**
|
||||||
|
Parallel evaluation is not supported in Colab. To avoid these issues, run sequentially or disable multitask evaluation:
|
||||||
|
|
||||||
|
Run sequentially:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--env.max_parallel_tasks=1
|
||||||
|
```
|
||||||
|
|
||||||
|
Or disable multitask evaluation:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--env.multitask_eval=False
|
||||||
|
```
|
||||||
|
|
||||||
|
If you want to take advantage of **parallel evaluation**, we recommend **not using Colab**. Instead, run locally or on a proper compute environment where multi-threaded rendering is easily supported.
|
||||||
+22
-2
@@ -135,7 +135,26 @@ video_benchmark = ["scikit-image>=0.23.2", "pandas>=2.2.2"]
|
|||||||
aloha = ["gym-aloha>=0.1.1"]
|
aloha = ["gym-aloha>=0.1.1"]
|
||||||
pusht = ["gym-pusht>=0.1.5", "pymunk>=6.6.0,<7.0.0"] # TODO: Fix pymunk version in gym-pusht instead
|
pusht = ["gym-pusht>=0.1.5", "pymunk>=6.6.0,<7.0.0"] # TODO: Fix pymunk version in gym-pusht instead
|
||||||
xarm = ["gym-xarm>=0.1.1"]
|
xarm = ["gym-xarm>=0.1.1"]
|
||||||
|
libero = [
|
||||||
|
"hydra-core>=1.2,<1.4",
|
||||||
|
"numpy",
|
||||||
|
"wandb",
|
||||||
|
"easydict",
|
||||||
|
"transformers",
|
||||||
|
"opencv-python",
|
||||||
|
"robomimic==0.2.0",
|
||||||
|
"einops",
|
||||||
|
"thop",
|
||||||
|
"robosuite==1.4.0",
|
||||||
|
"mujoco>=2.3.7,<3.0.0",
|
||||||
|
"bddl==1.0.1",
|
||||||
|
"matplotlib",
|
||||||
|
"cloudpickle",
|
||||||
|
"future",
|
||||||
|
"gym",
|
||||||
|
"egl_probe @ git+https://github.com/jadechoghari/egl_probe.git#egg=egl_probe",
|
||||||
|
"libero @ git+https://github.com/jadechoghari/LIBERO.git@main#egg=libero",
|
||||||
|
]
|
||||||
# All
|
# All
|
||||||
all = [
|
all = [
|
||||||
"lerobot[dynamixel]",
|
"lerobot[dynamixel]",
|
||||||
@@ -154,7 +173,8 @@ all = [
|
|||||||
"lerobot[video_benchmark]",
|
"lerobot[video_benchmark]",
|
||||||
"lerobot[aloha]",
|
"lerobot[aloha]",
|
||||||
"lerobot[pusht]",
|
"lerobot[pusht]",
|
||||||
"lerobot[xarm]"
|
"lerobot[xarm]",
|
||||||
|
"lerobot[libero]"
|
||||||
]
|
]
|
||||||
|
|
||||||
[project.scripts]
|
[project.scripts]
|
||||||
|
|||||||
@@ -30,6 +30,8 @@ class EnvConfig(draccus.ChoiceRegistry, abc.ABC):
|
|||||||
fps: int = 30
|
fps: int = 30
|
||||||
features: dict[str, PolicyFeature] = field(default_factory=dict)
|
features: dict[str, PolicyFeature] = field(default_factory=dict)
|
||||||
features_map: dict[str, str] = field(default_factory=dict)
|
features_map: dict[str, str] = field(default_factory=dict)
|
||||||
|
multitask_eval: bool = False
|
||||||
|
max_parallel_tasks: int = 5
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def type(self) -> str:
|
def type(self) -> str:
|
||||||
@@ -271,3 +273,55 @@ class HILEnvConfig(EnvConfig):
|
|||||||
"use_gamepad": self.use_gamepad,
|
"use_gamepad": self.use_gamepad,
|
||||||
"gripper_penalty": self.gripper_penalty,
|
"gripper_penalty": self.gripper_penalty,
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
|
@EnvConfig.register_subclass("libero")
|
||||||
|
@dataclass
|
||||||
|
class LiberoEnv(EnvConfig):
|
||||||
|
task: str = "libero_10" # can also choose libero_spatial, libero_object, etc.
|
||||||
|
fps: int = 30
|
||||||
|
episode_length: int = 520
|
||||||
|
obs_type: str = "pixels_agent_pos"
|
||||||
|
render_mode: str = "rgb_array"
|
||||||
|
camera_name: str = "agentview_image,robot0_eye_in_hand_image"
|
||||||
|
init_states: bool = True
|
||||||
|
multitask_eval: bool = True
|
||||||
|
features: dict[str, PolicyFeature] = field(
|
||||||
|
default_factory=lambda: {
|
||||||
|
"action": PolicyFeature(type=FeatureType.ACTION, shape=(7,)),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
features_map: dict[str, str] = field(
|
||||||
|
default_factory=lambda: {
|
||||||
|
"action": ACTION,
|
||||||
|
"agent_pos": OBS_STATE,
|
||||||
|
"pixels/agentview_image": f"{OBS_IMAGES}.image",
|
||||||
|
"pixels/robot0_eye_in_hand_image": f"{OBS_IMAGES}.image2",
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
def __post_init__(self):
|
||||||
|
if self.obs_type == "pixels":
|
||||||
|
self.features["pixels/agentview_image"] = PolicyFeature(
|
||||||
|
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||||
|
)
|
||||||
|
self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
|
||||||
|
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||||
|
)
|
||||||
|
elif self.obs_type == "pixels_agent_pos":
|
||||||
|
self.features["agent_pos"] = PolicyFeature(type=FeatureType.STATE, shape=(8,))
|
||||||
|
self.features["pixels/agentview_image"] = PolicyFeature(
|
||||||
|
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||||
|
)
|
||||||
|
self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
|
||||||
|
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||||
|
)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def gym_kwargs(self) -> dict:
|
||||||
|
return {
|
||||||
|
# "task": self.task,
|
||||||
|
"obs_type": self.obs_type,
|
||||||
|
"render_mode": self.render_mode,
|
||||||
|
# "max_episode_steps": self.episode_length,
|
||||||
|
}
|
||||||
|
|||||||
@@ -17,7 +17,7 @@ import importlib
|
|||||||
|
|
||||||
import gymnasium as gym
|
import gymnasium as gym
|
||||||
|
|
||||||
from lerobot.envs.configs import AlohaEnv, EnvConfig, HILEnvConfig, PushtEnv, XarmEnv
|
from lerobot.envs.configs import AlohaEnv, EnvConfig, HILEnvConfig, LiberoEnv, PushtEnv, XarmEnv
|
||||||
|
|
||||||
|
|
||||||
def make_env_config(env_type: str, **kwargs) -> EnvConfig:
|
def make_env_config(env_type: str, **kwargs) -> EnvConfig:
|
||||||
@@ -29,11 +29,15 @@ def make_env_config(env_type: str, **kwargs) -> EnvConfig:
|
|||||||
return XarmEnv(**kwargs)
|
return XarmEnv(**kwargs)
|
||||||
elif env_type == "hil":
|
elif env_type == "hil":
|
||||||
return HILEnvConfig(**kwargs)
|
return HILEnvConfig(**kwargs)
|
||||||
|
elif env_type == "libero":
|
||||||
|
return LiberoEnv(**kwargs)
|
||||||
else:
|
else:
|
||||||
raise ValueError(f"Policy type '{env_type}' is not available.")
|
raise ValueError(f"Policy type '{env_type}' is not available.")
|
||||||
|
|
||||||
|
|
||||||
def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> gym.vector.VectorEnv | None:
|
def make_env(
|
||||||
|
cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False
|
||||||
|
) -> gym.vector.VectorEnv | dict[str, dict[int, gym.vector.VectorEnv]]:
|
||||||
"""Makes a gym vector environment according to the config.
|
"""Makes a gym vector environment according to the config.
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
@@ -48,22 +52,39 @@ def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> g
|
|||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
gym.vector.VectorEnv: The parallelized gym.env instance.
|
gym.vector.VectorEnv: The parallelized gym.env instance.
|
||||||
|
dict[str, dict[int, gym.vector.VectorEnv]]: A mapping from task suite
|
||||||
|
names to indexed vectorized environments (when multitask eval is used).
|
||||||
|
|
||||||
"""
|
"""
|
||||||
if n_envs < 1:
|
if n_envs < 1:
|
||||||
raise ValueError("`n_envs must be at least 1")
|
raise ValueError("`n_envs must be at least 1")
|
||||||
|
|
||||||
package_name = f"gym_{cfg.type}"
|
# batched version of the env that returns an observation of shape (b, c)
|
||||||
|
env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
|
||||||
|
|
||||||
|
if "libero" in cfg.type:
|
||||||
|
from lerobot.envs.libero import create_libero_envs
|
||||||
|
|
||||||
|
env = create_libero_envs(
|
||||||
|
task=cfg.task,
|
||||||
|
n_envs=n_envs,
|
||||||
|
camera_name=cfg.camera_name,
|
||||||
|
init_states=cfg.init_states,
|
||||||
|
gym_kwargs=cfg.gym_kwargs,
|
||||||
|
env_cls=env_cls,
|
||||||
|
multitask_eval=cfg.multitask_eval,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
package_name = f"gym_{cfg.type}"
|
||||||
try:
|
try:
|
||||||
importlib.import_module(package_name)
|
importlib.import_module(package_name)
|
||||||
except ModuleNotFoundError as e:
|
except ModuleNotFoundError as e:
|
||||||
print(f"{package_name} is not installed. Please install it with `pip install 'lerobot[{cfg.type}]'`")
|
print(
|
||||||
|
f"{package_name} is not installed. Please install it with `pip install 'lerobot[{cfg.type}]'`"
|
||||||
|
)
|
||||||
raise e
|
raise e
|
||||||
|
|
||||||
gym_handle = f"{package_name}/{cfg.task}"
|
gym_handle = f"{package_name}/{cfg.task}"
|
||||||
|
|
||||||
# batched version of the env that returns an observation of shape (b, c)
|
|
||||||
env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
|
|
||||||
env = env_cls(
|
env = env_cls(
|
||||||
[lambda: gym.make(gym_handle, disable_env_checker=True, **cfg.gym_kwargs) for _ in range(n_envs)]
|
[lambda: gym.make(gym_handle, disable_env_checker=True, **cfg.gym_kwargs) for _ in range(n_envs)]
|
||||||
)
|
)
|
||||||
|
|||||||
@@ -0,0 +1,325 @@
|
|||||||
|
import math
|
||||||
|
import os
|
||||||
|
from collections import defaultdict
|
||||||
|
from collections.abc import Callable
|
||||||
|
from itertools import chain
|
||||||
|
from typing import Any
|
||||||
|
|
||||||
|
import gymnasium as gym
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
from gymnasium import spaces
|
||||||
|
from libero.libero import benchmark, get_libero_path
|
||||||
|
from libero.libero.envs import OffScreenRenderEnv
|
||||||
|
|
||||||
|
|
||||||
|
def create_libero_envs(
|
||||||
|
task: str,
|
||||||
|
n_envs: int,
|
||||||
|
gym_kwargs: dict[str, Any] = None,
|
||||||
|
camera_name: str = "agentview_image,robot0_eye_in_hand_image",
|
||||||
|
init_states: bool = True,
|
||||||
|
env_cls: Callable = None,
|
||||||
|
multitask_eval: bool = True,
|
||||||
|
) -> dict[str, dict[str, Any]]:
|
||||||
|
"""
|
||||||
|
Here n_envs is per task and equal to the number of rollouts.
|
||||||
|
Returns:
|
||||||
|
dict[str, dict[str, list[LiberoEnv]]]: keys are task_suite and values are list of LiberoEnv envs.
|
||||||
|
"""
|
||||||
|
print("num envs", n_envs)
|
||||||
|
print("multitask_eval", multitask_eval)
|
||||||
|
print("gym_kwargs", gym_kwargs)
|
||||||
|
if gym_kwargs is None:
|
||||||
|
gym_kwargs = {}
|
||||||
|
|
||||||
|
if not multitask_eval:
|
||||||
|
benchmark_dict = benchmark.get_benchmark_dict()
|
||||||
|
task_suite = benchmark_dict[task]() # can also choose libero_spatial, libero_object, libero_10 etc.
|
||||||
|
tasks_id = list(range(len(task_suite.tasks)))
|
||||||
|
episode_indices = [0 for i in range(len(tasks_id))]
|
||||||
|
if len(tasks_id) == 1:
|
||||||
|
tasks_id = [tasks_id[0] for _ in range(n_envs)]
|
||||||
|
episode_indices = list(range(n_envs))
|
||||||
|
elif len(tasks_id) < n_envs and n_envs % len(tasks_id) == 0:
|
||||||
|
n_repeat = n_envs // len(tasks_id)
|
||||||
|
print("n_repeat", n_repeat)
|
||||||
|
episode_indices = []
|
||||||
|
for _ in range(len(tasks_id)):
|
||||||
|
episode_indices.extend(list(range(n_repeat)))
|
||||||
|
tasks_id = list(chain.from_iterable([[item] * n_repeat for item in tasks_id]))
|
||||||
|
elif n_envs < len(tasks_id):
|
||||||
|
tasks_id = tasks_id[:n_envs]
|
||||||
|
episode_indices = list(range(n_envs))[:n_envs]
|
||||||
|
print(f"WARNING: n_envs < len(tasks_id), evaluating only on {tasks_id}")
|
||||||
|
print(f"Creating Libero envs with task ids {tasks_id} from suite {task}")
|
||||||
|
assert n_envs == len(tasks_id), (
|
||||||
|
f"len(n_envs) and tasks_id should be the same, got {n_envs} and {len(tasks_id)}"
|
||||||
|
)
|
||||||
|
return env_cls(
|
||||||
|
[
|
||||||
|
lambda i=i: LiberoEnv(
|
||||||
|
task_suite=task_suite,
|
||||||
|
task_id=tasks_id[i],
|
||||||
|
task_suite_name=task,
|
||||||
|
camera_name=camera_name,
|
||||||
|
init_states=init_states,
|
||||||
|
episode_index=episode_indices[i],
|
||||||
|
**gym_kwargs,
|
||||||
|
)
|
||||||
|
for i in range(n_envs)
|
||||||
|
]
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
envs = defaultdict(dict)
|
||||||
|
benchmark_dict = benchmark.get_benchmark_dict()
|
||||||
|
task = task.split(",")
|
||||||
|
for _task in task:
|
||||||
|
task_suite = benchmark_dict[
|
||||||
|
_task
|
||||||
|
]() # can also choose libero_spatial, libero_object, libero_10 etc.
|
||||||
|
tasks_ids = list(range(len(task_suite.tasks)))
|
||||||
|
for tasks_id in tasks_ids:
|
||||||
|
episode_indices = list(range(n_envs))
|
||||||
|
print(
|
||||||
|
f"Creating Libero envs with task ids {tasks_id} from suite {_task}, episode_indices: {episode_indices}"
|
||||||
|
)
|
||||||
|
envs_list = [
|
||||||
|
(
|
||||||
|
lambda i=i,
|
||||||
|
task_suite=task_suite,
|
||||||
|
tasks_id=tasks_id,
|
||||||
|
_task=_task,
|
||||||
|
episode_indices=episode_indices: LiberoEnv(
|
||||||
|
task_suite=task_suite,
|
||||||
|
task_id=tasks_id,
|
||||||
|
task_suite_name=_task,
|
||||||
|
camera_name=camera_name,
|
||||||
|
init_states=init_states,
|
||||||
|
episode_index=episode_indices[i],
|
||||||
|
**gym_kwargs,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
for i in range(n_envs)
|
||||||
|
]
|
||||||
|
envs[_task][tasks_id] = env_cls(envs_list)
|
||||||
|
return envs
|
||||||
|
|
||||||
|
|
||||||
|
def quat2axisangle(quat):
|
||||||
|
"""
|
||||||
|
Copied from robosuite: https://github.com/ARISE-Initiative/robosuite/blob/eafb81f54ffc104f905ee48a16bb15f059176ad3/robosuite/utils/transform_utils.py#L490C1-L512C55
|
||||||
|
|
||||||
|
Converts quaternion to axis-angle format.
|
||||||
|
Returns a unit vector direction scaled by its angle in radians.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
quat (np.array): (x,y,z,w) vec4 float angles
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
np.array: (ax,ay,az) axis-angle exponential coordinates
|
||||||
|
"""
|
||||||
|
# clip quaternion
|
||||||
|
if quat[3] > 1.0:
|
||||||
|
quat[3] = 1.0
|
||||||
|
elif quat[3] < -1.0:
|
||||||
|
quat[3] = -1.0
|
||||||
|
|
||||||
|
den = np.sqrt(1.0 - quat[3] * quat[3])
|
||||||
|
if math.isclose(den, 0.0):
|
||||||
|
# This is (close to) a zero degree rotation, immediately return
|
||||||
|
return np.zeros(3)
|
||||||
|
|
||||||
|
return (quat[:3] * 2.0 * math.acos(quat[3])) / den
|
||||||
|
|
||||||
|
|
||||||
|
def get_task_init_states(task_suite, i):
|
||||||
|
init_states_path = os.path.join(
|
||||||
|
get_libero_path("init_states"),
|
||||||
|
task_suite.tasks[i].problem_folder,
|
||||||
|
task_suite.tasks[i].init_states_file,
|
||||||
|
)
|
||||||
|
init_states = torch.load(init_states_path, weights_only=False) # nosec B614
|
||||||
|
return init_states
|
||||||
|
|
||||||
|
|
||||||
|
def get_libero_dummy_action():
|
||||||
|
"""Get dummy/no-op action, used to roll out the simulation while the robot does nothing."""
|
||||||
|
return [0, 0, 0, 0, 0, 0, -1]
|
||||||
|
|
||||||
|
|
||||||
|
OBS_STATE_DIM = 8
|
||||||
|
ACTION_DIM = 7
|
||||||
|
|
||||||
|
|
||||||
|
class LiberoEnv(gym.Env):
|
||||||
|
metadata = {"render_modes": ["rgb_array"], "render_fps": 80}
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
task_suite,
|
||||||
|
task_id,
|
||||||
|
task_suite_name,
|
||||||
|
camera_name="agentview_image,robot0_eye_in_hand_image",
|
||||||
|
obs_type="pixels",
|
||||||
|
render_mode="rgb_array",
|
||||||
|
observation_width=256,
|
||||||
|
observation_height=256,
|
||||||
|
visualization_width=640,
|
||||||
|
visualization_height=480,
|
||||||
|
init_states=True,
|
||||||
|
episode_index=0,
|
||||||
|
):
|
||||||
|
super().__init__()
|
||||||
|
self.task_id = task_id
|
||||||
|
self.obs_type = obs_type
|
||||||
|
self.render_mode = render_mode
|
||||||
|
self.observation_width = observation_width
|
||||||
|
self.observation_height = observation_height
|
||||||
|
self.visualization_width = visualization_width
|
||||||
|
self.visualization_height = visualization_height
|
||||||
|
self.init_states = init_states
|
||||||
|
self.camera_name = camera_name.split(
|
||||||
|
","
|
||||||
|
) # agentview_image (main) or robot0_eye_in_hand_image (wrist)
|
||||||
|
|
||||||
|
# Map raw camera names to "image1" and "image2".
|
||||||
|
# The preprocessing step `preprocess_observation` will then prefix these with `.images.*`,
|
||||||
|
# following the LeRobot convention (e.g., `observation.images.image`, `observation.images.image2`).
|
||||||
|
# This ensures the policy consistently receives observations in the
|
||||||
|
# expected format regardless of the original camera naming.
|
||||||
|
self.camera_name_mapping = {
|
||||||
|
"agentview_image": "image",
|
||||||
|
"robot0_eye_in_hand_image": "image2",
|
||||||
|
}
|
||||||
|
|
||||||
|
self.num_steps_wait = (
|
||||||
|
10 # Do nothing for the first few timesteps to wait for the simulator drops objects
|
||||||
|
)
|
||||||
|
self.episode_index = episode_index
|
||||||
|
|
||||||
|
self._env = self._make_envs_task(task_suite, self.task_id)
|
||||||
|
if task_suite_name == "libero_spatial":
|
||||||
|
max_steps = 220 # longest training demo has 193 steps
|
||||||
|
elif task_suite_name == "libero_object":
|
||||||
|
max_steps = 280 # longest training demo has 254 steps
|
||||||
|
elif task_suite_name == "libero_goal":
|
||||||
|
max_steps = 300 # longest training demo has 270 steps
|
||||||
|
elif task_suite_name == "libero_10":
|
||||||
|
max_steps = 520 # longest training demo has 505 steps
|
||||||
|
elif task_suite_name == "libero_90":
|
||||||
|
max_steps = 400 # longest training demo has 373 steps
|
||||||
|
self._max_episode_steps = max_steps
|
||||||
|
|
||||||
|
images = {}
|
||||||
|
for cam in self.camera_name:
|
||||||
|
images[self.camera_name_mapping[cam]] = spaces.Box(
|
||||||
|
low=0,
|
||||||
|
high=255,
|
||||||
|
shape=(self.observation_height, self.observation_width, 3),
|
||||||
|
dtype=np.uint8,
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.obs_type == "state":
|
||||||
|
raise NotImplementedError()
|
||||||
|
elif self.obs_type == "pixels":
|
||||||
|
self.observation_space = spaces.Dict(
|
||||||
|
{
|
||||||
|
"pixels": spaces.Dict(images),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
elif self.obs_type == "pixels_agent_pos":
|
||||||
|
self.observation_space = spaces.Dict(
|
||||||
|
{
|
||||||
|
"pixels": spaces.Dict(images),
|
||||||
|
"agent_pos": spaces.Box(
|
||||||
|
low=-1000.0,
|
||||||
|
high=1000.0,
|
||||||
|
shape=(OBS_STATE_DIM,),
|
||||||
|
dtype=np.float64,
|
||||||
|
),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
self.action_space = spaces.Box(low=-1, high=1, shape=(ACTION_DIM,), dtype=np.float32)
|
||||||
|
|
||||||
|
def render(self):
|
||||||
|
raw_obs = self._env.env._get_observations()
|
||||||
|
formatted = self._format_raw_obs(raw_obs)
|
||||||
|
# grab the "main" camera
|
||||||
|
return formatted["pixels"]["image"]
|
||||||
|
|
||||||
|
def _make_envs_task(self, task_suite, task_id: int = 0):
|
||||||
|
task = task_suite.get_task(task_id)
|
||||||
|
self.task = task.name
|
||||||
|
self.task_description = task.language
|
||||||
|
task_bddl_file = os.path.join(get_libero_path("bddl_files"), task.problem_folder, task.bddl_file)
|
||||||
|
|
||||||
|
env_args = {
|
||||||
|
"bddl_file_name": task_bddl_file,
|
||||||
|
"camera_heights": self.observation_height,
|
||||||
|
"camera_widths": self.observation_width,
|
||||||
|
}
|
||||||
|
env = OffScreenRenderEnv(**env_args)
|
||||||
|
env.reset()
|
||||||
|
if self.init_states:
|
||||||
|
init_states = get_task_init_states(
|
||||||
|
task_suite, task_id
|
||||||
|
) # for benchmarking purpose, we fix the a set of initial states FIXME(mshukor): should be in the reset()?
|
||||||
|
init_state_id = self.episode_index # episode index
|
||||||
|
env.set_init_state(init_states[init_state_id])
|
||||||
|
|
||||||
|
return env
|
||||||
|
|
||||||
|
def _format_raw_obs(self, raw_obs):
|
||||||
|
images = {}
|
||||||
|
for camera_name in self.camera_name:
|
||||||
|
image = raw_obs[camera_name]
|
||||||
|
image = image[::-1, ::-1] # rotate 180 degrees
|
||||||
|
images[self.camera_name_mapping[camera_name]] = image
|
||||||
|
# images = image if len(images) == 1 else images
|
||||||
|
state = np.concatenate(
|
||||||
|
(
|
||||||
|
raw_obs["robot0_eef_pos"],
|
||||||
|
quat2axisangle(raw_obs["robot0_eef_quat"]),
|
||||||
|
raw_obs["robot0_gripper_qpos"],
|
||||||
|
)
|
||||||
|
)
|
||||||
|
agent_pos = state
|
||||||
|
if self.obs_type == "state":
|
||||||
|
raise NotImplementedError()
|
||||||
|
elif self.obs_type == "pixels":
|
||||||
|
obs = {"pixels": images.copy()}
|
||||||
|
elif self.obs_type == "pixels_agent_pos":
|
||||||
|
obs = {
|
||||||
|
"pixels": images.copy(),
|
||||||
|
"agent_pos": agent_pos,
|
||||||
|
}
|
||||||
|
return obs
|
||||||
|
|
||||||
|
def reset(self, seed=None, **kwargs):
|
||||||
|
super().reset(seed=seed)
|
||||||
|
|
||||||
|
self._env.seed(seed)
|
||||||
|
raw_obs = self._env.reset()
|
||||||
|
# Do nothing for the first few timesteps to wait for the simulator drops objects
|
||||||
|
for _ in range(self.num_steps_wait):
|
||||||
|
raw_obs, _, _, _ = self._env.step(get_libero_dummy_action())
|
||||||
|
observation = self._format_raw_obs(raw_obs)
|
||||||
|
info = {"is_success": False}
|
||||||
|
return observation, info
|
||||||
|
|
||||||
|
def step(self, action):
|
||||||
|
assert action.ndim == 1
|
||||||
|
action[-1] = 1.0 - action[-1]
|
||||||
|
raw_obs, reward, done, info = self._env.step(action)
|
||||||
|
is_success = self._env.check_success()
|
||||||
|
terminated = done or is_success
|
||||||
|
info["is_success"] = is_success
|
||||||
|
observation = self._format_raw_obs(raw_obs)
|
||||||
|
truncated = False
|
||||||
|
# note if it is unable to complete get libero error after many steps
|
||||||
|
return observation, reward, terminated, truncated, info
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
self._env.close()
|
||||||
+166
-12
@@ -46,6 +46,7 @@ Note that in both examples, the repo/folder should contain at least `config.json
|
|||||||
You can learn about the CLI options for this script in the `EvalPipelineConfig` in lerobot/configs/eval.py
|
You can learn about the CLI options for this script in the `EvalPipelineConfig` in lerobot/configs/eval.py
|
||||||
"""
|
"""
|
||||||
|
|
||||||
|
import concurrent
|
||||||
import json
|
import json
|
||||||
import logging
|
import logging
|
||||||
import threading
|
import threading
|
||||||
@@ -145,7 +146,7 @@ def rollout(
|
|||||||
leave=False,
|
leave=False,
|
||||||
)
|
)
|
||||||
check_env_attributes_and_types(env)
|
check_env_attributes_and_types(env)
|
||||||
while not np.all(done):
|
while not np.all(done) and step < max_steps:
|
||||||
# Numpy array to tensor and changing dictionary keys to LeRobot policy format.
|
# Numpy array to tensor and changing dictionary keys to LeRobot policy format.
|
||||||
observation = preprocess_observation(observation)
|
observation = preprocess_observation(observation)
|
||||||
if return_observations:
|
if return_observations:
|
||||||
@@ -158,10 +159,8 @@ def rollout(
|
|||||||
# Infer "task" from attributes of environments.
|
# Infer "task" from attributes of environments.
|
||||||
# TODO: works with SyncVectorEnv but not AsyncVectorEnv
|
# TODO: works with SyncVectorEnv but not AsyncVectorEnv
|
||||||
observation = add_envs_task(env, observation)
|
observation = add_envs_task(env, observation)
|
||||||
|
|
||||||
with torch.inference_mode():
|
with torch.inference_mode():
|
||||||
action = policy.select_action(observation)
|
action = policy.select_action(observation)
|
||||||
|
|
||||||
# Convert to CPU / numpy.
|
# Convert to CPU / numpy.
|
||||||
action = action.to("cpu").numpy()
|
action = action.to("cpu").numpy()
|
||||||
assert action.ndim == 2, "Action dimensions should be (batch, action_dim)"
|
assert action.ndim == 2, "Action dimensions should be (batch, action_dim)"
|
||||||
@@ -179,7 +178,12 @@ def rollout(
|
|||||||
successes = [False] * env.num_envs
|
successes = [False] * env.num_envs
|
||||||
|
|
||||||
# Keep track of which environments are done so far.
|
# Keep track of which environments are done so far.
|
||||||
|
# Mark the episode as done if we reach the maximum step limit.
|
||||||
|
# This ensures that the rollout always terminates cleanly at `max_steps`,
|
||||||
|
# and allows logging/saving (e.g., videos) to be triggered consistently.
|
||||||
done = terminated | truncated | done
|
done = terminated | truncated | done
|
||||||
|
if step + 1 == max_steps:
|
||||||
|
done = np.ones_like(done, dtype=bool)
|
||||||
|
|
||||||
all_actions.append(torch.from_numpy(action))
|
all_actions.append(torch.from_numpy(action))
|
||||||
all_rewards.append(torch.from_numpy(reward))
|
all_rewards.append(torch.from_numpy(reward))
|
||||||
@@ -402,7 +406,6 @@ def eval_policy(
|
|||||||
"eval_ep_s": (time.time() - start) / n_episodes,
|
"eval_ep_s": (time.time() - start) / n_episodes,
|
||||||
},
|
},
|
||||||
}
|
}
|
||||||
|
|
||||||
if return_episode_data:
|
if return_episode_data:
|
||||||
info["episodes"] = episode_data
|
info["episodes"] = episode_data
|
||||||
|
|
||||||
@@ -474,14 +477,36 @@ def eval_main(cfg: EvalPipelineConfig):
|
|||||||
env = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
|
env = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
|
||||||
|
|
||||||
logging.info("Making policy.")
|
logging.info("Making policy.")
|
||||||
|
|
||||||
policy = make_policy(
|
policy = make_policy(
|
||||||
cfg=cfg.policy,
|
cfg=cfg.policy,
|
||||||
env_cfg=cfg.env,
|
env_cfg=cfg.env,
|
||||||
)
|
)
|
||||||
policy.eval()
|
policy.eval()
|
||||||
|
|
||||||
with torch.no_grad(), torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext():
|
with torch.no_grad(), torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext():
|
||||||
|
if cfg.env.multitask_eval:
|
||||||
|
info = eval_policy_multitask(
|
||||||
|
env,
|
||||||
|
policy,
|
||||||
|
cfg.eval.n_episodes,
|
||||||
|
max_episodes_rendered=10,
|
||||||
|
videos_dir=Path(cfg.output_dir) / "videos",
|
||||||
|
start_seed=cfg.seed,
|
||||||
|
max_parallel_tasks=cfg.env.max_parallel_tasks,
|
||||||
|
verbose=False,
|
||||||
|
)
|
||||||
|
print("Overall Aggregated Metrics:")
|
||||||
|
print(info["overall"]["aggregated"])
|
||||||
|
|
||||||
|
# Print per-suite stats
|
||||||
|
for task_group, task_group_info in info.items():
|
||||||
|
if task_group == "overall":
|
||||||
|
continue # Skip the overall stats since we already printed it
|
||||||
|
print(f"\nAggregated Metrics for {task_group}:")
|
||||||
|
print(task_group_info["aggregated"])
|
||||||
|
for _task_group, v in env.items():
|
||||||
|
for _env in v.values():
|
||||||
|
_env.close()
|
||||||
|
else:
|
||||||
info = eval_policy(
|
info = eval_policy(
|
||||||
env,
|
env,
|
||||||
policy,
|
policy,
|
||||||
@@ -491,20 +516,149 @@ def eval_main(cfg: EvalPipelineConfig):
|
|||||||
start_seed=cfg.seed,
|
start_seed=cfg.seed,
|
||||||
)
|
)
|
||||||
print(info["aggregated"])
|
print(info["aggregated"])
|
||||||
|
env.close()
|
||||||
|
|
||||||
# Save info
|
# Save info
|
||||||
with open(Path(cfg.output_dir) / "eval_info.json", "w") as f:
|
with open(Path(cfg.output_dir) / "eval_info.json", "w") as f:
|
||||||
json.dump(info, f, indent=2)
|
json.dump(info, f, indent=2)
|
||||||
|
|
||||||
env.close()
|
|
||||||
|
|
||||||
logging.info("End of eval")
|
logging.info("End of eval")
|
||||||
|
|
||||||
|
|
||||||
def main():
|
def eval_policy_multitask(
|
||||||
init_logging()
|
envs: dict[str, dict[str, gym.vector.VectorEnv]],
|
||||||
eval_main()
|
policy,
|
||||||
|
n_episodes: int,
|
||||||
|
max_episodes_rendered: int = 0,
|
||||||
|
videos_dir: Path | None = None,
|
||||||
|
return_episode_data: bool = False,
|
||||||
|
start_seed: int | None = None,
|
||||||
|
max_parallel_tasks: int = 5,
|
||||||
|
verbose: bool = True,
|
||||||
|
) -> dict:
|
||||||
|
global_start = time.time()
|
||||||
|
results = {}
|
||||||
|
|
||||||
|
overall_rewards, overall_max_rewards, overall_successes = [], [], []
|
||||||
|
overall_video_paths = []
|
||||||
|
overall_episode_data = None
|
||||||
|
|
||||||
|
def eval_task(task_group, task_id, env):
|
||||||
|
"""Evaluates a single task in parallel."""
|
||||||
|
print(f"Evaluating: task_group: {task_group}, task_id: {task_id} ...")
|
||||||
|
if videos_dir is not None:
|
||||||
|
task_videos_dir = videos_dir / f"{task_group}_{task_id}"
|
||||||
|
task_videos_dir.mkdir(parents=True, exist_ok=True)
|
||||||
|
task_result = eval_policy(
|
||||||
|
env,
|
||||||
|
policy,
|
||||||
|
n_episodes,
|
||||||
|
max_episodes_rendered,
|
||||||
|
task_videos_dir,
|
||||||
|
return_episode_data,
|
||||||
|
start_seed,
|
||||||
|
)
|
||||||
|
|
||||||
|
per_episode = task_result["per_episode"]
|
||||||
|
return {
|
||||||
|
"task_group": task_group,
|
||||||
|
"task_id": task_id,
|
||||||
|
"sum_rewards": [ep["sum_reward"] for ep in per_episode],
|
||||||
|
"max_rewards": [ep["max_reward"] for ep in per_episode],
|
||||||
|
"successes": [ep["success"] for ep in per_episode],
|
||||||
|
"video_paths": task_result.get("video_paths", []),
|
||||||
|
}
|
||||||
|
|
||||||
|
task_group_results = {}
|
||||||
|
if max_parallel_tasks == 1:
|
||||||
|
# sequential mode (safe for colab / EGL)
|
||||||
|
for task_group, tasks in envs.items():
|
||||||
|
for task_id, env in tasks.items():
|
||||||
|
task_result = eval_task(task_group, task_id, env)
|
||||||
|
if task_group not in task_group_results:
|
||||||
|
task_group_results[task_group] = {
|
||||||
|
"sum_rewards": [],
|
||||||
|
"max_rewards": [],
|
||||||
|
"successes": [],
|
||||||
|
"video_paths": [],
|
||||||
|
}
|
||||||
|
task_group_results[task_group]["sum_rewards"].extend(task_result["sum_rewards"])
|
||||||
|
task_group_results[task_group]["max_rewards"].extend(task_result["max_rewards"])
|
||||||
|
task_group_results[task_group]["successes"].extend(task_result["successes"])
|
||||||
|
task_group_results[task_group]["video_paths"].extend(task_result["video_paths"])
|
||||||
|
else:
|
||||||
|
with concurrent.futures.ThreadPoolExecutor(max_workers=max_parallel_tasks) as executor:
|
||||||
|
future_to_task = {
|
||||||
|
executor.submit(eval_task, task_group, task_id, env): (task_group, task_id)
|
||||||
|
for task_group, tasks in envs.items()
|
||||||
|
for task_id, env in tasks.items()
|
||||||
|
}
|
||||||
|
|
||||||
|
task_group_results = {}
|
||||||
|
|
||||||
|
for future in concurrent.futures.as_completed(future_to_task):
|
||||||
|
task_result = future.result()
|
||||||
|
task_group = task_result["task_group"]
|
||||||
|
|
||||||
|
if task_group not in task_group_results:
|
||||||
|
task_group_results[task_group] = {
|
||||||
|
"sum_rewards": [],
|
||||||
|
"max_rewards": [],
|
||||||
|
"successes": [],
|
||||||
|
"video_paths": [],
|
||||||
|
}
|
||||||
|
|
||||||
|
task_group_results[task_group]["sum_rewards"].extend(task_result["sum_rewards"])
|
||||||
|
task_group_results[task_group]["max_rewards"].extend(task_result["max_rewards"])
|
||||||
|
task_group_results[task_group]["successes"].extend(task_result["successes"])
|
||||||
|
task_group_results[task_group]["video_paths"].extend(task_result["video_paths"])
|
||||||
|
|
||||||
|
# Process results per task group
|
||||||
|
for task_group, data in task_group_results.items():
|
||||||
|
suite_rewards = data["sum_rewards"]
|
||||||
|
suite_max_rewards = data["max_rewards"]
|
||||||
|
suite_successes = data["successes"]
|
||||||
|
suite_video_paths = data["video_paths"]
|
||||||
|
|
||||||
|
suite_eval_s = time.time() - global_start
|
||||||
|
suite_eval_ep_s = suite_eval_s / max(1, len(suite_rewards))
|
||||||
|
|
||||||
|
results[task_group] = {
|
||||||
|
"aggregated": {
|
||||||
|
"avg_sum_reward": float(np.nanmean(suite_rewards)),
|
||||||
|
"avg_max_reward": float(np.nanmean(suite_max_rewards)),
|
||||||
|
"pc_success": float(np.nanmean(suite_successes) * 100),
|
||||||
|
"eval_s": suite_eval_s,
|
||||||
|
"eval_ep_s": suite_eval_ep_s,
|
||||||
|
},
|
||||||
|
"video_paths": suite_video_paths,
|
||||||
|
"episodes": None, # Modify if episode data is needed
|
||||||
|
}
|
||||||
|
|
||||||
|
overall_rewards.extend(suite_rewards)
|
||||||
|
overall_max_rewards.extend(suite_max_rewards)
|
||||||
|
overall_successes.extend(suite_successes)
|
||||||
|
overall_video_paths.extend(suite_video_paths)
|
||||||
|
|
||||||
|
# Global metrics
|
||||||
|
global_eval_s = time.time() - global_start
|
||||||
|
global_eval_ep_s = global_eval_s / max(1, len(overall_rewards))
|
||||||
|
|
||||||
|
results["overall"] = {
|
||||||
|
"aggregated": {
|
||||||
|
"avg_sum_reward": float(np.nanmean(overall_rewards)),
|
||||||
|
"avg_max_reward": float(np.nanmean(overall_max_rewards)),
|
||||||
|
"pc_success": float(np.nanmean(overall_successes) * 100),
|
||||||
|
"eval_s": global_eval_s,
|
||||||
|
"eval_ep_s": global_eval_ep_s,
|
||||||
|
},
|
||||||
|
"video_paths": overall_video_paths,
|
||||||
|
"episodes": overall_episode_data,
|
||||||
|
}
|
||||||
|
|
||||||
|
return results
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
if __name__ == "__main__":
|
||||||
main()
|
init_logging()
|
||||||
|
eval_main()
|
||||||
|
|||||||
@@ -34,7 +34,7 @@ from lerobot.optim.factory import make_optimizer_and_scheduler
|
|||||||
from lerobot.policies.factory import make_policy
|
from lerobot.policies.factory import make_policy
|
||||||
from lerobot.policies.pretrained import PreTrainedPolicy
|
from lerobot.policies.pretrained import PreTrainedPolicy
|
||||||
from lerobot.policies.utils import get_device_from_parameters
|
from lerobot.policies.utils import get_device_from_parameters
|
||||||
from lerobot.scripts.eval import eval_policy
|
from lerobot.scripts.eval import eval_policy, eval_policy_multitask
|
||||||
from lerobot.utils.logging_utils import AverageMeter, MetricsTracker
|
from lerobot.utils.logging_utils import AverageMeter, MetricsTracker
|
||||||
from lerobot.utils.random_utils import set_seed
|
from lerobot.utils.random_utils import set_seed
|
||||||
from lerobot.utils.train_utils import (
|
from lerobot.utils.train_utils import (
|
||||||
@@ -186,7 +186,6 @@ def train(cfg: TrainPipelineConfig):
|
|||||||
dl_iter = cycle(dataloader)
|
dl_iter = cycle(dataloader)
|
||||||
|
|
||||||
policy.train()
|
policy.train()
|
||||||
|
|
||||||
train_metrics = {
|
train_metrics = {
|
||||||
"loss": AverageMeter("loss", ":.3f"),
|
"loss": AverageMeter("loss", ":.3f"),
|
||||||
"grad_norm": AverageMeter("grdn", ":.3f"),
|
"grad_norm": AverageMeter("grdn", ":.3f"),
|
||||||
@@ -252,6 +251,24 @@ def train(cfg: TrainPipelineConfig):
|
|||||||
torch.no_grad(),
|
torch.no_grad(),
|
||||||
torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext(),
|
torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext(),
|
||||||
):
|
):
|
||||||
|
if cfg.env.multitask_eval:
|
||||||
|
eval_info = eval_policy_multitask(
|
||||||
|
eval_env,
|
||||||
|
policy,
|
||||||
|
cfg.eval.n_episodes,
|
||||||
|
videos_dir=cfg.output_dir / "eval" / f"videos_step_{step_id}",
|
||||||
|
max_episodes_rendered=4,
|
||||||
|
start_seed=cfg.seed,
|
||||||
|
max_parallel_tasks=cfg.env.max_parallel_tasks,
|
||||||
|
)
|
||||||
|
aggregated = eval_info["overall"]["aggregated"]
|
||||||
|
# Print per-suite stats, log?
|
||||||
|
for task_group, task_group_info in eval_info.items():
|
||||||
|
if task_group == "overall":
|
||||||
|
continue # Skip the overall stats since we already printed it
|
||||||
|
print(f"\nAggregated Metrics for {task_group}:")
|
||||||
|
print(task_group_info["aggregated"])
|
||||||
|
else:
|
||||||
eval_info = eval_policy(
|
eval_info = eval_policy(
|
||||||
eval_env,
|
eval_env,
|
||||||
policy,
|
policy,
|
||||||
@@ -260,6 +277,7 @@ def train(cfg: TrainPipelineConfig):
|
|||||||
max_episodes_rendered=4,
|
max_episodes_rendered=4,
|
||||||
start_seed=cfg.seed,
|
start_seed=cfg.seed,
|
||||||
)
|
)
|
||||||
|
aggregated = eval_info["aggregated"]
|
||||||
|
|
||||||
eval_metrics = {
|
eval_metrics = {
|
||||||
"avg_sum_reward": AverageMeter("∑rwrd", ":.3f"),
|
"avg_sum_reward": AverageMeter("∑rwrd", ":.3f"),
|
||||||
@@ -269,9 +287,9 @@ def train(cfg: TrainPipelineConfig):
|
|||||||
eval_tracker = MetricsTracker(
|
eval_tracker = MetricsTracker(
|
||||||
cfg.batch_size, dataset.num_frames, dataset.num_episodes, eval_metrics, initial_step=step
|
cfg.batch_size, dataset.num_frames, dataset.num_episodes, eval_metrics, initial_step=step
|
||||||
)
|
)
|
||||||
eval_tracker.eval_s = eval_info["aggregated"].pop("eval_s")
|
eval_tracker.eval_s = aggregated.pop("eval_s")
|
||||||
eval_tracker.avg_sum_reward = eval_info["aggregated"].pop("avg_sum_reward")
|
eval_tracker.avg_sum_reward = aggregated.pop("avg_sum_reward")
|
||||||
eval_tracker.pc_success = eval_info["aggregated"].pop("pc_success")
|
eval_tracker.pc_success = aggregated.pop("pc_success")
|
||||||
logging.info(eval_tracker)
|
logging.info(eval_tracker)
|
||||||
if wandb_logger:
|
if wandb_logger:
|
||||||
wandb_log_dict = {**eval_tracker.to_dict(), **eval_info}
|
wandb_log_dict = {**eval_tracker.to_dict(), **eval_info}
|
||||||
@@ -279,6 +297,11 @@ def train(cfg: TrainPipelineConfig):
|
|||||||
wandb_logger.log_video(eval_info["video_paths"][0], step, mode="eval")
|
wandb_logger.log_video(eval_info["video_paths"][0], step, mode="eval")
|
||||||
|
|
||||||
if eval_env:
|
if eval_env:
|
||||||
|
if cfg.env.multitask_eval:
|
||||||
|
for _task_group, envs_dict in eval_env.items():
|
||||||
|
for _idx, env in envs_dict.items():
|
||||||
|
env.close()
|
||||||
|
else:
|
||||||
eval_env.close()
|
eval_env.close()
|
||||||
logging.info("End of training")
|
logging.info("End of training")
|
||||||
|
|
||||||
|
|||||||
Reference in New Issue
Block a user