mirror of
https://github.com/huggingface/lerobot.git
synced 2026-05-16 09:09:48 +00:00
226 lines
9.1 KiB
Plaintext
226 lines
9.1 KiB
Plaintext
# LIBERO
|
||
|
||
**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers. The benchmark was first introduced in the [LIBERO paper](https://arxiv.org/abs/2306.03310) and the [original repository](https://github.com/Lifelong-Robot-Learning/LIBERO).
|
||
|
||
To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
|
||
|
||
LIBERO includes **five task suites**:
|
||
|
||
- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
|
||
- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
|
||
- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
|
||
- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
|
||
- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
|
||
|
||
Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
|
||
|
||
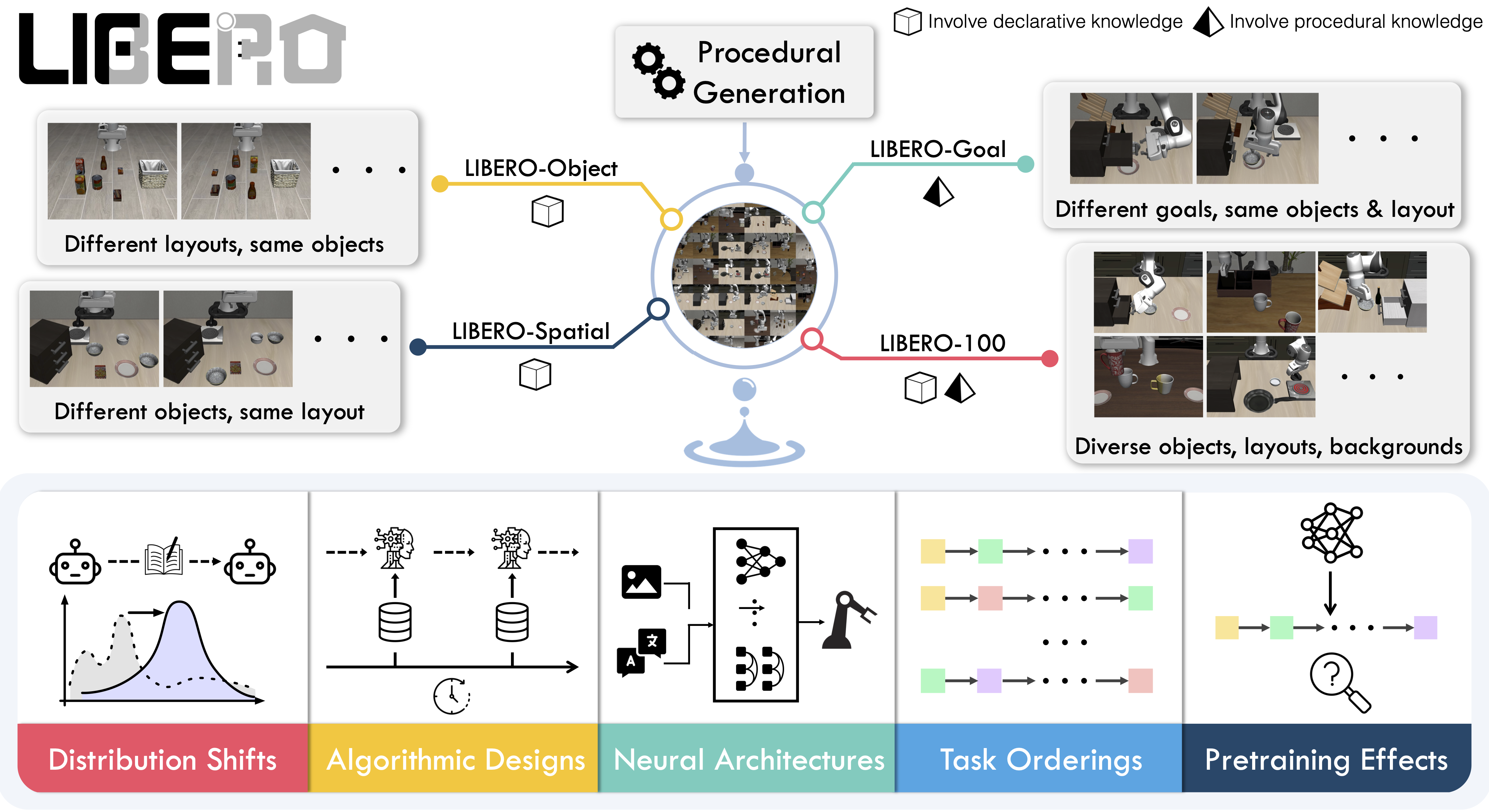
|
||
*Figure 1: An overview of the LIBERO benchmark.*
|
||
|
||
## Evaluating with LIBERO
|
||
|
||
At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it primarily to **benchmark [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model, comparing it against state-of-the-art VLA models such as Pi0, OpenVLA, Octo, and Diffusion Policy.
|
||
|
||
LIBERO is now part of our **multi-eval supported simulation**, allowing you to benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a single flag.
|
||
|
||
To install LIBERO, first follow the [LeRobot Installation Guide](https://huggingface.co/docs/lerobot/installation).
|
||
Once LeRobot is installed, there are two options:
|
||
|
||
1. **Install via pip** (recommended):
|
||
```bash
|
||
pip install "lerobot[libero,smolvla]"
|
||
```
|
||
|
||
2. **Install from source**:
|
||
```bash
|
||
git clone https://github.com/huggingface/lerobot.git
|
||
cd lerobot
|
||
pip install -e ".[libero,smolvla]"
|
||
```
|
||
|
||
### Single-suite evaluation
|
||
|
||
Evaluate a policy on one LIBERO suite:
|
||
|
||
```bash
|
||
python src/lerobot/scripts/eval.py \
|
||
--policy.path="your-policy-id" \
|
||
--env.type=libero \
|
||
--env.task=libero_object \
|
||
--env.multitask_eval=False \
|
||
--eval.batch_size=2 \
|
||
--eval.n_episodes=3
|
||
```
|
||
|
||
- `--env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
|
||
- `--eval.batch_size` controls how many environments run in parallel.
|
||
- `--eval.n_episodes` sets how many episodes to run in total.
|
||
|
||
---
|
||
|
||
### Multi-suite evaluation
|
||
|
||
Benchmark a policy across multiple suites at once:
|
||
|
||
```bash
|
||
python src/lerobot/scripts/eval.py \
|
||
--policy.path="your-policy-id" \
|
||
--env.type=libero \
|
||
--env.task=libero_object \
|
||
--env.multitask_eval=True \
|
||
--eval.batch_size=1 \
|
||
--eval.n_episodes=2
|
||
```
|
||
|
||
- Pass a comma-separated list to `--env.task` for multi-suite evaluation.
|
||
- Set `-env.multitask_eval=True` to enable evaluation across all tasks in those suites.
|
||
|
||
### Policy inputs and outputs
|
||
|
||
When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
|
||
|
||
- **Observations**
|
||
- `observation.state` – proprioceptive features (agent state).
|
||
- `observation.images.image` – main camera view (`agentview_image`).
|
||
- `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
|
||
|
||
⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any visual features. Make sure your dataset metadata keys match this convention when evaluating.
|
||
## Input Features and Metadata Alignment
|
||
|
||
To train or evaluate a policy, you use `make_policy`, which builds a feature-naming dictionary for the observations the policy expects.
|
||
This mapping can come from:
|
||
- Dataset metadata
|
||
- The evaluation environment
|
||
- The policy path (if a pretrained repo ID is provided)
|
||
|
||
### Common Issues
|
||
|
||
A common problem is when the keys in the dataset, environment, and policy config do not match. For example:
|
||
- `wrist_image` vs `observation.images.image2`
|
||
- `observation.image2` (as in SmolVLA) vs the `.images.*` prefix convention
|
||
|
||
Such mismatches will cause `KeyError`s. This may be due to assumptions in `make_policy` or missing error handling.
|
||
|
||
---
|
||
|
||
### How to Check Expected Features
|
||
|
||
- Open your policy config (`config.json`), e.g. [example here](https://huggingface.co/jadechoghari/smolvla-libero/blob/main/config.json).
|
||
- Or add a breakpoint in `train.py` and inspect:
|
||
```python
|
||
print(policy.config.input_features)
|
||
To ensure you can just check what your policy expects as `input_features`:
|
||
|
||
- Open your policy config (`config.json`), e.g. [example here](https://huggingface.co/jadechoghari/smolvla-libero/blob/main/config.json).
|
||
- Or add a breakpoint in `train.py` and inspect:
|
||
```python
|
||
print(policy.config.input_features)
|
||
Fixing KeyErrors (Preprocessing Example)
|
||
|
||
## Fixing KeyErrors (Preprocessing Example)
|
||
|
||
If your dataset columns do not follow the expected naming, you can rename them in-place before training:
|
||
|
||
```python
|
||
import pyarrow.parquet as pq
|
||
import shutil
|
||
|
||
def rename_columns(parquet_path, rename_map):
|
||
table = pq.read_table(parquet_path)
|
||
schema = table.schema
|
||
new_names = [rename_map.get(name, name) for name in schema.names]
|
||
renamed_table = table.rename_columns(new_names)
|
||
backup_path = parquet_path + ".bak"
|
||
shutil.copy(parquet_path, backup_path)
|
||
pq.write_table(renamed_table, parquet_path)
|
||
print(f"patched {parquet_path}, backup at {backup_path}")
|
||
|
||
# example mapping: align dataset keys to LeRobot convention
|
||
rename_map = {
|
||
"image": "observation.images.image",
|
||
"wrist_image": "observation.images.image2",
|
||
}
|
||
|
||
rename_columns("episode_000001.parquet", rename_map)
|
||
|
||
|
||
|
||
- **Actions**
|
||
- Continuous control values in a `Box(-1, 1, shape=(7,))` space.
|
||
|
||
We also provide a notebook for quick testing:
|
||
Training with LIBERO
|
||
|
||
## Training with LIBERO
|
||
|
||
When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
|
||
|
||
The environment expects:
|
||
|
||
- `observation.state` → 8-dim agent state
|
||
- `observation.images.image` → main camera (`agentview_image`)
|
||
- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
|
||
|
||
⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code. We plan to provide a script to easily preprocess such data.
|
||
To avoid potential mismatches and `KeyError`s, we provide a **preprocessed LIBERO dataset** that is fully compatible with the current LeRobot codebase and requires no additional manipulations.
|
||
|
||
- 🔗 [Preprocessed LIBERO dataset (Hugging Face LeRobot org)](https://huggingface.co/datasets/HuggingFaceVLA/libero)
|
||
- 🔗 [Original LIBERO dataset (physical-intelligence)](https://huggingface.co/datasets/physical-intelligence/libero)
|
||
|
||
The preprocessed dataset follows LeRobot naming conventions (e.g., `.images.*` prefix for visual features) and aligns with policy configs out-of-the-box.
|
||
The original dataset is acknowledged here as the primary source.
|
||
---
|
||
|
||
### Example training command
|
||
|
||
```bash
|
||
python src/lerobot/scripts/train.py \
|
||
--policy.type=smolvla \
|
||
--policy.repo_id=${HF_USER}/libero-test \
|
||
--dataset.repo_id=jadechoghari/smol-libero3 \
|
||
--env.type=libero \
|
||
--env.task=libero_10 \
|
||
--output_dir=./outputs/ \
|
||
--steps=100000 \
|
||
--batch_size=4 \
|
||
--env.multitask_eval=True \
|
||
--eval.batch_size=1 \
|
||
--eval.n_episodes=1 \
|
||
--eval_freq=1000 \
|
||
```
|
||
|
||
---
|
||
|
||
### Note on rendering
|
||
|
||
LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
|
||
|
||
- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
|
||
|
||
---
|
||
|
||
## Colab Note on Parallel Evaluation
|
||
|
||
When running evaluation on Colab, you may encounter warnings such as:
|
||
|
||
```
|
||
UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
|
||
```
|
||
|
||
This happens because Colab’s rendering contexts are **not thread-safe**, and `ThreadPoolExecutor(max_workers=num_workers)` can trigger segfaults or leaked semaphore warnings.
|
||
|
||
**Colab Note:**
|
||
Parallel evaluation is not supported in Colab. To avoid these issues, run sequentially or disable multitask evaluation:
|
||
|
||
Run sequentially:
|
||
```bash
|
||
--env.max_parallel_tasks=1
|
||
```
|
||
|
||
Or disable multitask evaluation:
|
||
```bash
|
||
--env.multitask_eval=False
|
||
```
|
||
|
||
If you want to take advantage of **parallel evaluation**, we recommend **not using Colab**. Instead, run locally or on a proper compute environment where multi-threaded rendering is easily supported.
|