mirror of
https://github.com/huggingface/lerobot.git
synced 2026-05-16 09:09:48 +00:00
119 lines
4.8 KiB
Plaintext
119 lines
4.8 KiB
Plaintext
# LIBERO
|
||
|
||
**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers.
|
||
|
||
To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
|
||
|
||
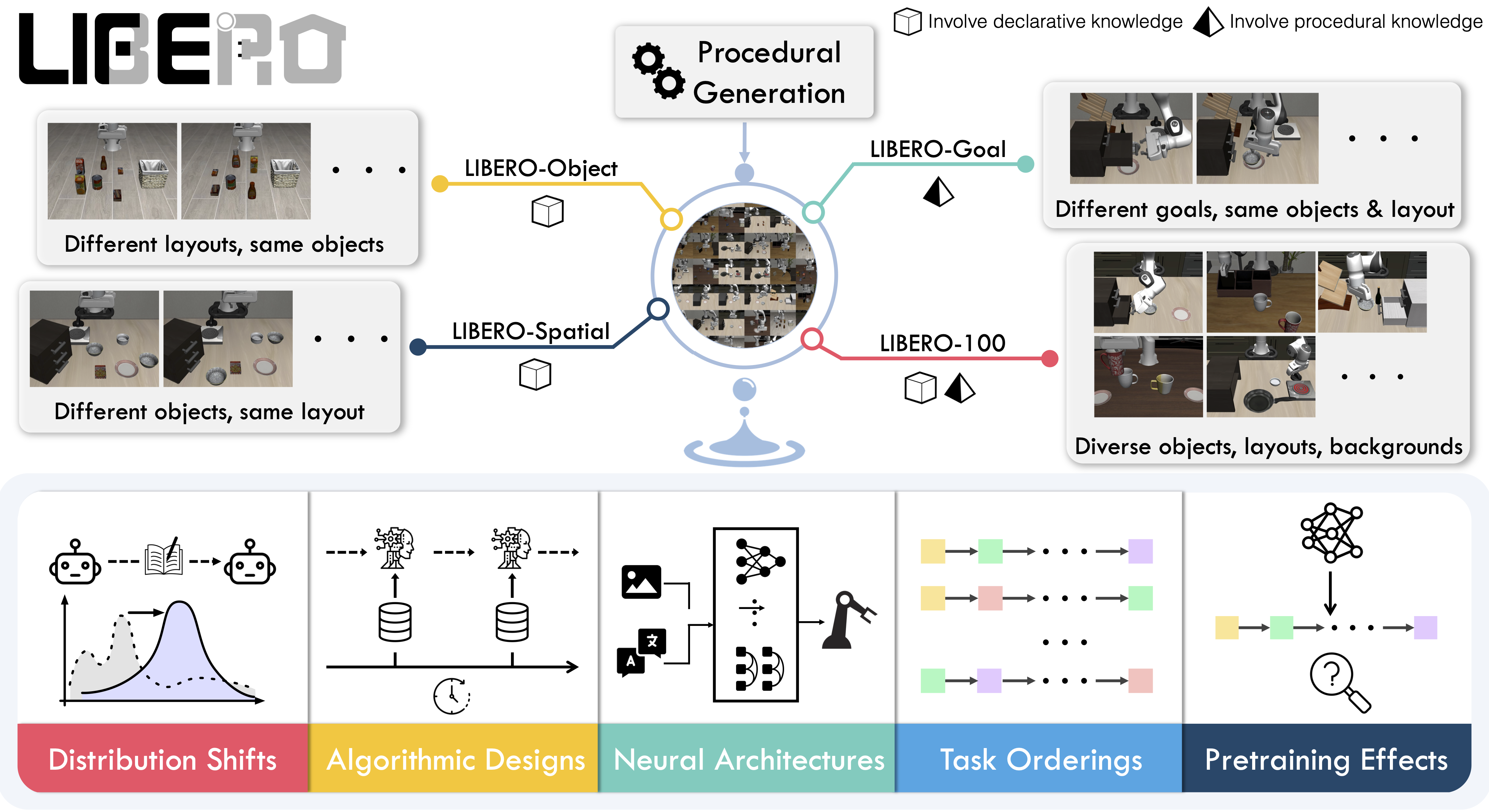
LIBERO includes **five task suites**:
|
||
|
||
- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
|
||
- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
|
||
- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
|
||
- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
|
||
- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
|
||
|
||
Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
|
||
|
||
|
||
|
||
## Evaluating with LIBERO
|
||
|
||
At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it mainly to **evaluate [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model.
|
||
|
||
LIBERO is now part of our **multi-eval supported simulation**, meaning you can benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a flag.
|
||
|
||
To Install LIBERO, after following LeRobot official instructions, just do:
|
||
`pip install -e ".[libero]"`
|
||
|
||
### Single-suite evaluation
|
||
|
||
Evaluate a policy on one LIBERO suite:
|
||
|
||
```bash
|
||
python src/lerobot/scripts/eval.py \
|
||
--policy.path="your-policy-id" \
|
||
--env.type=libero \
|
||
--env.task=libero_object \
|
||
--env.multitask_eval=False \
|
||
--eval.batch_size=2 \
|
||
--eval.n_episodes=3
|
||
```
|
||
|
||
- `-env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
|
||
- `-eval.batch_size` controls how many environments run in parallel.
|
||
- `-eval.n_episodes` sets how many episodes to run in total.
|
||
|
||
---
|
||
|
||
### Multi-suite evaluation
|
||
|
||
Benchmark a policy across multiple suites at once:
|
||
|
||
```bash
|
||
python src/lerobot/scripts/eval.py \
|
||
--policy.path="your-policy-id" \
|
||
--env.type=libero \
|
||
--env.task=libero_object,libero_spatial \
|
||
--env.multitask_eval=True \
|
||
--eval.batch_size=1 \
|
||
--eval.n_episodes=2
|
||
```
|
||
|
||
- Pass a comma-separated list to `-env.task` for multi-suite evaluation.
|
||
- Set `-env.multitask_eval=True` to enable evaluation across all tasks in those suites.
|
||
|
||
### Policy inputs and outputs
|
||
|
||
When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
|
||
|
||
- **Observations**
|
||
- `observation.state` – proprioceptive features (agent state).
|
||
- `observation.images.image` – main camera view (`agentview_image`).
|
||
- `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
|
||
|
||
⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any visual features. Make sure your dataset metadata keys match this convention when evaluating.
|
||
|
||
- **Actions**
|
||
- Continuous control values in a `Box(-1, 1, shape=(7,))` space.
|
||
|
||
We also provide a notebook for quick testing:
|
||
Training with LIBERO
|
||
|
||
## Training with LIBERO
|
||
|
||
When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
|
||
|
||
The environment expects:
|
||
|
||
- `observation.state` → 8-dim agent state
|
||
- `observation.images.image` → main camera (`agentview_image`)
|
||
- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
|
||
|
||
⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code. We plan to provide a script to easily preprocess such data.
|
||
|
||
---
|
||
|
||
### Example training command
|
||
|
||
```bash
|
||
python src/lerobot/scripts/train.py \
|
||
--policy.type=smolvla \
|
||
--dataset.repo_id=jadechoghari/smol-libero3 \
|
||
--env.type=libero \
|
||
--env.task=libero_10,libero_spatial \
|
||
--output_dir=./outputs/ \
|
||
--steps=100000 \
|
||
--batch_size=4 \
|
||
--env.multitask_eval=True \
|
||
--eval.batch_size=1 \
|
||
--eval.n_episodes=1
|
||
```
|
||
|
||
---
|
||
|
||
### Note on rendering
|
||
|
||
LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
|
||
|
||
- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
|
||
- `export MUJOCO_GL=glfw` → for local runs with a display |