mirror of
https://github.com/huggingface/lerobot.git
synced 2026-07-08 18:41:54 +00:00
docs(benchmarks): add benchmark integration guide and standardize benchmark docs (#3270)
* docs(benchmarks): add benchmark integration guide and standardize benchmark docs Add a comprehensive guide for adding new benchmarks to LeRobot, and refactor the existing LIBERO and Meta-World docs to follow the new standardized template. Made-with: Cursor * docs(benchmarks): clean up adding-benchmarks guide for clarity Rewrite for simpler language, better structure, and easier navigation. Move quick-reference table to the top, fold eval explanation into architecture section, condense the doc template to a bulleted outline. Made-with: Cursor * fix link * fix task count * Update docs/source/adding_benchmarks.mdx Co-authored-by: Khalil Meftah <khalil.meftah@huggingface.co> Signed-off-by: Pepijn <138571049+pkooij@users.noreply.github.com> * Update docs/source/metaworld.mdx Co-authored-by: Khalil Meftah <khalil.meftah@huggingface.co> Signed-off-by: Pepijn <138571049+pkooij@users.noreply.github.com> * Update docs/source/adding_benchmarks.mdx Co-authored-by: Khalil Meftah <khalil.meftah@huggingface.co> Signed-off-by: Pepijn <138571049+pkooij@users.noreply.github.com> * Update docs/source/adding_benchmarks.mdx Co-authored-by: Khalil Meftah <khalil.meftah@huggingface.co> Signed-off-by: Pepijn <138571049+pkooij@users.noreply.github.com> * Update docs/source/adding_benchmarks.mdx Co-authored-by: Khalil Meftah <khalil.meftah@huggingface.co> Signed-off-by: Pepijn <138571049+pkooij@users.noreply.github.com> * docs(benchmarks): add verification checklist to adding-benchmarks guide Made-with: Cursor --------- Signed-off-by: Pepijn <138571049+pkooij@users.noreply.github.com> Co-authored-by: Khalil Meftah <khalil.meftah@huggingface.co>
This commit is contained in:
@@ -73,6 +73,8 @@
|
||||
title: Control & Train Robots in Sim (LeIsaac)
|
||||
title: "Simulation"
|
||||
- sections:
|
||||
- local: adding_benchmarks
|
||||
title: Adding a New Benchmark
|
||||
- local: libero
|
||||
title: LIBERO
|
||||
- local: metaworld
|
||||
|
||||
@@ -0,0 +1,329 @@
|
||||
# Adding a New Benchmark
|
||||
|
||||
This guide walks you through adding a new simulation benchmark to LeRobot. Follow the steps in order and use the existing benchmarks as templates.
|
||||
|
||||
A benchmark in LeRobot is a set of [Gymnasium](https://gymnasium.farama.org/) environments that wrap a third-party simulator (like LIBERO or Meta-World) behind a standard `gym.Env` interface. The `lerobot-eval` CLI then runs evaluation uniformly across all benchmarks.
|
||||
|
||||
## Existing benchmarks at a glance
|
||||
|
||||
Before diving in, here is what is already integrated:
|
||||
|
||||
| Benchmark | Env file | Config class | Tasks | Action dim | Processor |
|
||||
| -------------- | ------------------- | ------------------ | ------------------- | ------------ | ---------------------------- |
|
||||
| LIBERO | `envs/libero.py` | `LiberoEnv` | 130 across 5 suites | 7 | `LiberoProcessorStep` |
|
||||
| Meta-World | `envs/metaworld.py` | `MetaworldEnv` | 50 (MT50) | 4 | None |
|
||||
| IsaacLab Arena | Hub-hosted | `IsaaclabArenaEnv` | Configurable | Configurable | `IsaaclabArenaProcessorStep` |
|
||||
|
||||
Use `src/lerobot/envs/libero.py` and `src/lerobot/envs/metaworld.py` as reference implementations.
|
||||
|
||||
## How it all fits together
|
||||
|
||||
### Data flow
|
||||
|
||||
During evaluation, data moves through four stages:
|
||||
|
||||
```
|
||||
1. gym.Env ──→ raw observations (numpy dicts)
|
||||
|
||||
2. Preprocessing ──→ standard LeRobot keys + task description
|
||||
(preprocess_observation, add_envs_task in envs/utils.py)
|
||||
|
||||
3. Processors ──→ env-specific then policy-specific transforms
|
||||
(env_preprocessor, policy_preprocessor)
|
||||
|
||||
4. Policy ──→ select_action() ──→ action tensor
|
||||
then reverse: policy_postprocessor → env_postprocessor → numpy action → env.step()
|
||||
```
|
||||
|
||||
Most benchmarks only need to care about stage 1 (producing observations in the right format) and optionally stage 3 (if env-specific transforms are needed).
|
||||
|
||||
### Environment structure
|
||||
|
||||
`make_env()` returns a nested dict of vectorized environments:
|
||||
|
||||
```python
|
||||
dict[str, dict[int, gym.vector.VectorEnv]]
|
||||
# ^suite ^task_id
|
||||
```
|
||||
|
||||
A single-task env (e.g. PushT) looks like `{"pusht": {0: vec_env}}`.
|
||||
A multi-task benchmark (e.g. LIBERO) looks like `{"libero_spatial": {0: vec0, 1: vec1, ...}, ...}`.
|
||||
|
||||
### How evaluation runs
|
||||
|
||||
All benchmarks are evaluated the same way by `lerobot-eval`:
|
||||
|
||||
1. `make_env()` builds the nested `{suite: {task_id: VectorEnv}}` dict.
|
||||
2. `eval_policy_all()` iterates over every suite and task.
|
||||
3. For each task, it runs `n_episodes` rollouts via `rollout()`.
|
||||
4. Results are aggregated hierarchically: episode, task, suite, overall.
|
||||
5. Metrics include `pc_success` (success rate), `avg_sum_reward`, and `avg_max_reward`.
|
||||
|
||||
The critical piece: your env must return `info["is_success"]` on every `step()` call. This is how the eval loop knows whether a task was completed.
|
||||
|
||||
## What your environment must provide
|
||||
|
||||
LeRobot does not enforce a strict observation schema. Instead it relies on a set of conventions that all benchmarks follow.
|
||||
|
||||
### Env attributes
|
||||
|
||||
Your `gym.Env` must set these attributes:
|
||||
|
||||
| Attribute | Type | Why |
|
||||
| -------------------- | ----- | ---------------------------------------------------- |
|
||||
| `_max_episode_steps` | `int` | `rollout()` uses this to cap episode length |
|
||||
| `task_description` | `str` | Passed to VLA policies as a language instruction |
|
||||
| `task` | `str` | Fallback identifier if `task_description` is not set |
|
||||
|
||||
### Success reporting
|
||||
|
||||
Your `step()` and `reset()` must include `"is_success"` in the `info` dict:
|
||||
|
||||
```python
|
||||
info = {"is_success": True} # or False
|
||||
return observation, reward, terminated, truncated, info
|
||||
```
|
||||
|
||||
### Observations
|
||||
|
||||
The simplest approach is to map your simulator's outputs to the standard keys that `preprocess_observation()` already understands. Do this inside your `gym.Env` (e.g. in a `_format_raw_obs()` helper):
|
||||
|
||||
| Your env should output | LeRobot maps it to | What it is |
|
||||
| ------------------------- | -------------------------- | ------------------------------------- |
|
||||
| `"pixels"` (single array) | `observation.image` | Single camera image, HWC uint8 |
|
||||
| `"pixels"` (dict) | `observation.images.<cam>` | Multiple cameras, each HWC uint8 |
|
||||
| `"agent_pos"` | `observation.state` | Proprioceptive state vector |
|
||||
| `"environment_state"` | `observation.env_state` | Full environment state (e.g. PushT) |
|
||||
| `"robot_state"` | `observation.robot_state` | Nested robot state dict (e.g. LIBERO) |
|
||||
|
||||
If your simulator uses different key names, you have two options:
|
||||
|
||||
1. **Recommended:** Rename them to the standard keys inside your `gym.Env` wrapper.
|
||||
2. **Alternative:** Write an env processor to transform observations after `preprocess_observation()` runs (see step 4 below).
|
||||
|
||||
### Actions
|
||||
|
||||
Actions are continuous numpy arrays in a `gym.spaces.Box`. The dimensionality depends on your benchmark (7 for LIBERO, 4 for Meta-World, etc.). Policies adapt to different action dimensions through their `input_features` / `output_features` config.
|
||||
|
||||
### Feature declaration
|
||||
|
||||
Each `EnvConfig` subclass declares two dicts that tell the policy what to expect:
|
||||
|
||||
- `features` — maps feature names to `PolicyFeature(type, shape)` (e.g. action dim, image shape).
|
||||
- `features_map` — maps raw observation keys to LeRobot convention keys (e.g. `"agent_pos"` to `"observation.state"`).
|
||||
|
||||
## Step by step
|
||||
|
||||
<Tip>
|
||||
At minimum, you need three files: a **gym.Env wrapper**, an **EnvConfig
|
||||
subclass**, and a **factory dispatch branch**. Everything else is optional or
|
||||
documentation.
|
||||
</Tip>
|
||||
|
||||
### Checklist
|
||||
|
||||
| File | Required | Why |
|
||||
| ---------------------------------------- | -------- | ----------------------------------------- |
|
||||
| `src/lerobot/envs/<benchmark>.py` | Yes | Wraps the simulator as a standard gym.Env |
|
||||
| `src/lerobot/envs/configs.py` | Yes | Registers your benchmark for the CLI |
|
||||
| `src/lerobot/envs/factory.py` | Yes | Tells `make_env()` how to build your envs |
|
||||
| `src/lerobot/processor/env_processor.py` | Optional | Custom observation/action transforms |
|
||||
| `src/lerobot/envs/utils.py` | Optional | Only if you need new raw observation keys |
|
||||
| `pyproject.toml` | Yes | Declares benchmark-specific dependencies |
|
||||
| `docs/source/<benchmark>.mdx` | Yes | User-facing documentation page |
|
||||
| `docs/source/_toctree.yml` | Yes | Adds your page to the docs sidebar |
|
||||
|
||||
### 1. The gym.Env wrapper (`src/lerobot/envs/<benchmark>.py`)
|
||||
|
||||
Create a `gym.Env` subclass that wraps the third-party simulator:
|
||||
|
||||
```python
|
||||
class MyBenchmarkEnv(gym.Env):
|
||||
metadata = {"render_modes": ["rgb_array"], "render_fps": <fps>}
|
||||
|
||||
def __init__(self, task_suite, task_id, ...):
|
||||
super().__init__()
|
||||
self.task = <task_name_string>
|
||||
self.task_description = <natural_language_instruction>
|
||||
self._max_episode_steps = <max_steps>
|
||||
self.observation_space = spaces.Dict({...})
|
||||
self.action_space = spaces.Box(low=..., high=..., shape=(...,), dtype=np.float32)
|
||||
|
||||
def reset(self, seed=None, **kwargs):
|
||||
... # return (observation, info) — info must contain {"is_success": False}
|
||||
|
||||
def step(self, action: np.ndarray):
|
||||
... # return (obs, reward, terminated, truncated, info) — info must contain {"is_success": <bool>}
|
||||
|
||||
def render(self):
|
||||
... # return RGB image as numpy array
|
||||
|
||||
def close(self):
|
||||
...
|
||||
```
|
||||
|
||||
Also provide a factory function that returns the nested dict structure:
|
||||
|
||||
```python
|
||||
def create_mybenchmark_envs(
|
||||
task: str,
|
||||
n_envs: int,
|
||||
gym_kwargs: dict | None = None,
|
||||
env_cls: type | None = None,
|
||||
) -> dict[str, dict[int, Any]]:
|
||||
"""Create {suite_name: {task_id: VectorEnv}} for MyBenchmark."""
|
||||
...
|
||||
```
|
||||
|
||||
See `create_libero_envs()` (multi-suite, multi-task) and `create_metaworld_envs()` (difficulty-grouped tasks) for reference.
|
||||
|
||||
### 2. The config (`src/lerobot/envs/configs.py`)
|
||||
|
||||
Register a config dataclass so users can select your benchmark with `--env.type=<name>`:
|
||||
|
||||
```python
|
||||
@EnvConfig.register_subclass("<benchmark_name>")
|
||||
@dataclass
|
||||
class MyBenchmarkEnvConfig(EnvConfig):
|
||||
task: str = "<default_task>"
|
||||
fps: int = <fps>
|
||||
obs_type: str = "pixels_agent_pos"
|
||||
|
||||
features: dict[str, PolicyFeature] = field(default_factory=lambda: {
|
||||
ACTION: PolicyFeature(type=FeatureType.ACTION, shape=(<action_dim>,)),
|
||||
})
|
||||
features_map: dict[str, str] = field(default_factory=lambda: {
|
||||
ACTION: ACTION,
|
||||
"agent_pos": OBS_STATE,
|
||||
"pixels": OBS_IMAGE,
|
||||
})
|
||||
|
||||
def __post_init__(self):
|
||||
... # populate features based on obs_type
|
||||
|
||||
@property
|
||||
def gym_kwargs(self) -> dict:
|
||||
return {"obs_type": self.obs_type, "render_mode": self.render_mode}
|
||||
```
|
||||
|
||||
Key points:
|
||||
|
||||
- The `register_subclass` name is what users pass on the CLI (`--env.type=<name>`).
|
||||
- `features` tells the policy what the environment produces.
|
||||
- `features_map` maps raw observation keys to LeRobot convention keys.
|
||||
|
||||
### 3. The factory dispatch (`src/lerobot/envs/factory.py`)
|
||||
|
||||
Add a branch in `make_env()` to call your factory function:
|
||||
|
||||
```python
|
||||
elif "<benchmark_name>" in cfg.type:
|
||||
from lerobot.envs.<benchmark> import create_<benchmark>_envs
|
||||
|
||||
if cfg.task is None:
|
||||
raise ValueError("<BenchmarkName> requires a task to be specified")
|
||||
|
||||
return create_<benchmark>_envs(
|
||||
task=cfg.task,
|
||||
n_envs=n_envs,
|
||||
gym_kwargs=cfg.gym_kwargs,
|
||||
env_cls=env_cls,
|
||||
)
|
||||
```
|
||||
|
||||
If your benchmark needs an env processor, add it in `make_env_pre_post_processors()`:
|
||||
|
||||
```python
|
||||
if isinstance(env_cfg, MyBenchmarkEnvConfig) or "<benchmark_name>" in env_cfg.type:
|
||||
preprocessor_steps.append(MyBenchmarkProcessorStep())
|
||||
```
|
||||
|
||||
### 4. Env processor (optional — `src/lerobot/processor/env_processor.py`)
|
||||
|
||||
Only needed if your benchmark requires observation transforms beyond what `preprocess_observation()` handles (e.g. image flipping, coordinate conversion):
|
||||
|
||||
```python
|
||||
@dataclass
|
||||
@ProcessorStepRegistry.register(name="<benchmark>_processor")
|
||||
class MyBenchmarkProcessorStep(ObservationProcessorStep):
|
||||
def _process_observation(self, observation):
|
||||
processed = observation.copy()
|
||||
# your transforms here
|
||||
return processed
|
||||
|
||||
def transform_features(self, features):
|
||||
return features # update if shapes change
|
||||
|
||||
def observation(self, observation):
|
||||
return self._process_observation(observation)
|
||||
```
|
||||
|
||||
See `LiberoProcessorStep` for a full example (image rotation, quaternion-to-axis-angle conversion).
|
||||
|
||||
### 5. Dependencies (`pyproject.toml`)
|
||||
|
||||
Add a new optional-dependency group:
|
||||
|
||||
```toml
|
||||
mybenchmark = ["my-benchmark-pkg==1.2.3", "lerobot[scipy-dep]"]
|
||||
```
|
||||
|
||||
Pinning rules:
|
||||
|
||||
- **Always pin** benchmark packages to exact versions for reproducibility (e.g. `metaworld==3.0.0`).
|
||||
- **Add platform markers** when needed (e.g. `; sys_platform == 'linux'`).
|
||||
- **Pin fragile transitive deps** if known (e.g. `gymnasium==1.1.0` for Meta-World).
|
||||
- **Document constraints** in your benchmark doc page.
|
||||
|
||||
Users install with:
|
||||
|
||||
```bash
|
||||
pip install -e ".[mybenchmark]"
|
||||
```
|
||||
|
||||
### 6. Documentation (`docs/source/<benchmark>.mdx`)
|
||||
|
||||
Write a user-facing page following the template in the next section. See `docs/source/libero.mdx` and `docs/source/metaworld.mdx` for full examples.
|
||||
|
||||
### 7. Table of contents (`docs/source/_toctree.yml`)
|
||||
|
||||
Add your benchmark to the "Benchmarks" section:
|
||||
|
||||
```yaml
|
||||
- sections:
|
||||
- local: libero
|
||||
title: LIBERO
|
||||
- local: metaworld
|
||||
title: Meta-World
|
||||
- local: envhub_isaaclab_arena
|
||||
title: NVIDIA IsaacLab Arena Environments
|
||||
- local: <your_benchmark>
|
||||
title: <Your Benchmark Name>
|
||||
title: "Benchmarks"
|
||||
```
|
||||
|
||||
## Verifying your integration
|
||||
|
||||
After completing the steps above, confirm that everything works:
|
||||
|
||||
1. **Install** — `pip install -e ".[mybenchmark]"` and verify the dependency group installs cleanly.
|
||||
2. **Smoke test env creation** — call `make_env()` with your config in Python, check that the returned dict has the expected `{suite: {task_id: VectorEnv}}` shape, and that `reset()` returns observations with the right keys.
|
||||
3. **Run a full eval** — `lerobot-eval --env.type=<name> --env.task=<task> --eval.n_episodes=1 --eval.batch_size=1 --policy.path=<any_compatible_policy>` to exercise the full pipeline end-to-end.
|
||||
4. **Check success detection** — verify that `info["is_success"]` flips to `True` when the task is actually completed. This is what the eval loop uses to compute success rates.
|
||||
|
||||
## Writing a benchmark doc page
|
||||
|
||||
Each benchmark `.mdx` page should include:
|
||||
|
||||
- **Title and description** — 1-2 paragraphs on what the benchmark tests and why it matters.
|
||||
- **Links** — paper, GitHub repo, project website (if available).
|
||||
- **Overview image or GIF.**
|
||||
- **Available tasks** — table of task suites with counts and brief descriptions.
|
||||
- **Installation** — `pip install -e ".[<benchmark>]"` plus any extra steps (env vars, system packages).
|
||||
- **Evaluation** — recommended `lerobot-eval` command with `n_episodes` and `batch_size` for reproducible results. Include single-task and multi-task examples if applicable.
|
||||
- **Policy inputs and outputs** — observation keys with shapes, action space description.
|
||||
- **Recommended evaluation episodes** — how many episodes per task is standard.
|
||||
- **Training** — example `lerobot-train` command.
|
||||
- **Reproducing published results** — link to pretrained model, eval command, results table (if available).
|
||||
|
||||
See `docs/source/libero.mdx` and `docs/source/metaworld.mdx` for complete examples.
|
||||
+90
-81
@@ -1,36 +1,61 @@
|
||||
# LIBERO
|
||||
|
||||
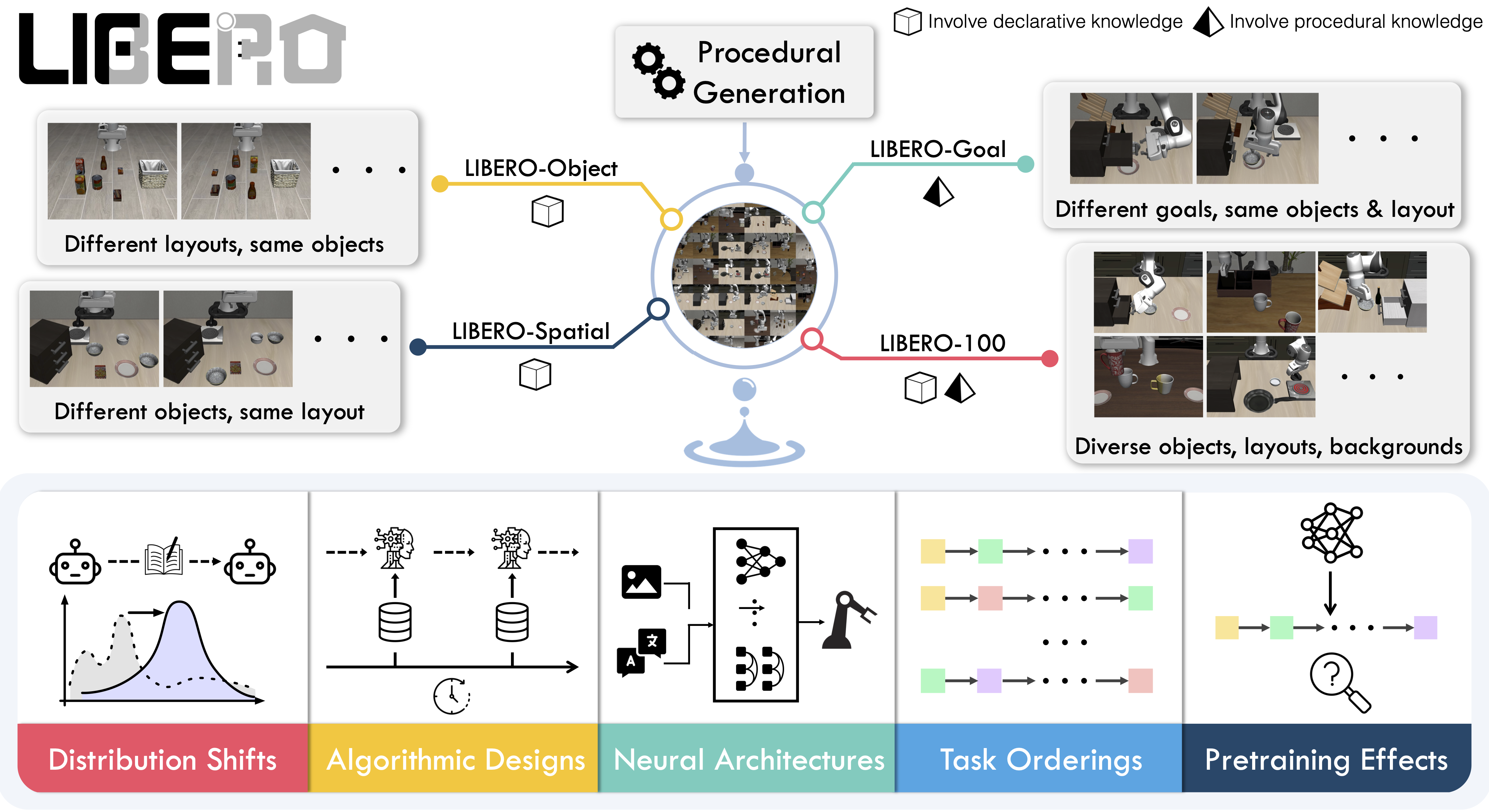
**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers.
|
||||
LIBERO is a benchmark designed to study **lifelong robot learning** — the idea that robots need to keep learning and adapting with their users over time, not just be pretrained once. It provides a set of standardized manipulation tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other's work.
|
||||
|
||||
- 📄 [LIBERO paper](https://arxiv.org/abs/2306.03310)
|
||||
- 💻 [Original LIBERO repo](https://github.com/Lifelong-Robot-Learning/LIBERO)
|
||||
|
||||
To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
|
||||
|
||||
LIBERO includes **five task suites**:
|
||||
|
||||
- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
|
||||
- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
|
||||
- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
|
||||
- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
|
||||
- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
|
||||
|
||||
Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
|
||||
- Paper: [Benchmarking Knowledge Transfer for Lifelong Robot Learning](https://arxiv.org/abs/2306.03310)
|
||||
- GitHub: [Lifelong-Robot-Learning/LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO)
|
||||
- Project website: [libero-project.github.io](https://libero-project.github.io)
|
||||
|
||||
|
||||
|
||||
## Evaluating with LIBERO
|
||||
## Available tasks
|
||||
|
||||
At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it mainly to **evaluate [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model.
|
||||
LIBERO includes **five task suites** covering **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios:
|
||||
|
||||
LIBERO is now part of our **multi-eval supported simulation**, meaning you can benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a flag.
|
||||
| Suite | CLI name | Tasks | Description |
|
||||
| -------------- | ---------------- | ----- | -------------------------------------------------- |
|
||||
| LIBERO-Spatial | `libero_spatial` | 10 | Tasks requiring reasoning about spatial relations |
|
||||
| LIBERO-Object | `libero_object` | 10 | Tasks centered on manipulating different objects |
|
||||
| LIBERO-Goal | `libero_goal` | 10 | Goal-conditioned tasks with changing targets |
|
||||
| LIBERO-90 | `libero_90` | 90 | Short-horizon tasks from the LIBERO-100 collection |
|
||||
| LIBERO-Long | `libero_10` | 10 | Long-horizon tasks from the LIBERO-100 collection |
|
||||
|
||||
To Install LIBERO, after following LeRobot official instructions, just do:
|
||||
`pip install -e ".[libero]"`
|
||||
## Installation
|
||||
|
||||
After following the LeRobot installation instructions:
|
||||
|
||||
```bash
|
||||
pip install -e ".[libero]"
|
||||
```
|
||||
|
||||
<Tip>
|
||||
LIBERO requires Linux (`sys_platform == 'linux'`). LeRobot uses MuJoCo for simulation — set the rendering backend before training or evaluation:
|
||||
|
||||
```bash
|
||||
export MUJOCO_GL=egl # for headless servers (HPC, cloud)
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
## Evaluation
|
||||
|
||||
### Default evaluation (recommended)
|
||||
|
||||
Evaluate across the four standard suites (10 episodes per task):
|
||||
|
||||
```bash
|
||||
lerobot-eval \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=libero \
|
||||
--env.task=libero_spatial,libero_object,libero_goal,libero_10 \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=10 \
|
||||
--env.max_parallel_tasks=1
|
||||
```
|
||||
|
||||
### Single-suite evaluation
|
||||
|
||||
Evaluate a policy on one LIBERO suite:
|
||||
Evaluate on one LIBERO suite:
|
||||
|
||||
```bash
|
||||
lerobot-eval \
|
||||
@@ -42,15 +67,13 @@ lerobot-eval \
|
||||
```
|
||||
|
||||
- `--env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
|
||||
- `--env.task_ids` picks task ids to run (`[0]`, `[1,2,3]`, etc.). Omit this flag (or set it to `null`) to run all tasks in the suite.
|
||||
- `--env.task_ids` restricts to specific task indices (`[0]`, `[1,2,3]`, etc.). Omit to run all tasks in the suite.
|
||||
- `--eval.batch_size` controls how many environments run in parallel.
|
||||
- `--eval.n_episodes` sets how many episodes to run in total.
|
||||
|
||||
---
|
||||
- `--eval.n_episodes` sets how many episodes to run per task.
|
||||
|
||||
### Multi-suite evaluation
|
||||
|
||||
Benchmark a policy across multiple suites at once:
|
||||
Benchmark a policy across multiple suites at once by passing a comma-separated list:
|
||||
|
||||
```bash
|
||||
lerobot-eval \
|
||||
@@ -61,50 +84,49 @@ lerobot-eval \
|
||||
--eval.n_episodes=2
|
||||
```
|
||||
|
||||
- Pass a comma-separated list to `--env.task` for multi-suite evaluation.
|
||||
### Control mode
|
||||
|
||||
### Control Mode
|
||||
LIBERO supports two control modes — `relative` (default) and `absolute`. Different VLA checkpoints are trained with different action parameterizations, so make sure the mode matches your policy:
|
||||
|
||||
LIBERO now supports two control modes: relative and absolute. This matters because different VLA checkpoints are trained with different mode of action to output hence control parameterizations.
|
||||
You can switch them with: `env.control_mode = "relative"` and `env.control_mode = "absolute"`
|
||||
```bash
|
||||
--env.control_mode=relative # or "absolute"
|
||||
```
|
||||
|
||||
### Policy inputs and outputs
|
||||
|
||||
When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
|
||||
**Observations:**
|
||||
|
||||
- **Observations**
|
||||
- `observation.state` – proprioceptive features (agent state).
|
||||
- `observation.images.image` – main camera view (`agentview_image`).
|
||||
- `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
|
||||
- `observation.state` — 8-dim proprioceptive features (eef position, axis-angle orientation, gripper qpos)
|
||||
- `observation.images.image` — main camera view (`agentview_image`), HWC uint8
|
||||
- `observation.images.image2` — wrist camera view (`robot0_eye_in_hand_image`), HWC uint8
|
||||
|
||||
⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any multi-modal visual features. Always ensure that your policy config `input_features` use the same naming keys, and that your dataset metadata keys follow this convention during evaluation.
|
||||
If your data contains different keys, you must rename the observations to match what the policy expects, since naming keys are encoded inside the normalization statistics layer.
|
||||
This will be fixed with the upcoming Pipeline PR.
|
||||
<Tip warning={true}>
|
||||
LeRobot enforces the `.images.*` prefix for visual features. Ensure your
|
||||
policy config `input_features` use the same naming keys, and that your dataset
|
||||
metadata keys follow this convention. If your data contains different keys,
|
||||
you must rename the observations to match what the policy expects, since
|
||||
naming keys are encoded inside the normalization statistics layer.
|
||||
</Tip>
|
||||
|
||||
- **Actions**
|
||||
- Continuous control values in a `Box(-1, 1, shape=(7,))` space.
|
||||
**Actions:**
|
||||
|
||||
We also provide a notebook for quick testing:
|
||||
Training with LIBERO
|
||||
- Continuous control in `Box(-1, 1, shape=(7,))` — 6D end-effector delta + 1D gripper
|
||||
|
||||
## Training with LIBERO
|
||||
### Recommended evaluation episodes
|
||||
|
||||
When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
|
||||
For reproducible benchmarking, use **10 episodes per task** across all four standard suites (Spatial, Object, Goal, Long). This gives 400 total episodes and matches the protocol used for published results.
|
||||
|
||||
The environment expects:
|
||||
## Training
|
||||
|
||||
- `observation.state` → 8-dim agent state
|
||||
- `observation.images.image` → main camera (`agentview_image`)
|
||||
- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
|
||||
### Dataset
|
||||
|
||||
⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code.
|
||||
To avoid potential mismatches and key errors, we provide a **preprocessed LIBERO dataset** that is fully compatible with the current LeRobot codebase and requires no additional manipulation:
|
||||
👉 [HuggingFaceVLA/libero](https://huggingface.co/datasets/HuggingFaceVLA/libero)
|
||||
We provide a preprocessed LIBERO dataset fully compatible with LeRobot:
|
||||
|
||||
For reference, here is the **original dataset** published by Physical Intelligence:
|
||||
👉 [physical-intelligence/libero](https://huggingface.co/datasets/physical-intelligence/libero)
|
||||
- [HuggingFaceVLA/libero](https://huggingface.co/datasets/HuggingFaceVLA/libero)
|
||||
|
||||
---
|
||||
For reference, the original dataset published by Physical Intelligence:
|
||||
|
||||
- [physical-intelligence/libero](https://huggingface.co/datasets/physical-intelligence/libero)
|
||||
|
||||
### Example training command
|
||||
|
||||
@@ -121,52 +143,39 @@ lerobot-train \
|
||||
--batch_size=4 \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=1 \
|
||||
--eval_freq=1000 \
|
||||
--eval_freq=1000
|
||||
```
|
||||
|
||||
---
|
||||
## Reproducing published results
|
||||
|
||||
### Note on rendering
|
||||
We reproduce the results of Pi0.5 on the LIBERO benchmark. We take the Physical Intelligence LIBERO base model (`pi05_libero`) and finetune for an additional 6k steps in bfloat16, with batch size of 256 on 8 H100 GPUs using the [HuggingFace LIBERO dataset](https://huggingface.co/datasets/HuggingFaceVLA/libero).
|
||||
|
||||
LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
|
||||
The finetuned model: [lerobot/pi05_libero_finetuned](https://huggingface.co/lerobot/pi05_libero_finetuned)
|
||||
|
||||
- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
|
||||
|
||||
## Reproducing π₀.₅ results
|
||||
|
||||
We reproduce the results of π₀.₅ on the LIBERO benchmark using the LeRobot implementation. We take the Physical Intelligence LIBERO base model (`pi05_libero`) and finetune for an additional 6k steps in bfloat16, with batch size of 256 on 8 H100 GPUs using the [HuggingFace LIBERO dataset](https://huggingface.co/datasets/HuggingFaceVLA/libero).
|
||||
|
||||
The finetuned model can be found here:
|
||||
|
||||
- **π₀.₅ LIBERO**: [lerobot/pi05_libero_finetuned](https://huggingface.co/lerobot/pi05_libero_finetuned)
|
||||
|
||||
We then evaluate the finetuned model using the LeRobot LIBERO implementation, by running the following command:
|
||||
### Evaluation command
|
||||
|
||||
```bash
|
||||
lerobot-eval \
|
||||
--output_dir=/logs/ \
|
||||
--output_dir=./eval_logs/ \
|
||||
--env.type=libero \
|
||||
--env.task=libero_spatial,libero_object,libero_goal,libero_10 \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=10 \
|
||||
--policy.path=pi05_libero_finetuned \
|
||||
--policy.n_action_steps=10 \
|
||||
--output_dir=./eval_logs/ \
|
||||
--env.max_parallel_tasks=1
|
||||
```
|
||||
|
||||
**Note:** We set `n_action_steps=10`, similar to the original OpenPI implementation.
|
||||
We set `n_action_steps=10`, matching the original OpenPI implementation.
|
||||
|
||||
### Results
|
||||
|
||||
We obtain the following results on the LIBERO benchmark:
|
||||
| Model | LIBERO Spatial | LIBERO Object | LIBERO Goal | LIBERO 10 | Average |
|
||||
| ------------------- | -------------- | ------------- | ----------- | --------- | -------- |
|
||||
| **Pi0.5 (LeRobot)** | 97.0 | 99.0 | 98.0 | 96.0 | **97.5** |
|
||||
|
||||
| Model | LIBERO Spatial | LIBERO Object | LIBERO Goal | LIBERO 10 | Average |
|
||||
| -------- | -------------- | ------------- | ----------- | --------- | -------- |
|
||||
| **π₀.₅** | 97.0 | 99.0 | 98.0 | 96.0 | **97.5** |
|
||||
These results are consistent with the [original results](https://github.com/Physical-Intelligence/openpi/tree/main/examples/libero#results) reported by Physical Intelligence:
|
||||
|
||||
These results are consistent with the original [results](https://github.com/Physical-Intelligence/openpi/tree/main/examples/libero#results) reported by Physical Intelligence:
|
||||
|
||||
| Model | LIBERO Spatial | LIBERO Object | LIBERO Goal | LIBERO 10 | Average |
|
||||
| -------- | -------------- | ------------- | ----------- | --------- | --------- |
|
||||
| **π₀.₅** | 98.8 | 98.2 | 98.0 | 92.4 | **96.85** |
|
||||
| Model | LIBERO Spatial | LIBERO Object | LIBERO Goal | LIBERO 10 | Average |
|
||||
| ------------------ | -------------- | ------------- | ----------- | --------- | --------- |
|
||||
| **Pi0.5 (OpenPI)** | 98.8 | 98.2 | 98.0 | 92.4 | **96.85** |
|
||||
|
||||
+97
-47
@@ -1,32 +1,111 @@
|
||||
# Meta-World
|
||||
|
||||
Meta-World is a well-designed, open-source simulation benchmark for multi-task and meta reinforcement learning in continuous-control robotic manipulation. It gives researchers a shared, realistic playground to test whether algorithms can _learn many different tasks_ and _generalize quickly to new ones_ — two central challenges for real-world robotics.
|
||||
Meta-World is an open-source simulation benchmark for **multi-task and meta reinforcement learning** in continuous-control robotic manipulation. It bundles 50 diverse manipulation tasks using everyday objects and a common tabletop Sawyer arm, providing a standardized playground to test whether algorithms can learn many different tasks and generalize quickly to new ones.
|
||||
|
||||
- 📄 [MetaWorld paper](https://arxiv.org/pdf/1910.10897)
|
||||
- 💻 [Original MetaWorld repo](https://github.com/Farama-Foundation/Metaworld)
|
||||
- Paper: [Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning](https://arxiv.org/abs/1910.10897)
|
||||
- GitHub: [Farama-Foundation/Metaworld](https://github.com/Farama-Foundation/Metaworld)
|
||||
- Project website: [metaworld.farama.org](https://metaworld.farama.org)
|
||||
|
||||

|
||||
|
||||
## Why Meta-World matters
|
||||
## Available tasks
|
||||
|
||||
- **Diverse, realistic tasks.** Meta-World bundles a large suite of simulated manipulation tasks (50 in the MT50 suite) using everyday objects and a common tabletop Sawyer arm. This diversity exposes algorithms to a wide variety of dynamics, contacts and goal specifications while keeping a consistent control and observation structure.
|
||||
- **Focus on generalization and multi-task learning.** By evaluating across task distributions that share structure but differ in goals and objects, Meta-World reveals whether an agent truly learns transferable skills rather than overfitting to a narrow task.
|
||||
- **Standardized evaluation protocol.** It provides clear evaluation modes and difficulty splits, so different methods can be compared fairly across easy, medium, hard and very-hard regimes.
|
||||
- **Empirical insight.** Past evaluations on Meta-World show impressive progress on some fronts, but also highlight that current multi-task and meta-RL methods still struggle with large, diverse task sets. That gap points to important research directions.
|
||||
Meta-World provides 50 tasks organized into difficulty groups. In LeRobot, you can evaluate on individual tasks, difficulty groups, or the full MT50 suite:
|
||||
|
||||
## What it enables in LeRobot
|
||||
| Group | CLI name | Tasks | Description |
|
||||
| ---------- | -------------------- | ----- | ------------------------------------------------------ |
|
||||
| Easy | `easy` | 28 | Tasks with simple dynamics and single-step goals |
|
||||
| Medium | `medium` | 11 | Tasks requiring multi-step reasoning |
|
||||
| Hard | `hard` | 6 | Tasks with complex contacts and precise manipulation |
|
||||
| Very Hard | `very_hard` | 5 | The most challenging tasks in the suite |
|
||||
| MT50 (all) | Comma-separated list | 50 | All 50 tasks — the most challenging multi-task setting |
|
||||
|
||||
In LeRobot, you can evaluate any policy or vision-language-action (VLA) model on Meta-World tasks and get a clear success-rate measure. The integration is designed to be straightforward:
|
||||
You can also pass individual task names directly (e.g., `assembly-v3`, `dial-turn-v3`).
|
||||
|
||||
- We provide a LeRobot-ready dataset for Meta-World (MT50) on the HF Hub: `https://huggingface.co/datasets/lerobot/metaworld_mt50`.
|
||||
- This dataset is formatted for the MT50 evaluation that uses all 50 tasks (the most challenging multi-task setting).
|
||||
- MT50 gives the policy a one-hot task vector and uses fixed object/goal positions for consistency.
|
||||
We provide a LeRobot-ready dataset for Meta-World MT50 on the HF Hub: [lerobot/metaworld_mt50](https://huggingface.co/datasets/lerobot/metaworld_mt50). This dataset is formatted for the MT50 evaluation that uses all 50 tasks with fixed object/goal positions and one-hot task vectors for consistency.
|
||||
|
||||
- Task descriptions and the exact keys required for evaluation are available in the repo/dataset — use these to ensure your policy outputs the right success signals.
|
||||
## Installation
|
||||
|
||||
## Quick start, train a SmolVLA policy on Meta-World
|
||||
After following the LeRobot installation instructions:
|
||||
|
||||
Example command to train a SmolVLA policy on a subset of tasks:
|
||||
```bash
|
||||
pip install -e ".[metaworld]"
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
If you encounter an `AssertionError: ['human', 'rgb_array', 'depth_array']` when running Meta-World environments, this is a mismatch between Meta-World and your Gymnasium version. Fix it with:
|
||||
|
||||
```bash
|
||||
pip install "gymnasium==1.1.0"
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
## Evaluation
|
||||
|
||||
### Default evaluation (recommended)
|
||||
|
||||
Evaluate on the medium difficulty split (a good balance of coverage and compute):
|
||||
|
||||
```bash
|
||||
lerobot-eval \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=metaworld \
|
||||
--env.task=medium \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=10
|
||||
```
|
||||
|
||||
### Single-task evaluation
|
||||
|
||||
Evaluate on a specific task:
|
||||
|
||||
```bash
|
||||
lerobot-eval \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=metaworld \
|
||||
--env.task=assembly-v3 \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=10
|
||||
```
|
||||
|
||||
### Multi-task evaluation
|
||||
|
||||
Evaluate across multiple tasks or difficulty groups:
|
||||
|
||||
```bash
|
||||
lerobot-eval \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=metaworld \
|
||||
--env.task=assembly-v3,dial-turn-v3,handle-press-side-v3 \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=10
|
||||
```
|
||||
|
||||
- `--env.task` accepts explicit task lists (comma-separated) or difficulty groups (e.g., `easy`, `medium`, `hard`, `very_hard`).
|
||||
- `--eval.batch_size` controls how many environments run in parallel.
|
||||
- `--eval.n_episodes` sets how many episodes to run per task.
|
||||
|
||||
### Policy inputs and outputs
|
||||
|
||||
**Observations:**
|
||||
|
||||
- `observation.image` — single camera view (`corner2`), 480x480 HWC uint8
|
||||
- `observation.state` — 4-dim proprioceptive state (end-effector position + gripper)
|
||||
|
||||
**Actions:**
|
||||
|
||||
- Continuous control in `Box(-1, 1, shape=(4,))` — 3D end-effector delta + 1D gripper
|
||||
|
||||
### Recommended evaluation episodes
|
||||
|
||||
For reproducible benchmarking, use **10 episodes per task**. For the full MT50 suite this gives 500 total episodes. If you care about generalization, run on the full MT50 — it is intentionally challenging and reveals strengths/weaknesses better than a few narrow tasks.
|
||||
|
||||
## Training
|
||||
|
||||
### Example training command
|
||||
|
||||
Train a SmolVLA policy on a subset of Meta-World tasks:
|
||||
|
||||
```bash
|
||||
lerobot-train \
|
||||
@@ -44,37 +123,8 @@ lerobot-train \
|
||||
--eval_freq=1000
|
||||
```
|
||||
|
||||
Notes:
|
||||
|
||||
- `--env.task` accepts explicit task lists (comma separated) or difficulty groups (e.g., `env.task="hard"`).
|
||||
- Adjust `batch_size`, `steps`, and `eval_freq` to match your compute budget.
|
||||
- **Gymnasium Assertion Error**: if you encounter an error like
|
||||
`AssertionError: ['human', 'rgb_array', 'depth_array']` when running MetaWorld environments, this comes from a mismatch between MetaWorld and your Gymnasium version.
|
||||
We recommend using:
|
||||
|
||||
```bash
|
||||
pip install "gymnasium==1.1.0"
|
||||
```
|
||||
|
||||
to ensure proper compatibility.
|
||||
|
||||
## Quick start — evaluate a trained policy
|
||||
|
||||
To evaluate a trained policy on the Meta-World medium difficulty split:
|
||||
|
||||
```bash
|
||||
lerobot-eval \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=metaworld \
|
||||
--env.task=medium \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=2
|
||||
```
|
||||
|
||||
This will run episodes and return per-task success rates using the standard Meta-World evaluation keys.
|
||||
|
||||
## Practical tips
|
||||
|
||||
- If you care about generalization, run on the full MT50 suite — it’s intentionally challenging and reveals strengths/weaknesses better than a few narrow tasks.
|
||||
- Use the one-hot task conditioning for multi-task training (MT10 / MT50 conventions) so policies have explicit task context.
|
||||
- Use the one-hot task conditioning for multi-task training (MT10/MT50 conventions) so policies have explicit task context.
|
||||
- Inspect the dataset task descriptions and the `info["is_success"]` keys when writing post-processing or logging so your success metrics line up with the benchmark.
|
||||
- Adjust `batch_size`, `steps`, and `eval_freq` to match your compute budget.
|
||||
|
||||
Reference in New Issue
Block a user