mirror of
https://github.com/huggingface/lerobot.git
synced 2026-07-08 02:22:02 +00:00
Merge branch 'main' into feat/add_pi
This commit is contained in:
@@ -33,8 +33,9 @@
|
||||
title: π₀ (Pi0)
|
||||
- local: pi05
|
||||
title: π₀.₅ (Pi05)
|
||||
- local: libero
|
||||
title: Using Libero
|
||||
title: "Policies"
|
||||
|
||||
- sections:
|
||||
- local: introduction_processors
|
||||
title: Introduction to Robot Processors
|
||||
|
||||
@@ -8,6 +8,7 @@ This docs will guide you to:
|
||||
- Record a dataset and push it to the Hub
|
||||
- Load datasets for training with `LeRobotDataset`
|
||||
- Stream datasets without downloading using `StreamingLeRobotDataset`
|
||||
- Apply image transforms for data augmentation during training
|
||||
- Migrate existing `v2.1` datasets to `v3.0`
|
||||
|
||||
## What’s new in `v3`
|
||||
@@ -150,6 +151,117 @@ dataset = StreamingLeRobotDataset(repo_id) # streams directly from the Hub
|
||||
</figure>
|
||||
</div>
|
||||
|
||||
## Image transforms
|
||||
|
||||
Image transforms are data augmentations applied to camera frames during training to improve model robustness and generalization. LeRobot supports various transforms including brightness, contrast, saturation, hue, and sharpness adjustments.
|
||||
|
||||
### Using transforms during dataset creation/recording
|
||||
|
||||
Currently, transforms are applied during **training time only**, not during recording. When you create or record a dataset, the raw images are stored without transforms. This allows you to experiment with different augmentations later without re-recording data.
|
||||
|
||||
### Adding transforms to existing datasets (API)
|
||||
|
||||
Use the `image_transforms` parameter when loading a dataset for training:
|
||||
|
||||
```python
|
||||
from lerobot.datasets.lerobot_dataset import LeRobotDataset
|
||||
from lerobot.datasets.transforms import ImageTransforms, ImageTransformsConfig, ImageTransformConfig
|
||||
|
||||
# Option 1: Use default transform configuration (disabled by default)
|
||||
transforms_config = ImageTransformsConfig(
|
||||
enable=True, # Enable transforms
|
||||
max_num_transforms=3, # Apply up to 3 transforms per frame
|
||||
random_order=False, # Apply in standard order
|
||||
)
|
||||
transforms = ImageTransforms(transforms_config)
|
||||
|
||||
dataset = LeRobotDataset(
|
||||
repo_id="your-username/your-dataset",
|
||||
image_transforms=transforms
|
||||
)
|
||||
|
||||
# Option 2: Create custom transform configuration
|
||||
custom_transforms_config = ImageTransformsConfig(
|
||||
enable=True,
|
||||
max_num_transforms=2,
|
||||
random_order=True,
|
||||
tfs={
|
||||
"brightness": ImageTransformConfig(
|
||||
weight=1.0,
|
||||
type="ColorJitter",
|
||||
kwargs={"brightness": (0.7, 1.3)} # Adjust brightness range
|
||||
),
|
||||
"contrast": ImageTransformConfig(
|
||||
weight=2.0, # Higher weight = more likely to be selected
|
||||
type="ColorJitter",
|
||||
kwargs={"contrast": (0.8, 1.2)}
|
||||
),
|
||||
"sharpness": ImageTransformConfig(
|
||||
weight=0.5, # Lower weight = less likely to be selected
|
||||
type="SharpnessJitter",
|
||||
kwargs={"sharpness": (0.3, 2.0)}
|
||||
),
|
||||
}
|
||||
)
|
||||
|
||||
dataset = LeRobotDataset(
|
||||
repo_id="your-username/your-dataset",
|
||||
image_transforms=ImageTransforms(custom_transforms_config)
|
||||
)
|
||||
|
||||
# Option 3: Use pure torchvision transforms
|
||||
from torchvision.transforms import v2
|
||||
|
||||
torchvision_transforms = v2.Compose([
|
||||
v2.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
|
||||
v2.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
|
||||
])
|
||||
|
||||
dataset = LeRobotDataset(
|
||||
repo_id="your-username/your-dataset",
|
||||
image_transforms=torchvision_transforms
|
||||
)
|
||||
```
|
||||
|
||||
### Available transform types
|
||||
|
||||
LeRobot provides several transform types:
|
||||
|
||||
- **`ColorJitter`**: Adjusts brightness, contrast, saturation, and hue
|
||||
- **`SharpnessJitter`**: Randomly adjusts image sharpness
|
||||
- **`Identity`**: No transformation (useful for testing)
|
||||
|
||||
You can also use any `torchvision.transforms.v2` transform by passing it directly to the `image_transforms` parameter.
|
||||
|
||||
### Configuration options
|
||||
|
||||
- **`enable`**: Enable/disable transforms (default: `False`)
|
||||
- **`max_num_transforms`**: Maximum number of transforms applied per frame (default: `3`)
|
||||
- **`random_order`**: Apply transforms in random order vs. standard order (default: `False`)
|
||||
- **`weight`**: Sampling probability for each transform (higher = more likely, if sum of weights is not 1, they will be normalized)
|
||||
- **`kwargs`**: Transform-specific parameters (e.g., brightness range)
|
||||
|
||||
### Visualizing transforms
|
||||
|
||||
Use the visualization script to preview how transforms affect your data:
|
||||
|
||||
```bash
|
||||
python -m lerobot.scripts.visualize_image_transforms \
|
||||
--repo-id=your-username/your-dataset \
|
||||
--output-dir=./transform_examples \
|
||||
--n-examples=5
|
||||
```
|
||||
|
||||
This saves example images showing the effect of each transform, helping you tune parameters.
|
||||
|
||||
### Best practices
|
||||
|
||||
- **Start conservative**: Begin with small ranges (e.g., brightness 0.9-1.1) and increase gradually
|
||||
- **Test first**: Use the visualization script to ensure transforms look reasonable
|
||||
- **Monitor training**: Strong augmentations can hurt performance if too aggressive
|
||||
- **Match your domain**: If your robot operates in varying lighting, use brightness/contrast transforms
|
||||
- **Combine wisely**: Using too many transforms simultaneously can make training unstable
|
||||
|
||||
## Migrate `v2.1` → `v3.0`
|
||||
|
||||
A converter aggregates per‑episode files into larger shards and writes episode offsets/metadata. Convert your dataset using the instructions below.
|
||||
|
||||
@@ -0,0 +1,126 @@
|
||||
# LIBERO
|
||||
|
||||
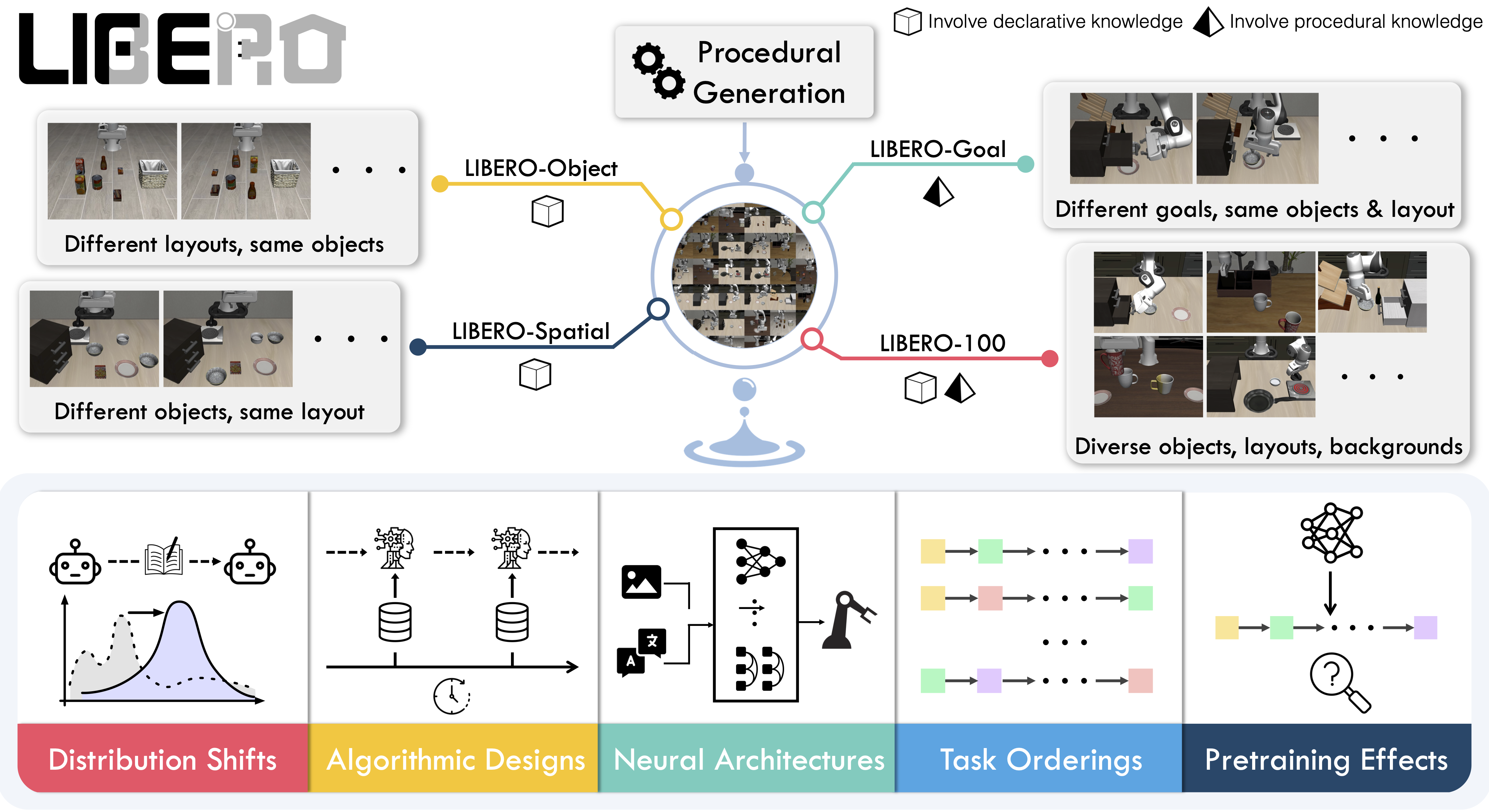
**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers.
|
||||
|
||||
- 📄 [LIBERO paper](https://arxiv.org/abs/2306.03310)
|
||||
- 💻 [Original LIBERO repo](https://github.com/Lifelong-Robot-Learning/LIBERO)
|
||||
|
||||
To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
|
||||
|
||||
LIBERO includes **five task suites**:
|
||||
|
||||
- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
|
||||
- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
|
||||
- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
|
||||
- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
|
||||
- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
|
||||
|
||||
Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
|
||||
|
||||
|
||||
|
||||
## Evaluating with LIBERO
|
||||
|
||||
At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it mainly to **evaluate [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model.
|
||||
|
||||
LIBERO is now part of our **multi-eval supported simulation**, meaning you can benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a flag.
|
||||
|
||||
To Install LIBERO, after following LeRobot official instructions, just do:
|
||||
`pip install -e ".[libero]"`
|
||||
|
||||
### Single-suite evaluation
|
||||
|
||||
Evaluate a policy on one LIBERO suite:
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/eval.py \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=libero \
|
||||
--env.task=libero_object \
|
||||
--eval.batch_size=2 \
|
||||
--eval.n_episodes=3
|
||||
```
|
||||
|
||||
- `--env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
|
||||
- `--eval.batch_size` controls how many environments run in parallel.
|
||||
- `--eval.n_episodes` sets how many episodes to run in total.
|
||||
|
||||
---
|
||||
|
||||
### Multi-suite evaluation
|
||||
|
||||
Benchmark a policy across multiple suites at once:
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/eval.py \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=libero \
|
||||
--env.task=libero_object,libero_spatial \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=2
|
||||
```
|
||||
|
||||
- Pass a comma-separated list to `--env.task` for multi-suite evaluation.
|
||||
|
||||
### Policy inputs and outputs
|
||||
|
||||
When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
|
||||
|
||||
- **Observations**
|
||||
- `observation.state` – proprioceptive features (agent state).
|
||||
- `observation.images.image` – main camera view (`agentview_image`).
|
||||
- `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
|
||||
|
||||
⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any multi-modal visual features. Always ensure that your policy config `input_features` use the same naming keys, and that your dataset metadata keys follow this convention during evaluation.
|
||||
If your data contains different keys, you must rename the observations to match what the policy expects, since naming keys are encoded inside the normalization statistics layer.
|
||||
This will be fixed with the upcoming Pipeline PR.
|
||||
|
||||
- **Actions**
|
||||
- Continuous control values in a `Box(-1, 1, shape=(7,))` space.
|
||||
|
||||
We also provide a notebook for quick testing:
|
||||
Training with LIBERO
|
||||
|
||||
## Training with LIBERO
|
||||
|
||||
When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
|
||||
|
||||
The environment expects:
|
||||
|
||||
- `observation.state` → 8-dim agent state
|
||||
- `observation.images.image` → main camera (`agentview_image`)
|
||||
- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
|
||||
|
||||
⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code.
|
||||
To avoid potential mismatches and key errors, we provide a **preprocessed LIBERO dataset** that is fully compatible with the current LeRobot codebase and requires no additional manipulation:
|
||||
👉 [HuggingFaceVLA/libero](https://huggingface.co/datasets/HuggingFaceVLA/libero)
|
||||
|
||||
For reference, here is the **original dataset** published by Physical Intelligence:
|
||||
👉 [physical-intelligence/libero](https://huggingface.co/datasets/physical-intelligence/libero)
|
||||
|
||||
---
|
||||
|
||||
### Example training command
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/train.py \
|
||||
--policy.type=smolvla \
|
||||
--policy.repo_id=${HF_USER}/libero-test \
|
||||
--dataset.repo_id=jadechoghari/smol-libero3 \
|
||||
--env.type=libero \
|
||||
--env.task=libero_10 \
|
||||
--output_dir=./outputs/ \
|
||||
--steps=100000 \
|
||||
--batch_size=4 \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=1 \
|
||||
--eval_freq=1000 \
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Note on rendering
|
||||
|
||||
LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
|
||||
|
||||
- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
|
||||
@@ -36,7 +36,7 @@ Links:
|
||||
- iOS: Analog input `A3` controls the gripper as velocity input.
|
||||
- Android: Buttons `A` and `B` act like increment/decrement (A opens, B closes). You can tune velocity in the `GripperVelocityToJoint` step.
|
||||
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/blob/main/lerobot/phone_teleop.webp" alt="Phone teleop orientation" title="Phone teleop orientation" width="60%">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/lerobot/phone_teleop.webp" alt="Phone teleop orientation" title="Phone teleop orientation" width="40%">
|
||||
|
||||
### Step 1: Choose the platform
|
||||
|
||||
|
||||
Reference in New Issue
Block a user