mirror of
https://github.com/huggingface/lerobot.git
synced 2026-05-11 14:49:43 +00:00
Compare commits
130 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
7788db7838 | ||
|
|
d883c78a94 | ||
|
|
de42da8225 | ||
|
|
d0d714be47 | ||
|
|
7d9b469eee | ||
|
|
6db39cad58 | ||
|
|
af0676f99e | ||
|
|
b9df1a4ac5 | ||
|
|
5361346bec | ||
|
|
f0b969ae48 | ||
|
|
a9d54cbddb | ||
|
|
c5a029a28a | ||
|
|
c8163662ad | ||
|
|
376cc772ff | ||
|
|
d1eefd4e97 | ||
|
|
7a03223693 | ||
|
|
f840d2e006 | ||
|
|
e94844fa59 | ||
|
|
990f8e9cc9 | ||
|
|
6ce2a00135 | ||
|
|
bf90efa7e1 | ||
|
|
5b4ac3068e | ||
|
|
dbe3406a69 | ||
|
|
1785767e61 | ||
|
|
afd833f49e | ||
|
|
2234b851c0 | ||
|
|
e4a214d890 | ||
|
|
e8438aac59 | ||
|
|
8fe977118b | ||
|
|
d09b2a28af | ||
|
|
f2530570e0 | ||
|
|
8567ab60d8 | ||
|
|
9784123463 | ||
|
|
4c2add41d7 | ||
|
|
a19d7fb6bf | ||
|
|
565c992589 | ||
|
|
96cc634a66 | ||
|
|
b044f3104b | ||
|
|
384ec52ec7 | ||
|
|
8d1434c069 | ||
|
|
f613a37cd2 | ||
|
|
494aa576b2 | ||
|
|
514625a7f6 | ||
|
|
9f7bfeb419 | ||
|
|
aa40c8c813 | ||
|
|
d36bdac114 | ||
|
|
ff1666b216 | ||
|
|
c57d3a9688 | ||
|
|
9ae11a087d | ||
|
|
21e63b505f | ||
|
|
e9e7eb827a | ||
|
|
ac323b0113 | ||
|
|
b028907d21 | ||
|
|
2eafcc7ca1 | ||
|
|
b3b57a8288 | ||
|
|
eaaf1c1766 | ||
|
|
3bc3bf0391 | ||
|
|
8c5fe10d6c | ||
|
|
8178a06b90 | ||
|
|
9ea8bd029c | ||
|
|
bd5c264c49 | ||
|
|
5c628f1700 | ||
|
|
9beafe0c19 | ||
|
|
27c9db60a6 | ||
|
|
fda5fb5e94 | ||
|
|
5f5438d6fa | ||
|
|
2b779cd6c6 | ||
|
|
3886af42a5 | ||
|
|
38f7229078 | ||
|
|
504421949c | ||
|
|
28b9efc04f | ||
|
|
abba423e28 | ||
|
|
47a81c4150 | ||
|
|
1ba896598e | ||
|
|
61e55830da | ||
|
|
b7522da85d | ||
|
|
98dc053e6d | ||
|
|
bbff93d20d | ||
|
|
32c1649085 | ||
|
|
eb564f8ddb | ||
|
|
a2958a8e0c | ||
|
|
8f1679f309 | ||
|
|
b1473f11c8 | ||
|
|
7b556079d8 | ||
|
|
e91a773b93 | ||
|
|
a9bd67eae9 | ||
|
|
4a4ac759ec | ||
|
|
7dd8e015f8 | ||
|
|
af2960c33e | ||
|
|
a36e4619ad | ||
|
|
b397a757bb | ||
|
|
92adf2218f | ||
|
|
f3614dd812 | ||
|
|
b23b7a5bd7 | ||
|
|
6ff5f318b2 | ||
|
|
2eae751977 | ||
|
|
894878039d | ||
|
|
ab72471dda | ||
|
|
23849e0cb8 | ||
|
|
cb18fc07ef | ||
|
|
440e22c184 | ||
|
|
28b69bf8ba | ||
|
|
b997fdde96 | ||
|
|
6f975cf576 | ||
|
|
2688731064 | ||
|
|
fe20437b62 | ||
|
|
ff861ba869 | ||
|
|
4be3942cbc | ||
|
|
fd5afdfbf0 | ||
|
|
8d2c66abd2 | ||
|
|
afad90ffaa | ||
|
|
f5091448a8 | ||
|
|
cc46497f4c | ||
|
|
5d25f5bd40 | ||
|
|
ce83752f16 | ||
|
|
4ed6cf159d | ||
|
|
7626d26e6a | ||
|
|
14a59f576b | ||
|
|
eb3649292b | ||
|
|
ac0993c2e3 | ||
|
|
c20bf75ba0 | ||
|
|
a25480d363 | ||
|
|
4c19a71d7c | ||
|
|
d2684d41cd | ||
|
|
4e76c1f88c | ||
|
|
3bf0c19be7 | ||
|
|
ad4f510262 | ||
|
|
9124b36b0a | ||
|
|
4bc356b7f3 | ||
|
|
21a961ecbb |
@@ -19,6 +19,8 @@
|
||||
title: Train RL in Simulation
|
||||
- local: async
|
||||
title: Use Async Inference
|
||||
- local: libero
|
||||
title: Using LIBERO
|
||||
title: "Tutorials"
|
||||
- sections:
|
||||
- local: smolvla
|
||||
|
||||
@@ -0,0 +1,230 @@
|
||||
# LIBERO
|
||||
|
||||
**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers. The benchmark was first introduced in the [LIBERO paper](https://arxiv.org/abs/2306.03310) and the [original repository](https://github.com/Lifelong-Robot-Learning/LIBERO).
|
||||
|
||||
To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
|
||||
|
||||
LIBERO includes **five task suites**:
|
||||
|
||||
- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
|
||||
- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
|
||||
- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
|
||||
- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
|
||||
- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
|
||||
|
||||
Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
|
||||
|
||||
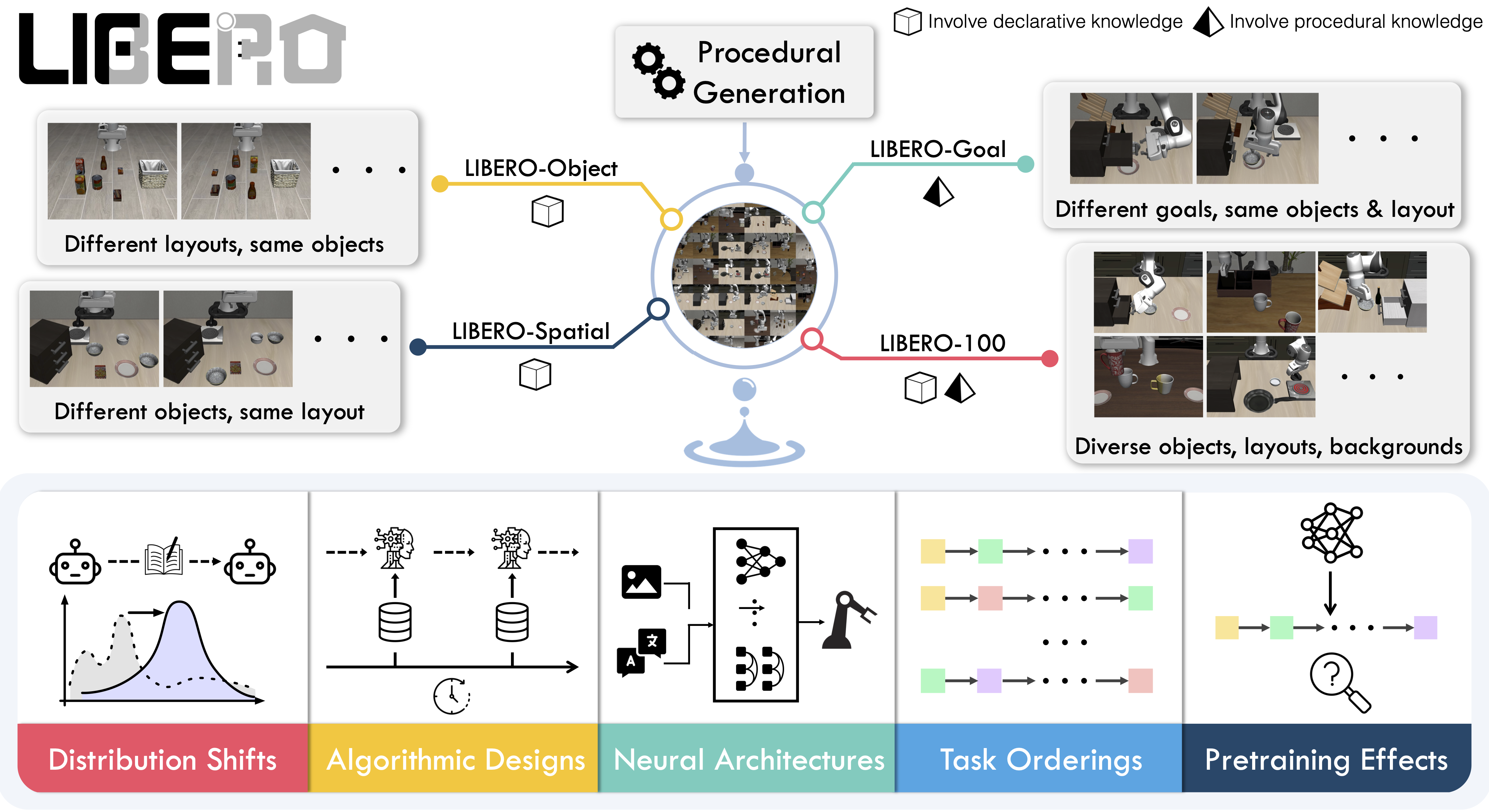
|
||||
_Figure 1: An overview of the LIBERO benchmark._
|
||||
|
||||
## Evaluating with LIBERO
|
||||
|
||||
At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it primarily to **benchmark [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model, comparing it against state-of-the-art VLA models such as Pi0, OpenVLA, Octo, and Diffusion Policy.
|
||||
|
||||
LIBERO is now part of our **multi-eval supported simulation**, allowing you to benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a single flag.
|
||||
|
||||
To install LIBERO, first follow the [LeRobot Installation Guide](https://huggingface.co/docs/lerobot/installation).
|
||||
Once LeRobot is installed, there are two options:
|
||||
|
||||
1. **Install via pip** (recommended):
|
||||
|
||||
```bash
|
||||
pip install "lerobot[libero,smolvla]"
|
||||
```
|
||||
|
||||
2. **Install from source**:
|
||||
```bash
|
||||
git clone https://github.com/huggingface/lerobot.git
|
||||
cd lerobot
|
||||
pip install -e ".[libero,smolvla]"
|
||||
```
|
||||
|
||||
### Single-suite evaluation
|
||||
|
||||
Evaluate a policy on one LIBERO suite:
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/eval.py \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=libero \
|
||||
--env.task=libero_object \
|
||||
--env.multitask_eval=False \
|
||||
--eval.batch_size=2 \
|
||||
--eval.n_episodes=3
|
||||
```
|
||||
|
||||
- `--env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
|
||||
- `--eval.batch_size` controls how many environments run in parallel.
|
||||
- `--eval.n_episodes` sets how many episodes to run in total.
|
||||
|
||||
---
|
||||
|
||||
### Multi-suite evaluation
|
||||
|
||||
Benchmark a policy across multiple suites at once:
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/eval.py \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=libero \
|
||||
--env.task=libero_object \
|
||||
--env.multitask_eval=True \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=2
|
||||
```
|
||||
|
||||
- Pass a comma-separated list to `--env.task` for multi-suite evaluation.
|
||||
- Set `-env.multitask_eval=True` to enable evaluation across all tasks in those suites.
|
||||
|
||||
### Policy inputs and outputs
|
||||
|
||||
When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
|
||||
|
||||
- **Observations**
|
||||
- `observation.state` – proprioceptive features (agent state).
|
||||
- `observation.images.image` – main camera view (`agentview_image`).
|
||||
- `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
|
||||
|
||||
⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any visual features. Make sure your dataset metadata keys match this convention when evaluating.
|
||||
|
||||
## Input Features and Metadata Alignment
|
||||
|
||||
To train or evaluate a policy, you use `make_policy`, which builds a feature-naming dictionary for the observations the policy expects.
|
||||
This mapping can come from:
|
||||
- Dataset metadata
|
||||
- The evaluation environment
|
||||
- The policy path (if a pretrained repo ID is provided)
|
||||
|
||||
### Common Issues
|
||||
|
||||
A common problem is when the keys in the dataset, environment, and policy config do not match. For example:
|
||||
- `wrist_image` vs `observation.images.image2`
|
||||
- `observation.image2` (as in SmolVLA) vs the `.images.*` prefix convention
|
||||
|
||||
Such mismatches will cause `KeyError`s. This may be due to assumptions in `make_policy` or missing error handling.
|
||||
|
||||
***
|
||||
|
||||
### How to Check Expected Features
|
||||
- Open your policy config (`config.json`), e.g. [example here](https://huggingface.co/jadechoghari/smolvla-libero/blob/main/config.json).
|
||||
- Or add a breakpoint in `train.py` and inspect:
|
||||
|
||||
````python
|
||||
print(policy.config.input_features)
|
||||
To ensure you can just check what your policy expects as `input_features`:
|
||||
|
||||
- Open your policy config (`config.json`), e.g. [example here](https://huggingface.co/jadechoghari/smolvla-libero/blob/main/config.json).
|
||||
- Or add a breakpoint in `train.py` and inspect:
|
||||
```python
|
||||
print(policy.config.input_features)
|
||||
Fixing KeyErrors (Preprocessing Example)
|
||||
````
|
||||
|
||||
## Fixing KeyErrors (Preprocessing Example)
|
||||
|
||||
If your dataset columns do not follow the expected naming, you can rename them in-place before training:
|
||||
|
||||
````python
|
||||
import pyarrow.parquet as pq
|
||||
import shutil
|
||||
|
||||
def rename_columns(parquet_path, rename_map):
|
||||
table = pq.read_table(parquet_path)
|
||||
schema = table.schema
|
||||
new_names = [rename_map.get(name, name) for name in schema.names]
|
||||
renamed_table = table.rename_columns(new_names)
|
||||
backup_path = parquet_path + ".bak"
|
||||
shutil.copy(parquet_path, backup_path)
|
||||
pq.write_table(renamed_table, parquet_path)
|
||||
print(f"patched {parquet_path}, backup at {backup_path}")
|
||||
|
||||
# example mapping: align dataset keys to LeRobot convention
|
||||
rename_map = {
|
||||
"image": "observation.images.image",
|
||||
"wrist_image": "observation.images.image2",
|
||||
}
|
||||
|
||||
rename_columns("episode_000001.parquet", rename_map)
|
||||
|
||||
|
||||
|
||||
- **Actions**
|
||||
- Continuous control values in a `Box(-1, 1, shape=(7,))` space.
|
||||
|
||||
We also provide a notebook for quick testing:
|
||||
Training with LIBERO
|
||||
|
||||
## Training with LIBERO
|
||||
|
||||
When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
|
||||
|
||||
The environment expects:
|
||||
|
||||
- `observation.state` → 8-dim agent state
|
||||
- `observation.images.image` → main camera (`agentview_image`)
|
||||
- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
|
||||
|
||||
⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code. We plan to provide a script to easily preprocess such data.
|
||||
To avoid potential mismatches and `KeyError`s, we provide a **preprocessed LIBERO dataset** that is fully compatible with the current LeRobot codebase and requires no additional manipulations.
|
||||
|
||||
- 🔗 [Preprocessed LIBERO dataset (Hugging Face LeRobot org)](https://huggingface.co/datasets/HuggingFaceVLA/libero)
|
||||
- 🔗 [Original LIBERO dataset (physical-intelligence)](https://huggingface.co/datasets/physical-intelligence/libero)
|
||||
|
||||
The preprocessed dataset follows LeRobot naming conventions (e.g., `.images.*` prefix for visual features) and aligns with policy configs out-of-the-box.
|
||||
The original dataset is acknowledged here as the primary source.
|
||||
---
|
||||
|
||||
### Example training command
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/train.py \
|
||||
--policy.type=smolvla \
|
||||
--policy.repo_id=${HF_USER}/libero-test \
|
||||
--dataset.repo_id=jadechoghari/smol-libero3 \
|
||||
--env.type=libero \
|
||||
--env.task=libero_10 \
|
||||
--output_dir=./outputs/ \
|
||||
--steps=100000 \
|
||||
--batch_size=4 \
|
||||
--env.multitask_eval=True \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=1 \
|
||||
--eval_freq=1000 \
|
||||
````
|
||||
|
||||
---
|
||||
|
||||
### Note on rendering
|
||||
|
||||
LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
|
||||
|
||||
- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
|
||||
|
||||
---
|
||||
|
||||
## Colab Note on Parallel Evaluation
|
||||
|
||||
When running evaluation on Colab, you may encounter warnings such as:
|
||||
|
||||
```
|
||||
UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
|
||||
```
|
||||
|
||||
This happens because Colab’s rendering contexts are **not thread-safe**, and `ThreadPoolExecutor(max_workers=num_workers)` can trigger segfaults or leaked semaphore warnings.
|
||||
|
||||
**Colab Note:**
|
||||
Parallel evaluation is not supported in Colab. To avoid these issues, run sequentially or disable multitask evaluation:
|
||||
|
||||
Run sequentially:
|
||||
|
||||
```bash
|
||||
--env.max_parallel_tasks=1
|
||||
```
|
||||
|
||||
Or disable multitask evaluation:
|
||||
|
||||
```bash
|
||||
--env.multitask_eval=False
|
||||
```
|
||||
|
||||
If you want to take advantage of **parallel evaluation**, we recommend **not using Colab**. Instead, run locally or on a proper compute environment where multi-threaded rendering is easily supported.
|
||||
@@ -0,0 +1,58 @@
|
||||
#!/bin/bash
|
||||
|
||||
# storage / caches
|
||||
RAID=/raid/jade
|
||||
export TRANSFORMERS_CACHE=$RAID/.cache/huggingface/transformers
|
||||
export HF_HOME=$RAID/.cache/huggingface
|
||||
export HF_DATASETS_CACHE=$RAID/.cache/huggingface/datasets
|
||||
export HF_LEROBOT_HOME=$RAID/.cache/huggingface/lerobot
|
||||
export WANDB_CACHE_DIR=$RAID/.cache/wandb
|
||||
export TMPDIR=$RAID/.cache/tmp
|
||||
mkdir -p $TMPDIR
|
||||
export WANDB_MODE=offline
|
||||
export HF_DATASETS_OFFLINE=1
|
||||
export HF_HUB_OFFLINE=1
|
||||
export TOKENIZERS_PARALLELISM=false
|
||||
export MUJOCO_GL=egl
|
||||
export CUDA_VISIBLE_DEVICES=2
|
||||
|
||||
# CONFIGURATION
|
||||
POLICY_PATH="/raid/jade/logs/lerobot/lerobot_2_HuggingFaceVLA_libero_smolvla_lr1e-4bs32steps100000/checkpoints/100000/pretrained_model"
|
||||
POLICY_PATH="/raid/jade/models/smolvlamust"
|
||||
TASK=libero_spatial,libero_object
|
||||
ENV_TYPE="libero"
|
||||
BATCH_SIZE=1
|
||||
N_EPISODES=1
|
||||
# storage / caches
|
||||
RAID=/raid/jade
|
||||
N_ACTION_STEPS=1
|
||||
export TRANSFORMERS_CACHE=$RAID/.cache/huggingface/transformers
|
||||
export HF_HOME=$RAID/.cache/huggingface
|
||||
export HF_DATASETS_CACHE=$RAID/.cache/huggingface/datasets
|
||||
export HF_LEROBOT_HOME=$RAID/.cache/huggingface/lerobot
|
||||
export WANDB_CACHE_DIR=$RAID/.cache/wandb
|
||||
export TMPDIR=$RAID/.cache/tmp
|
||||
mkdir -p $TMPDIR
|
||||
export WANDB_MODE=offline
|
||||
# export HF_DATASETS_OFFLINE=1
|
||||
# export HF_HUB_OFFLINE=1
|
||||
export TOKENIZERS_PARALLELISM=false
|
||||
export MUJOCO_GL=egl
|
||||
export MUJOCO_GL=egl
|
||||
unset HF_HUB_OFFLINE
|
||||
# RUN EVALUATION
|
||||
python src/lerobot/scripts/eval.py \
|
||||
--policy.path="$POLICY_PATH" \
|
||||
--env.type="$ENV_TYPE" \
|
||||
--eval.batch_size="$BATCH_SIZE" \
|
||||
--eval.n_episodes="$N_EPISODES" \
|
||||
--env.multitask_eval=True \
|
||||
--env.task=$TASK \
|
||||
# python examples/evaluate_libero.py \
|
||||
# --policy_path "$POLICY_PATH" \
|
||||
# --task_suite_name "$TASK" \
|
||||
# --num_steps_wait 10 \
|
||||
# --num_trials_per_task 10 \
|
||||
# --video_out_path "data/libero/videos" \
|
||||
# --device "cuda" \
|
||||
# --seed 7
|
||||
@@ -0,0 +1,193 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
"""Script to create and push a PI0OpenPI model to HuggingFace hub with proper config format."""
|
||||
|
||||
import tempfile
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from huggingface_hub import HfApi, create_repo
|
||||
|
||||
from lerobot.policies.pi0_openpi import PI0OpenPIConfig, PI0OpenPIPolicy
|
||||
|
||||
|
||||
def create_and_push_model(
|
||||
repo_id: str,
|
||||
private: bool = False,
|
||||
token: str = None,
|
||||
):
|
||||
"""Create a PI0OpenPI model with proper config and push to HuggingFace hub.
|
||||
|
||||
Args:
|
||||
repo_id: HuggingFace repository ID (e.g., "username/model-name")
|
||||
private: Whether to create a private repository
|
||||
token: HuggingFace API token (optional, will use cached token if not provided)
|
||||
"""
|
||||
print("=" * 60)
|
||||
print("PI0OpenPI Model Hub Upload")
|
||||
print("=" * 60)
|
||||
|
||||
# Create configuration
|
||||
print("\nCreating PI0OpenPI configuration...")
|
||||
config = PI0OpenPIConfig(
|
||||
# Model architecture
|
||||
paligemma_variant="gemma_2b",
|
||||
action_expert_variant="gemma_300m",
|
||||
pi05=False, # Use PI0 (not PI0.5)
|
||||
dtype="float32", # Use float32 for compatibility
|
||||
# Input/output dimensions
|
||||
action_dim=32, # see openpi `Pi0Config`
|
||||
state_dim=32,
|
||||
chunk_size=50,
|
||||
n_action_steps=50,
|
||||
# Image inputs, see openpi `model.py, IMAGE_KEYS`
|
||||
image_keys=(
|
||||
"observation.images.base_0_rgb",
|
||||
"observation.images.left_wrist_0_rgb",
|
||||
"observation.images.right_wrist_0_rgb",
|
||||
),
|
||||
# Training settings
|
||||
gradient_checkpointing=False,
|
||||
compile_model=False,
|
||||
device=None, # Auto-detect
|
||||
# Tokenizer settings
|
||||
tokenizer_max_length=48, # see openpi `__post_init__`, use pi0=48 and pi05=200
|
||||
)
|
||||
|
||||
print(f" - Config type: {config.__class__.__name__}")
|
||||
print(f" - PaliGemma variant: {config.paligemma_variant}")
|
||||
print(f" - Action expert variant: {config.action_expert_variant}")
|
||||
print(f" - Action dim: {config.action_dim}")
|
||||
print(f" - State dim: {config.state_dim}")
|
||||
|
||||
# Create dummy dataset stats for normalization
|
||||
print("\nCreating dataset statistics...")
|
||||
dataset_stats = {
|
||||
"observation.state": {
|
||||
"mean": torch.zeros(config.state_dim),
|
||||
"std": torch.ones(config.state_dim),
|
||||
"min": torch.full((config.state_dim,), -5.0),
|
||||
"max": torch.full((config.state_dim,), 5.0),
|
||||
},
|
||||
"action": {
|
||||
"mean": torch.zeros(config.action_dim),
|
||||
"std": torch.ones(config.action_dim),
|
||||
"min": torch.full((config.action_dim,), -1.0),
|
||||
"max": torch.full((config.action_dim,), 1.0),
|
||||
},
|
||||
}
|
||||
|
||||
# Add image stats
|
||||
for key in config.image_keys:
|
||||
dataset_stats[key] = {
|
||||
"mean": torch.tensor([0.485, 0.456, 0.406]), # TODO(pepijn): fix this, now its ImageNet mean
|
||||
"std": torch.tensor([0.229, 0.224, 0.225]), # TODO(pepijn): fix this, now its ImageNet std
|
||||
"min": torch.tensor([0.0, 0.0, 0.0]),
|
||||
"max": torch.tensor([1.0, 1.0, 1.0]),
|
||||
}
|
||||
|
||||
# Create the policy
|
||||
print("\nInitializing PI0OpenPI policy...")
|
||||
print(" (This may take a moment as it loads the tokenizer and initializes the model)")
|
||||
policy = PI0OpenPIPolicy(config, dataset_stats)
|
||||
|
||||
# Initialize with small random weights (optional - for testing)
|
||||
# Note: In practice, you would load your trained weights here
|
||||
print("\nInitializing model weights...")
|
||||
for name, param in policy.named_parameters():
|
||||
if "weight" in name:
|
||||
if "norm" in name.lower() or "layernorm" in name.lower():
|
||||
torch.nn.init.ones_(param)
|
||||
elif len(param.shape) >= 2:
|
||||
torch.nn.init.xavier_uniform_(param, gain=0.01)
|
||||
else:
|
||||
torch.nn.init.normal_(param, mean=0.0, std=0.01)
|
||||
elif "bias" in name:
|
||||
torch.nn.init.zeros_(param)
|
||||
|
||||
print(f" - Total parameters: {sum(p.numel() for p in policy.parameters()):,}")
|
||||
print(f" - Trainable parameters: {sum(p.numel() for p in policy.parameters() if p.requires_grad):,}")
|
||||
|
||||
# Create temporary directory for saving
|
||||
with tempfile.TemporaryDirectory() as tmpdir:
|
||||
save_path = Path(tmpdir) / "model"
|
||||
save_path.mkdir(exist_ok=True)
|
||||
|
||||
print(f"\nSaving model to temporary directory: {save_path}")
|
||||
|
||||
# Save the model using LeRobot's save_pretrained method
|
||||
# This ensures the config is saved in the correct format
|
||||
policy.save_pretrained(save_path)
|
||||
|
||||
# List saved files
|
||||
saved_files = list(save_path.glob("*"))
|
||||
print("\nSaved files:")
|
||||
for file in saved_files:
|
||||
size = file.stat().st_size
|
||||
print(f" - {file.name}: {size:,} bytes")
|
||||
|
||||
# Create or get repository
|
||||
print(f"\nCreating/accessing repository: {repo_id}")
|
||||
api = HfApi(token=token)
|
||||
|
||||
try:
|
||||
# Create repo if it doesn't exist
|
||||
create_repo(
|
||||
repo_id,
|
||||
private=private,
|
||||
token=token,
|
||||
exist_ok=True,
|
||||
)
|
||||
print(f" ✓ Repository ready: https://huggingface.co/{repo_id}")
|
||||
except Exception as e:
|
||||
print(f" ⚠️ Note: {e}")
|
||||
|
||||
# Upload to hub
|
||||
print("\nUploading to HuggingFace hub...")
|
||||
api.upload_folder(
|
||||
folder_path=str(save_path),
|
||||
repo_id=repo_id,
|
||||
repo_type="model",
|
||||
token=token,
|
||||
commit_message="Upload PI0OpenPI model with proper LeRobot config format",
|
||||
)
|
||||
|
||||
print(f"\n✓ Model successfully uploaded to: https://huggingface.co/{repo_id}")
|
||||
|
||||
print("\n" + "=" * 60)
|
||||
print("✓ Process complete!")
|
||||
print("=" * 60)
|
||||
|
||||
return policy
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import argparse
|
||||
|
||||
parser = argparse.ArgumentParser(description="Push PI0OpenPI model to HuggingFace hub")
|
||||
parser.add_argument(
|
||||
"--repo-id",
|
||||
type=str,
|
||||
default="test-user/pi0-openpi-test",
|
||||
help="HuggingFace repository ID (e.g., 'username/model-name')",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--private",
|
||||
action="store_true",
|
||||
help="Create a private repository",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--token",
|
||||
type=str,
|
||||
default=None,
|
||||
help="HuggingFace API token (optional, uses cached token if not provided)",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
# Run the upload
|
||||
create_and_push_model(
|
||||
repo_id=args.repo_id,
|
||||
private=args.private,
|
||||
token=args.token,
|
||||
)
|
||||
+26
-6
@@ -29,7 +29,7 @@ version = "0.3.4"
|
||||
description = "🤗 LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch"
|
||||
readme = "README.md"
|
||||
license = { text = "Apache-2.0" }
|
||||
requires-python = ">=3.10"
|
||||
requires-python = ">=3.11"
|
||||
authors = [
|
||||
{ name = "Rémi Cadène", email = "re.cadene@gmail.com" },
|
||||
{ name = "Simon Alibert", email = "alibert.sim@gmail.com" },
|
||||
@@ -50,7 +50,7 @@ classifiers = [
|
||||
"Intended Audience :: Education",
|
||||
"Intended Audience :: Science/Research",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
"Programming Language :: Python :: 3.10",
|
||||
"Programming Language :: Python :: 3.11",
|
||||
"Topic :: Software Development :: Build Tools",
|
||||
"Topic :: Scientific/Engineering :: Artificial Intelligence",
|
||||
]
|
||||
@@ -95,7 +95,7 @@ dependencies = [
|
||||
# Common
|
||||
pygame-dep = ["pygame>=2.5.1"]
|
||||
placo-dep = ["placo>=0.9.6"]
|
||||
transformers-dep = ["transformers>=4.50.3,<4.52.0"] # TODO: Bumb dependency
|
||||
transformers-dep = ["transformers==4.53.2"]
|
||||
grpcio-dep = ["grpcio==1.73.1", "protobuf==6.31.0"]
|
||||
|
||||
# Motors
|
||||
@@ -135,7 +135,26 @@ video_benchmark = ["scikit-image>=0.23.2", "pandas>=2.2.2"]
|
||||
aloha = ["gym-aloha>=0.1.1"]
|
||||
pusht = ["gym-pusht>=0.1.5", "pymunk>=6.6.0,<7.0.0"] # TODO: Fix pymunk version in gym-pusht instead
|
||||
xarm = ["gym-xarm>=0.1.1"]
|
||||
|
||||
libero = [
|
||||
"hydra-core>=1.2,<1.4",
|
||||
"numpy",
|
||||
"wandb",
|
||||
"easydict",
|
||||
"transformers",
|
||||
"opencv-python",
|
||||
"robomimic==0.2.0",
|
||||
"einops",
|
||||
"thop",
|
||||
"robosuite==1.4.0",
|
||||
"mujoco>=2.3.7,<3.0.0",
|
||||
"bddl==1.0.1",
|
||||
"matplotlib",
|
||||
"cloudpickle",
|
||||
"future",
|
||||
"gym",
|
||||
"egl_probe @ git+https://github.com/jadechoghari/egl_probe.git#egg=egl_probe",
|
||||
"libero @ git+https://github.com/jadechoghari/LIBERO.git@main#egg=libero",
|
||||
]
|
||||
# All
|
||||
all = [
|
||||
"lerobot[dynamixel]",
|
||||
@@ -154,7 +173,8 @@ all = [
|
||||
"lerobot[video_benchmark]",
|
||||
"lerobot[aloha]",
|
||||
"lerobot[pusht]",
|
||||
"lerobot[xarm]"
|
||||
"lerobot[xarm]",
|
||||
"lerobot[libero]"
|
||||
]
|
||||
|
||||
[project.scripts]
|
||||
@@ -260,7 +280,7 @@ default.extend-ignore-identifiers-re = [
|
||||
# paths = ["src/lerobot"]
|
||||
|
||||
# [tool.mypy]
|
||||
# python_version = "3.10"
|
||||
# python_version = "3.11"
|
||||
# warn_return_any = true
|
||||
# warn_unused_configs = true
|
||||
# ignore_missing_imports = false
|
||||
|
||||
@@ -72,9 +72,11 @@ class PreTrainedConfig(draccus.ChoiceRegistry, HubMixin, abc.ABC):
|
||||
tags: list[str] | None = None
|
||||
# Add tags to your policy on the hub.
|
||||
license: str | None = None
|
||||
# Either the repo ID of a model hosted on the Hub or a path to a directory containing weights
|
||||
# saved using `Policy.save_pretrained`. If not provided, the policy is initialized from scratch.
|
||||
pretrained_path: str | None = None
|
||||
|
||||
def __post_init__(self):
|
||||
self.pretrained_path = None
|
||||
if not self.device or not is_torch_device_available(self.device):
|
||||
auto_device = auto_select_torch_device()
|
||||
logging.warning(f"Device '{self.device}' is not available. Switching to '{auto_device}'.")
|
||||
|
||||
@@ -30,6 +30,8 @@ class EnvConfig(draccus.ChoiceRegistry, abc.ABC):
|
||||
fps: int = 30
|
||||
features: dict[str, PolicyFeature] = field(default_factory=dict)
|
||||
features_map: dict[str, str] = field(default_factory=dict)
|
||||
multitask_eval: bool = False
|
||||
max_parallel_tasks: int = 5
|
||||
|
||||
@property
|
||||
def type(self) -> str:
|
||||
@@ -271,3 +273,53 @@ class HILEnvConfig(EnvConfig):
|
||||
"use_gamepad": self.use_gamepad,
|
||||
"gripper_penalty": self.gripper_penalty,
|
||||
}
|
||||
|
||||
|
||||
@EnvConfig.register_subclass("libero")
|
||||
@dataclass
|
||||
class LiberoEnv(EnvConfig):
|
||||
task: str = "libero_10" # can also choose libero_spatial, libero_object, etc.
|
||||
fps: int = 30
|
||||
episode_length: int = 520
|
||||
obs_type: str = "pixels_agent_pos"
|
||||
render_mode: str = "rgb_array"
|
||||
camera_name: str = "agentview_image,robot0_eye_in_hand_image"
|
||||
init_states: bool = True
|
||||
multitask_eval: bool = True
|
||||
features: dict[str, PolicyFeature] = field(
|
||||
default_factory=lambda: {
|
||||
"action": PolicyFeature(type=FeatureType.ACTION, shape=(7,)),
|
||||
}
|
||||
)
|
||||
features_map: dict[str, str] = field(
|
||||
default_factory=lambda: {
|
||||
"action": ACTION,
|
||||
"agent_pos": OBS_STATE,
|
||||
"pixels/agentview_image": f"{OBS_IMAGES}.image",
|
||||
"pixels/robot0_eye_in_hand_image": f"{OBS_IMAGES}.image2",
|
||||
}
|
||||
)
|
||||
|
||||
def __post_init__(self):
|
||||
if self.obs_type == "pixels":
|
||||
self.features["pixels/agentview_image"] = PolicyFeature(
|
||||
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||
)
|
||||
self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
|
||||
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||
)
|
||||
elif self.obs_type == "pixels_agent_pos":
|
||||
self.features["agent_pos"] = PolicyFeature(type=FeatureType.STATE, shape=(8,))
|
||||
self.features["pixels/agentview_image"] = PolicyFeature(
|
||||
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||
)
|
||||
self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
|
||||
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||
)
|
||||
|
||||
@property
|
||||
def gym_kwargs(self) -> dict:
|
||||
return {
|
||||
"obs_type": self.obs_type,
|
||||
"render_mode": self.render_mode,
|
||||
}
|
||||
|
||||
+35
-12
@@ -17,7 +17,7 @@ import importlib
|
||||
|
||||
import gymnasium as gym
|
||||
|
||||
from lerobot.envs.configs import AlohaEnv, EnvConfig, HILEnvConfig, PushtEnv, XarmEnv
|
||||
from lerobot.envs.configs import AlohaEnv, EnvConfig, HILEnvConfig, LiberoEnv, PushtEnv, XarmEnv
|
||||
|
||||
|
||||
def make_env_config(env_type: str, **kwargs) -> EnvConfig:
|
||||
@@ -29,11 +29,15 @@ def make_env_config(env_type: str, **kwargs) -> EnvConfig:
|
||||
return XarmEnv(**kwargs)
|
||||
elif env_type == "hil":
|
||||
return HILEnvConfig(**kwargs)
|
||||
elif env_type == "libero":
|
||||
return LiberoEnv(**kwargs)
|
||||
else:
|
||||
raise ValueError(f"Policy type '{env_type}' is not available.")
|
||||
|
||||
|
||||
def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> gym.vector.VectorEnv | None:
|
||||
def make_env(
|
||||
cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False
|
||||
) -> gym.vector.VectorEnv | dict[str, dict[int, gym.vector.VectorEnv]]:
|
||||
"""Makes a gym vector environment according to the config.
|
||||
|
||||
Args:
|
||||
@@ -48,24 +52,43 @@ def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> g
|
||||
|
||||
Returns:
|
||||
gym.vector.VectorEnv: The parallelized gym.env instance.
|
||||
dict[str, dict[int, gym.vector.VectorEnv]]: A mapping from task suite
|
||||
names to indexed vectorized environments (when multitask eval is used).
|
||||
|
||||
"""
|
||||
if n_envs < 1:
|
||||
raise ValueError("`n_envs must be at least 1")
|
||||
raise ValueError("`n_envs` must be at least 1")
|
||||
|
||||
env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
|
||||
|
||||
if "libero" in cfg.type:
|
||||
from lerobot.envs.libero import create_libero_envs
|
||||
|
||||
return create_libero_envs(
|
||||
task=cfg.task,
|
||||
n_envs=n_envs,
|
||||
camera_name=cfg.camera_name,
|
||||
init_states=cfg.init_states,
|
||||
gym_kwargs=cfg.gym_kwargs,
|
||||
env_cls=env_cls,
|
||||
multitask_eval=cfg.multitask_eval,
|
||||
)
|
||||
|
||||
package_name = f"gym_{cfg.type}"
|
||||
|
||||
try:
|
||||
importlib.import_module(package_name)
|
||||
except ModuleNotFoundError as e:
|
||||
print(f"{package_name} is not installed. Please install it with `pip install 'lerobot[{cfg.type}]'`")
|
||||
raise e
|
||||
raise ModuleNotFoundError(
|
||||
f'{package_name} is not installed. Install with: pip install "lerobot[{cfg.type}]"'
|
||||
) from e
|
||||
|
||||
gym_handle = f"{package_name}/{cfg.task}"
|
||||
|
||||
# batched version of the env that returns an observation of shape (b, c)
|
||||
env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
|
||||
env = env_cls(
|
||||
[lambda: gym.make(gym_handle, disable_env_checker=True, **cfg.gym_kwargs) for _ in range(n_envs)]
|
||||
)
|
||||
def _make_one():
|
||||
return gym.make(gym_handle, disable_env_checker=True, **(cfg.gym_kwargs or {}))
|
||||
|
||||
return env
|
||||
vec = env_cls([_make_one for _ in range(n_envs)])
|
||||
|
||||
# normalize to {suite: {task_id: vec_env}} for consistency
|
||||
suite_name = cfg.type # e.g., "pusht", "aloha"
|
||||
return {suite_name: {0: vec}}
|
||||
|
||||
@@ -0,0 +1,497 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
from collections import defaultdict
|
||||
from collections.abc import Callable, Iterable, Mapping, Sequence
|
||||
from itertools import chain
|
||||
from typing import Any
|
||||
|
||||
import gymnasium as gym
|
||||
import numpy as np
|
||||
import torch
|
||||
from gymnasium import spaces
|
||||
from libero.libero import benchmark, get_libero_path
|
||||
from libero.libero.envs import OffScreenRenderEnv
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# ---- Helpers -----------------------------------------------------------------
|
||||
|
||||
|
||||
def _parse_camera_names(camera_name: str | Sequence[str]) -> list[str]:
|
||||
"""Normalize camera_name into a non-empty list of strings."""
|
||||
if isinstance(camera_name, str):
|
||||
cams = [c.strip() for c in camera_name.split(",") if c.strip()]
|
||||
elif isinstance(camera_name, (list, tuple)):
|
||||
cams = [str(c).strip() for c in camera_name if str(c).strip()]
|
||||
else:
|
||||
raise TypeError(f"camera_name must be str or sequence[str], got {type(camera_name).__name__}")
|
||||
if not cams:
|
||||
raise ValueError("camera_name resolved to an empty list.")
|
||||
return cams
|
||||
|
||||
|
||||
def _get_suite(name: str):
|
||||
"""Instantiate a LIBERO suite by name with clear validation."""
|
||||
bench = benchmark.get_benchmark_dict()
|
||||
if name not in bench:
|
||||
raise ValueError(f"Unknown LIBERO suite '{name}'. Available: {', '.join(sorted(bench.keys()))}")
|
||||
suite = bench[name]()
|
||||
if not getattr(suite, "tasks", None):
|
||||
raise ValueError(f"Suite '{name}' has no tasks.")
|
||||
return suite
|
||||
|
||||
|
||||
def _select_task_ids(total_tasks: int, task_ids: Iterable[int] | None) -> list[int]:
|
||||
"""Validate/normalize task ids. If None → all tasks."""
|
||||
if task_ids is None:
|
||||
return list(range(total_tasks))
|
||||
ids = sorted({int(t) for t in task_ids})
|
||||
for t in ids:
|
||||
if t < 0 or t >= total_tasks:
|
||||
raise ValueError(f"task_id {t} out of range [0, {total_tasks - 1}].")
|
||||
return ids
|
||||
|
||||
|
||||
def _make_env_fns(
|
||||
*,
|
||||
suite,
|
||||
suite_name: str,
|
||||
task_id: int,
|
||||
n_envs: int,
|
||||
camera_names: list[str],
|
||||
init_states: bool,
|
||||
gym_kwargs: Mapping[str, Any],
|
||||
LiberoEnv: type, # injected to avoid forward ref issues if needed
|
||||
) -> list[Callable[[], LiberoEnv]]:
|
||||
"""Build n_envs factory callables for a single (suite, task_id)."""
|
||||
joined_cams = ",".join(camera_names) # keep backward-compat: downstream expects a string
|
||||
fns: list[Callable[[], LiberoEnv]] = []
|
||||
for i in range(n_envs):
|
||||
|
||||
def _mk(
|
||||
i=i,
|
||||
suite=suite,
|
||||
task_id=task_id,
|
||||
suite_name=suite_name,
|
||||
joined_cams=joined_cams,
|
||||
init_states=init_states,
|
||||
gym_kwargs=dict(gym_kwargs),
|
||||
):
|
||||
return LiberoEnv(
|
||||
task_suite=suite,
|
||||
task_id=task_id,
|
||||
task_suite_name=suite_name,
|
||||
camera_name=joined_cams,
|
||||
init_states=init_states,
|
||||
episode_index=i,
|
||||
**gym_kwargs,
|
||||
)
|
||||
|
||||
fns.append(_mk)
|
||||
return fns
|
||||
|
||||
|
||||
# ---- Main API ----------------------------------------------------------------
|
||||
|
||||
|
||||
def create_libero_envs(
|
||||
task: str,
|
||||
n_envs: int,
|
||||
gym_kwargs: dict[str, Any] | None = None,
|
||||
camera_name: str | Sequence[str] = "agentview_image,robot0_eye_in_hand_image",
|
||||
init_states: bool = True,
|
||||
env_cls: Callable[[Sequence[Callable[[], Any]]], Any] | None = None,
|
||||
multitask_eval: bool = True, # kept for signature compatibility; return type is consistent regardless
|
||||
) -> dict[str, dict[int, Any]]:
|
||||
"""
|
||||
Create vectorized LIBERO environments with a consistent return shape.
|
||||
|
||||
Returns:
|
||||
dict[suite_name][task_id] -> vec_env (env_cls([...]) with exactly n_envs factories)
|
||||
Notes:
|
||||
- n_envs is the number of rollouts *per task* (episode_index = 0..n_envs-1).
|
||||
- `task` can be a single suite or a comma-separated list of suites.
|
||||
- You may pass `task_ids` (list[int]) inside `gym_kwargs` to restrict tasks per suite.
|
||||
"""
|
||||
if env_cls is None or not callable(env_cls):
|
||||
raise ValueError("env_cls must be a callable that wraps a list of environment factory callables.")
|
||||
if not isinstance(n_envs, int) or n_envs <= 0:
|
||||
raise ValueError(f"n_envs must be a positive int; got {n_envs}.")
|
||||
|
||||
gym_kwargs = dict(gym_kwargs or {})
|
||||
task_ids_filter = gym_kwargs.pop("task_ids", None) # optional: limit to specific tasks
|
||||
|
||||
# Avoid circular import/type issues: assume LiberoEnv is defined in this module
|
||||
try:
|
||||
LiberoEnv # type: ignore[name-defined]
|
||||
except NameError:
|
||||
# If LiberoEnv is in the same file, this won't run. If it's elsewhere, import here.
|
||||
exit()
|
||||
# from .libero_env import LiberoEnv # adjust if your class lives in another module
|
||||
|
||||
camera_names = _parse_camera_names(camera_name)
|
||||
suite_names = [s.strip() for s in str(task).split(",") if s.strip()]
|
||||
if not suite_names:
|
||||
raise ValueError("`task` must contain at least one LIBERO suite name.")
|
||||
|
||||
logger.info(
|
||||
"Creating LIBERO envs | suites=%s | n_envs(per task)=%d | init_states=%s | multitask_eval=%s",
|
||||
suite_names,
|
||||
n_envs,
|
||||
init_states,
|
||||
bool(multitask_eval),
|
||||
)
|
||||
if task_ids_filter is not None:
|
||||
logger.info("Restricting to task_ids=%s", task_ids_filter)
|
||||
|
||||
out: dict[str, dict[int, Any]] = defaultdict(dict)
|
||||
|
||||
for suite_name in suite_names:
|
||||
suite = _get_suite(suite_name)
|
||||
total = len(suite.tasks)
|
||||
selected = _select_task_ids(total, task_ids_filter)
|
||||
|
||||
if not selected:
|
||||
raise ValueError(f"No tasks selected for suite '{suite_name}' (available: {total}).")
|
||||
|
||||
for tid in selected:
|
||||
fns = _make_env_fns(
|
||||
suite=suite,
|
||||
suite_name=suite_name,
|
||||
task_id=tid,
|
||||
n_envs=n_envs,
|
||||
camera_names=camera_names,
|
||||
init_states=init_states,
|
||||
gym_kwargs=gym_kwargs,
|
||||
LiberoEnv=LiberoEnv,
|
||||
)
|
||||
out[suite_name][tid] = env_cls(fns)
|
||||
logger.debug("Built vec env | suite=%s | task_id=%d | n_envs=%d", suite_name, tid, n_envs)
|
||||
|
||||
# return plain dicts for predictability
|
||||
return {suite: dict(task_map) for suite, task_map in out.items()}
|
||||
|
||||
|
||||
def quat2axisangle(quat):
|
||||
"""
|
||||
Copied from robosuite: https://github.com/ARISE-Initiative/robosuite/blob/eafb81f54ffc104f905ee48a16bb15f059176ad3/robosuite/utils/transform_utils.py#L490C1-L512C55
|
||||
|
||||
Converts quaternion to axis-angle format.
|
||||
Returns a unit vector direction scaled by its angle in radians.
|
||||
|
||||
Args:
|
||||
quat (np.array): (x,y,z,w) vec4 float angles
|
||||
|
||||
Returns:
|
||||
np.array: (ax,ay,az) axis-angle exponential coordinates
|
||||
"""
|
||||
# clip quaternion
|
||||
if quat[3] > 1.0:
|
||||
quat[3] = 1.0
|
||||
elif quat[3] < -1.0:
|
||||
quat[3] = -1.0
|
||||
|
||||
den = np.sqrt(1.0 - quat[3] * quat[3])
|
||||
if math.isclose(den, 0.0):
|
||||
# This is (close to) a zero degree rotation, immediately return
|
||||
return np.zeros(3)
|
||||
|
||||
return (quat[:3] * 2.0 * math.acos(quat[3])) / den
|
||||
|
||||
|
||||
def get_task_init_states(task_suite, i):
|
||||
init_states_path = os.path.join(
|
||||
get_libero_path("init_states"),
|
||||
task_suite.tasks[i].problem_folder,
|
||||
task_suite.tasks[i].init_states_file,
|
||||
)
|
||||
init_states = torch.load(init_states_path, weights_only=False) # nosec B614
|
||||
return init_states
|
||||
|
||||
|
||||
def get_libero_dummy_action():
|
||||
"""Get dummy/no-op action, used to roll out the simulation while the robot does nothing."""
|
||||
return [0, 0, 0, 0, 0, 0, -1]
|
||||
|
||||
|
||||
OBS_STATE_DIM = 8
|
||||
ACTION_DIM = 7
|
||||
|
||||
|
||||
class LiberoEnv(gym.Env):
|
||||
metadata = {"render_modes": ["rgb_array"], "render_fps": 80}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
task_suite,
|
||||
task_id,
|
||||
task_suite_name,
|
||||
camera_name="agentview_image,robot0_eye_in_hand_image",
|
||||
obs_type="pixels",
|
||||
render_mode="rgb_array",
|
||||
observation_width=256,
|
||||
observation_height=256,
|
||||
visualization_width=640,
|
||||
visualization_height=480,
|
||||
init_states=True,
|
||||
episode_index=0,
|
||||
):
|
||||
super().__init__()
|
||||
self.task_id = task_id
|
||||
self.obs_type = obs_type
|
||||
self.render_mode = render_mode
|
||||
self.observation_width = observation_width
|
||||
self.observation_height = observation_height
|
||||
self.visualization_width = visualization_width
|
||||
self.visualization_height = visualization_height
|
||||
self.init_states = init_states
|
||||
self.camera_name = camera_name.split(
|
||||
","
|
||||
) # agentview_image (main) or robot0_eye_in_hand_image (wrist)
|
||||
|
||||
# Map raw camera names to "image1" and "image2".
|
||||
# The preprocessing step `preprocess_observation` will then prefix these with `.images.*`,
|
||||
# following the LeRobot convention (e.g., `observation.images.image`, `observation.images.image2`).
|
||||
# This ensures the policy consistently receives observations in the
|
||||
# expected format regardless of the original camera naming.
|
||||
self.camera_name_mapping = {
|
||||
"agentview_image": "image",
|
||||
"robot0_eye_in_hand_image": "image2",
|
||||
}
|
||||
|
||||
self.num_steps_wait = (
|
||||
10 # Do nothing for the first few timesteps to wait for the simulator drops objects
|
||||
)
|
||||
self.episode_index = episode_index
|
||||
|
||||
self._env = self._make_envs_task(task_suite, self.task_id)
|
||||
TASK_SUITE_MAX_STEPS: dict[str, int] = {
|
||||
"libero_spatial": 220, # longest training demo has 193 steps
|
||||
"libero_object": 280, # longest training demo has 254 steps
|
||||
"libero_goal": 300, # longest training demo has 270 steps
|
||||
"libero_10": 520, # longest training demo has 505 steps
|
||||
"libero_90": 400, # longest training demo has 373 steps
|
||||
}
|
||||
default_steps = 500
|
||||
self._max_episode_steps = TASK_SUITE_MAX_STEPS.get(task_suite_name, default_steps)
|
||||
|
||||
images = {}
|
||||
for cam in self.camera_name:
|
||||
images[self.camera_name_mapping[cam]] = spaces.Box(
|
||||
low=0,
|
||||
high=255,
|
||||
shape=(self.observation_height, self.observation_width, 3),
|
||||
dtype=np.uint8,
|
||||
)
|
||||
|
||||
if self.obs_type == "state":
|
||||
raise NotImplementedError(
|
||||
"The 'state' observation type is not supported in LiberoEnv. "
|
||||
"Please switch to an image-based obs_type (e.g. 'pixels', 'pixels_agent_pos')."
|
||||
)
|
||||
|
||||
elif self.obs_type == "pixels":
|
||||
self.observation_space = spaces.Dict(
|
||||
{
|
||||
"pixels": spaces.Dict(images),
|
||||
}
|
||||
)
|
||||
elif self.obs_type == "pixels_agent_pos":
|
||||
self.observation_space = spaces.Dict(
|
||||
{
|
||||
"pixels": spaces.Dict(images),
|
||||
"agent_pos": spaces.Box(
|
||||
low=-1000.0,
|
||||
high=1000.0,
|
||||
shape=(OBS_STATE_DIM,),
|
||||
dtype=np.float64,
|
||||
),
|
||||
}
|
||||
)
|
||||
|
||||
self.action_space = spaces.Box(low=-1, high=1, shape=(ACTION_DIM,), dtype=np.float32)
|
||||
|
||||
def render(self):
|
||||
raw_obs = self._env.env._get_observations()
|
||||
image = self._format_raw_obs(raw_obs)["pixels"]["image"]
|
||||
return image
|
||||
|
||||
def _make_envs_task(self, task_suite, task_id: int = 0):
|
||||
task = task_suite.get_task(task_id)
|
||||
self.task = task.name
|
||||
self.task_description = task.language
|
||||
task_bddl_file = os.path.join(get_libero_path("bddl_files"), task.problem_folder, task.bddl_file)
|
||||
|
||||
env_args = {
|
||||
"bddl_file_name": task_bddl_file,
|
||||
"camera_heights": self.observation_height,
|
||||
"camera_widths": self.observation_width,
|
||||
}
|
||||
env = OffScreenRenderEnv(**env_args)
|
||||
env.reset()
|
||||
if self.init_states:
|
||||
init_states = get_task_init_states(
|
||||
task_suite, task_id
|
||||
) # for benchmarking purpose, we fix the a set of initial states FIXME(mshukor): should be in the reset()?
|
||||
init_state_id = self.episode_index # episode index
|
||||
env.set_init_state(init_states[init_state_id])
|
||||
|
||||
return env
|
||||
|
||||
def _format_raw_obs(self, raw_obs):
|
||||
images = {}
|
||||
for camera_name in self.camera_name:
|
||||
image = raw_obs[camera_name]
|
||||
image = image[::-1, ::-1] # rotate 180 degrees
|
||||
images[self.camera_name_mapping[camera_name]] = image
|
||||
state = np.concatenate(
|
||||
(
|
||||
raw_obs["robot0_eef_pos"],
|
||||
quat2axisangle(raw_obs["robot0_eef_quat"]),
|
||||
raw_obs["robot0_gripper_qpos"],
|
||||
)
|
||||
)
|
||||
agent_pos = state
|
||||
if self.obs_type == "state":
|
||||
raise NotImplementedError(
|
||||
"The 'state' observation type is not supported in LiberoEnv. "
|
||||
"Please switch to an image-based obs_type (e.g. 'pixels', 'pixels_agent_pos')."
|
||||
)
|
||||
elif self.obs_type == "pixels":
|
||||
obs = {"pixels": images.copy()}
|
||||
elif self.obs_type == "pixels_agent_pos":
|
||||
obs = {
|
||||
"pixels": images.copy(),
|
||||
"agent_pos": agent_pos,
|
||||
}
|
||||
return obs
|
||||
|
||||
def reset(self, seed=None, **kwargs):
|
||||
super().reset(seed=seed)
|
||||
|
||||
self._env.seed(seed)
|
||||
raw_obs = self._env.reset()
|
||||
# Do nothing for the first few timesteps to wait for the simulator drops objects
|
||||
for _ in range(self.num_steps_wait):
|
||||
raw_obs, _, _, _ = self._env.step(get_libero_dummy_action())
|
||||
observation = self._format_raw_obs(raw_obs)
|
||||
info = {"is_success": False}
|
||||
return observation, info
|
||||
|
||||
def step(self, action):
|
||||
if action.ndim != 1:
|
||||
raise ValueError(
|
||||
f"Expected action to be 1-D (shape (action_dim,)), "
|
||||
f"but got shape {action.shape} with ndim={action.ndim}"
|
||||
)
|
||||
raw_obs, reward, done, info = self._env.step(action)
|
||||
|
||||
is_success = self._env.check_success()
|
||||
terminated = done or is_success
|
||||
info["is_success"] = done # is_success
|
||||
|
||||
observation = self._format_raw_obs(raw_obs)
|
||||
if done:
|
||||
self.reset()
|
||||
print(self.task, self.task_id, done, is_success)
|
||||
truncated = False
|
||||
return observation, reward, terminated, truncated, info
|
||||
|
||||
def close(self):
|
||||
self._env.close()
|
||||
|
||||
|
||||
def create_libero_envs1(
|
||||
task: str,
|
||||
n_envs: int,
|
||||
gym_kwargs: dict[str, Any] = None,
|
||||
camera_name: str = "agentview_image,robot0_eye_in_hand_image",
|
||||
init_states: bool = True,
|
||||
env_cls: Callable = None,
|
||||
multitask_eval: bool = True,
|
||||
) -> dict[str, dict[str, Any]]:
|
||||
"""
|
||||
Here n_envs is per task and equal to the number of rollouts.
|
||||
Returns:
|
||||
dict[str, dict[str, list[LiberoEnv]]]: keys are task_suite and values are list of LiberoEnv envs.
|
||||
"""
|
||||
print("num envs", n_envs)
|
||||
print("multitask_eval", multitask_eval)
|
||||
print("gym_kwargs", gym_kwargs)
|
||||
if gym_kwargs is None:
|
||||
gym_kwargs = {}
|
||||
|
||||
if not multitask_eval:
|
||||
benchmark_dict = benchmark.get_benchmark_dict()
|
||||
task_suite = benchmark_dict[task]() # can also choose libero_spatial, libero_object, libero_10 etc.
|
||||
tasks_id = list(range(len(task_suite.tasks)))
|
||||
episode_indices = [0 for i in range(len(tasks_id))]
|
||||
if len(tasks_id) == 1:
|
||||
tasks_id = [tasks_id[0] for _ in range(n_envs)]
|
||||
episode_indices = list(range(n_envs))
|
||||
elif len(tasks_id) < n_envs and n_envs % len(tasks_id) == 0:
|
||||
n_repeat = n_envs // len(tasks_id)
|
||||
print("n_repeat", n_repeat)
|
||||
episode_indices = []
|
||||
for _ in range(len(tasks_id)):
|
||||
episode_indices.extend(list(range(n_repeat)))
|
||||
tasks_id = list(chain.from_iterable([[item] * n_repeat for item in tasks_id]))
|
||||
elif n_envs < len(tasks_id):
|
||||
tasks_id = tasks_id[:n_envs]
|
||||
episode_indices = list(range(n_envs))[:n_envs]
|
||||
print(f"WARNING: n_envs < len(tasks_id), evaluating only on {tasks_id}")
|
||||
print(f"Creating Libero envs with task ids {tasks_id} from suite {task}")
|
||||
assert n_envs == len(tasks_id), (
|
||||
f"len(n_envs) and tasks_id should be the same, got {n_envs} and {len(tasks_id)}"
|
||||
)
|
||||
return env_cls(
|
||||
[
|
||||
lambda i=i: LiberoEnv(
|
||||
task_suite=task_suite,
|
||||
task_id=tasks_id[i],
|
||||
task_suite_name=task,
|
||||
camera_name=camera_name,
|
||||
init_states=init_states,
|
||||
episode_index=episode_indices[i],
|
||||
**gym_kwargs,
|
||||
)
|
||||
for i in range(n_envs)
|
||||
]
|
||||
)
|
||||
else:
|
||||
envs = defaultdict(dict)
|
||||
benchmark_dict = benchmark.get_benchmark_dict()
|
||||
task = task.split(",")
|
||||
for _task in task:
|
||||
task_suite = benchmark_dict[
|
||||
_task
|
||||
]() # can also choose libero_spatial, libero_object, libero_10 etc.
|
||||
tasks_ids = list(range(len(task_suite.tasks)))
|
||||
for tasks_id in tasks_ids:
|
||||
episode_indices = list(range(n_envs))
|
||||
print(
|
||||
f"Creating Libero envs with task ids {tasks_id} from suite {_task}, episode_indices: {episode_indices}"
|
||||
)
|
||||
envs_list = [
|
||||
(
|
||||
lambda i=i,
|
||||
task_suite=task_suite,
|
||||
tasks_id=tasks_id,
|
||||
_task=_task,
|
||||
episode_indices=episode_indices: LiberoEnv(
|
||||
task_suite=task_suite,
|
||||
task_id=tasks_id,
|
||||
task_suite_name=_task,
|
||||
camera_name=camera_name,
|
||||
init_states=init_states,
|
||||
episode_index=episode_indices[i],
|
||||
**gym_kwargs,
|
||||
)
|
||||
)
|
||||
for i in range(n_envs)
|
||||
]
|
||||
envs[_task][tasks_id] = env_cls(envs_list)
|
||||
return envs
|
||||
@@ -134,3 +134,49 @@ def add_envs_task(env: gym.vector.VectorEnv, observation: dict[str, Any]) -> dic
|
||||
num_envs = observation[list(observation.keys())[0]].shape[0]
|
||||
observation["task"] = ["" for _ in range(num_envs)]
|
||||
return observation
|
||||
|
||||
|
||||
def _close_single_env(env: Any) -> None:
|
||||
"""Try to close a single env object if it exposes .close()."""
|
||||
try:
|
||||
close_fn = getattr(env, "close", None)
|
||||
if callable(close_fn):
|
||||
close_fn()
|
||||
except Exception as exc:
|
||||
# Best-effort close: log but don't raise
|
||||
LOG.debug("Exception while closing env %s: %s", env, exc)
|
||||
|
||||
|
||||
def close_envs(env_or_collection: Any) -> None:
|
||||
"""
|
||||
Close a single env or any nested structure of envs.
|
||||
|
||||
Accepts:
|
||||
- a single env with .close()
|
||||
- a Mapping of things (e.g. dict)
|
||||
- a Sequence of things (list/tuple) but NOT str/bytes
|
||||
- nested combinations of the above
|
||||
|
||||
This is intentionally permissive and best-effort: it will swallow exceptions
|
||||
encountered while closing individual envs and continue.
|
||||
"""
|
||||
# Guard: single object with close()
|
||||
if hasattr(env_or_collection, "close") and not isinstance(env_or_collection, (Mapping, Sequence)):
|
||||
_close_single_env(env_or_collection)
|
||||
return
|
||||
|
||||
# Mapping (e.g., {suite: {task_id: vec_env}})
|
||||
if isinstance(env_or_collection, Mapping):
|
||||
for v in env_or_collection.values():
|
||||
close_envs(v)
|
||||
return
|
||||
|
||||
# Sequence (list/tuple) but skip str/bytes
|
||||
if isinstance(env_or_collection, Sequence) and not isinstance(env_or_collection, (str, bytes)):
|
||||
for v in env_or_collection:
|
||||
close_envs(v)
|
||||
return
|
||||
|
||||
# Fallback: try to close if possible
|
||||
if hasattr(env_or_collection, "close"):
|
||||
_close_single_env(env_or_collection)
|
||||
|
||||
@@ -27,7 +27,9 @@ from lerobot.envs.utils import env_to_policy_features
|
||||
from lerobot.policies.act.configuration_act import ACTConfig
|
||||
from lerobot.policies.diffusion.configuration_diffusion import DiffusionConfig
|
||||
from lerobot.policies.pi0.configuration_pi0 import PI0Config
|
||||
from lerobot.policies.pi0_openpi.configuration_pi0openpi import PI0OpenPIConfig
|
||||
from lerobot.policies.pi0fast.configuration_pi0fast import PI0FASTConfig
|
||||
from lerobot.policies.pi05_openpi.configuration_pi05openpi import PI05OpenPIConfig
|
||||
from lerobot.policies.pretrained import PreTrainedPolicy
|
||||
from lerobot.policies.sac.configuration_sac import SACConfig
|
||||
from lerobot.policies.sac.reward_model.configuration_classifier import RewardClassifierConfig
|
||||
@@ -62,6 +64,14 @@ def get_policy_class(name: str) -> PreTrainedPolicy:
|
||||
from lerobot.policies.pi0fast.modeling_pi0fast import PI0FASTPolicy
|
||||
|
||||
return PI0FASTPolicy
|
||||
elif name == "pi0_openpi":
|
||||
from lerobot.policies.pi0_openpi.modeling_pi0openpi import PI0OpenPIPolicy
|
||||
|
||||
return PI0OpenPIPolicy
|
||||
elif name == "pi05_openpi":
|
||||
from lerobot.policies.pi05_openpi.modeling_pi05openpi import PI05OpenPIPolicy
|
||||
|
||||
return PI05OpenPIPolicy
|
||||
elif name == "sac":
|
||||
from lerobot.policies.sac.modeling_sac import SACPolicy
|
||||
|
||||
@@ -91,6 +101,10 @@ def make_policy_config(policy_type: str, **kwargs) -> PreTrainedConfig:
|
||||
return PI0Config(**kwargs)
|
||||
elif policy_type == "pi0fast":
|
||||
return PI0FASTConfig(**kwargs)
|
||||
elif policy_type == "pi0_openpi":
|
||||
return PI0OpenPIConfig(**kwargs)
|
||||
elif policy_type == "pi05_openpi":
|
||||
return PI05OpenPIConfig(**kwargs)
|
||||
elif policy_type == "sac":
|
||||
return SACConfig(**kwargs)
|
||||
elif policy_type == "smolvla":
|
||||
@@ -172,7 +186,5 @@ def make_policy(
|
||||
|
||||
policy.to(cfg.device)
|
||||
assert isinstance(policy, nn.Module)
|
||||
|
||||
# policy = torch.compile(policy, mode="reduce-overhead")
|
||||
|
||||
return policy
|
||||
|
||||
@@ -0,0 +1,92 @@
|
||||
# π₀.₅ (pi05)
|
||||
|
||||
This repository contains the Hugging Face port of **π₀.₅**, adapted from [OpenPI](https://github.com/Physical-Intelligence/openpi) by the Physical Intelligence.
|
||||
It is designed as a **Vision-Language-Action model with open-world generalization**.
|
||||
|
||||
---
|
||||
|
||||
### ⚠️ WARNING ⚠️
|
||||
|
||||
This project requires **patching the Hugging Face `transformers` library**.
|
||||
|
||||
1. Make sure you have the exact version installed:
|
||||
|
||||
```bash
|
||||
pip show transformers
|
||||
```
|
||||
|
||||
It must be version **4.53.2**.
|
||||
|
||||
2. Apply the custom patches by copying the modified files into your environment:
|
||||
|
||||
```bash
|
||||
cp -r ./src/lerobot/policies/pi0_openpi/transformers_replace/* \
|
||||
$(python -c "import transformers, os; print(os.path.dirname(transformers.__file__))")
|
||||
```
|
||||
|
||||
These patches overwrite parts of `transformers` to:
|
||||
- Support the **AdaRMS optimizer**,
|
||||
- Correctly control the precision of activations,
|
||||
- Allow the KV cache to be used without updates.
|
||||
|
||||
**Important:**
|
||||
|
||||
- This permanently modifies your `transformers` installation.
|
||||
- The changes survive reinstalls unless you explicitly remove the patched files or recreate the environment.
|
||||
|
||||
To undo and restore a clean state:
|
||||
|
||||
```bash
|
||||
pip uninstall transformers
|
||||
pip install transformers==4.53.2
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Model Overview
|
||||
|
||||
| Feature | π₀ | π₀.₅ |
|
||||
| -------------------- | ------------------------------------------------------ | ----------------------------------------- |
|
||||
| State Embedding | Uses `state_proj` layer | No state embedding |
|
||||
| Time Conditioning | Concatenates time with actions via `action_time_mlp_*` | Uses `time_mlp_*` for AdaRMS conditioning |
|
||||
| AdaRMS | Not used | Used in action expert |
|
||||
| Tokenizer Length | 48 tokens | 200 tokens |
|
||||
| Discrete State Input | False | True |
|
||||
| Parameter Count | Higher (includes state embedding) | Lower (no state embedding) |
|
||||
|
||||
---
|
||||
|
||||
## Citation
|
||||
|
||||
If you use this work, please cite both **OpenPI** and the π₀.₅ paper:
|
||||
|
||||
```bibtex
|
||||
@misc{openpi2024,
|
||||
author = {Physical Intelligence Lab},
|
||||
title = {OpenPI: PyTorch Implementation of π0 and π0.5 Policies},
|
||||
year = {2024},
|
||||
publisher = {GitHub},
|
||||
howpublished = {\url{https://github.com/Physical-Intelligence/openpi}},
|
||||
license = {Apache-2.0}
|
||||
}
|
||||
|
||||
@misc{intelligence2025pi05visionlanguageactionmodelopenworld,
|
||||
title = {π₀.₅: a Vision-Language-Action Model with Open-World Generalization},
|
||||
author = {Physical Intelligence and Kevin Black and Noah Brown and James Darpinian and Karan Dhabalia and Danny Driess and Adnan Esmail and Michael Equi and Chelsea Finn and Niccolo Fusai and Manuel Y. Galliker and Dibya Ghosh and Lachy Groom and Karol Hausman and Brian Ichter and Szymon Jakubczak and Tim Jones and Liyiming Ke and Devin LeBlanc and Sergey Levine and Adrian Li-Bell and Mohith Mothukuri and Suraj Nair and Karl Pertsch and Allen Z. Ren and Lucy Xiaoyang Shi and Laura Smith and Jost Tobias Springenberg and Kyle Stachowicz and James Tanner and Quan Vuong and Homer Walke and Anna Walling and Haohuan Wang and Lili Yu and Ury Zhilinsky},
|
||||
year = {2025},
|
||||
eprint = {2504.16054},
|
||||
archivePrefix= {arXiv},
|
||||
primaryClass = {cs.LG},
|
||||
url = {https://arxiv.org/abs/2504.16054},
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## License
|
||||
|
||||
This port follows the **Apache 2.0 License**, consistent with the original [OpenPI repository](https://github.com/Physical-Intelligence/openpi).
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
@@ -0,0 +1,20 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
# Copyright 2025 Physical Intelligence and The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from .configuration_pi05openpi import PI05OpenPIConfig
|
||||
from .modeling_pi05openpi import PI05OpenPIPolicy
|
||||
|
||||
__all__ = ["PI05OpenPIConfig", "PI05OpenPIPolicy"]
|
||||
@@ -0,0 +1,137 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
# Copyright 2025 Physical Intelligence and The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from dataclasses import dataclass, field
|
||||
|
||||
from lerobot.configs.policies import PreTrainedConfig
|
||||
from lerobot.configs.types import NormalizationMode
|
||||
from lerobot.optim.optimizers import AdamWConfig
|
||||
from lerobot.optim.schedulers import CosineDecayWithWarmupSchedulerConfig
|
||||
|
||||
|
||||
@PreTrainedConfig.register_subclass("pi05_openpi")
|
||||
@dataclass
|
||||
class PI05OpenPIConfig(PreTrainedConfig):
|
||||
# Model architecture
|
||||
paligemma_variant: str = "gemma_2b"
|
||||
action_expert_variant: str = "gemma_300m"
|
||||
discrete_state_input: bool | None = (
|
||||
True # Whether to use discrete state input # see openpi `Pi0Config, __post_init__`
|
||||
)
|
||||
dtype: str = "float32" # Options: "bfloat16", "float32"
|
||||
|
||||
# Input / output structure
|
||||
n_obs_steps: int = 1
|
||||
chunk_size: int = 50 # Number of action steps to predict, in openpi called "action_horizon"
|
||||
n_action_steps: int = 50 # Number of action steps to execute
|
||||
|
||||
# Shorter state and action vectors will be padded to these dimensions
|
||||
max_state_dim: int = 32 # State dimension (will be padded to 32)
|
||||
max_action_dim: int = 32 # Action dimension (will be padded to 32)
|
||||
|
||||
# Flow matching parameters: see openpi `PI0Pytorch`
|
||||
num_inference_steps: int = 10 # Number of denoising steps during inference
|
||||
time_sampling_beta_alpha: float = 1.5 # Beta distribution alpha parameter for time sampling
|
||||
time_sampling_beta_beta: float = 1.0 # Beta distribution beta parameter for time sampling
|
||||
min_period: float = 4e-3 # Min period for sinusoidal positional encoding
|
||||
max_period: float = 4.0 # Max period for sinusoidal positional encoding
|
||||
|
||||
# Image preprocessing
|
||||
image_resolution: tuple[int, int] = (224, 224) # see openpi `preprocessing_pytorch.py`
|
||||
|
||||
# Normalization
|
||||
normalization_mapping: dict[str, NormalizationMode] = field(
|
||||
default_factory=lambda: {
|
||||
"VISUAL": NormalizationMode.IDENTITY, # Images are normalized to [-1, 1] in preprocessing
|
||||
"STATE": NormalizationMode.MEAN_STD,
|
||||
"ACTION": NormalizationMode.MEAN_STD,
|
||||
}
|
||||
)
|
||||
|
||||
# Training settings
|
||||
gradient_checkpointing: bool = False # Enable gradient checkpointing for memory optimization
|
||||
compile_model: bool = False # Whether to use torch.compile for model optimization
|
||||
compile_mode: str = "max-autotune" # Torch compile mode
|
||||
device: str | None = None # Device to use for the model (None = auto-detect)
|
||||
|
||||
# Optimizer settings: see openpi `AdamW` and
|
||||
optimizer_lr: float = 2.5e-5 # see openpi `CosineDecaySchedule: peak_lr`
|
||||
optimizer_betas: tuple[float, float] = (0.9, 0.95)
|
||||
optimizer_eps: float = 1e-8
|
||||
optimizer_weight_decay: float = 0.01
|
||||
optimizer_grad_clip_norm: float = 1.0
|
||||
|
||||
# Scheduler settings: see openpi `CosineDecaySchedule`
|
||||
scheduler_warmup_steps: int = 1_000
|
||||
scheduler_decay_steps: int = 30_000
|
||||
scheduler_decay_lr: float = 2.5e-6
|
||||
|
||||
tokenizer_max_length: int = 200 # see openpi `__post_init__`
|
||||
|
||||
def __post_init__(self):
|
||||
super().__post_init__()
|
||||
|
||||
# Validate configuration
|
||||
if self.n_action_steps > self.chunk_size:
|
||||
raise ValueError(
|
||||
f"n_action_steps ({self.n_action_steps}) cannot be greater than chunk_size ({self.chunk_size})"
|
||||
)
|
||||
|
||||
if self.paligemma_variant not in ["gemma_300m", "gemma_2b"]:
|
||||
raise ValueError(f"Invalid paligemma_variant: {self.paligemma_variant}")
|
||||
|
||||
if self.action_expert_variant not in ["gemma_300m", "gemma_2b"]:
|
||||
raise ValueError(f"Invalid action_expert_variant: {self.action_expert_variant}")
|
||||
|
||||
if self.dtype not in ["bfloat16", "float32"]:
|
||||
raise ValueError(f"Invalid dtype: {self.dtype}")
|
||||
|
||||
def validate_features(self) -> None:
|
||||
"""Validate and set up input/output features."""
|
||||
# Image features are now handled dynamically through dataset configuration
|
||||
# No need to auto-add hardcoded image keys
|
||||
|
||||
# State and action features are also handled dynamically through dataset configuration
|
||||
# The actual dimensions come from the feature shapes, max dimensions are used for padding only
|
||||
pass
|
||||
|
||||
def get_optimizer_preset(self) -> AdamWConfig:
|
||||
return AdamWConfig(
|
||||
lr=self.optimizer_lr,
|
||||
betas=self.optimizer_betas,
|
||||
eps=self.optimizer_eps,
|
||||
weight_decay=self.optimizer_weight_decay,
|
||||
grad_clip_norm=self.optimizer_grad_clip_norm,
|
||||
)
|
||||
|
||||
def get_scheduler_preset(self):
|
||||
return CosineDecayWithWarmupSchedulerConfig(
|
||||
peak_lr=self.optimizer_lr,
|
||||
decay_lr=self.scheduler_decay_lr,
|
||||
num_warmup_steps=self.scheduler_warmup_steps,
|
||||
num_decay_steps=self.scheduler_decay_steps,
|
||||
)
|
||||
|
||||
@property
|
||||
def observation_delta_indices(self) -> None:
|
||||
return None
|
||||
|
||||
@property
|
||||
def action_delta_indices(self) -> list:
|
||||
return list(range(self.chunk_size))
|
||||
|
||||
@property
|
||||
def reward_delta_indices(self) -> None:
|
||||
return None
|
||||
File diff suppressed because it is too large
Load Diff
+173
@@ -0,0 +1,173 @@
|
||||
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
|
||||
# This file was automatically generated from src/transformers/models/gemma/modular_gemma.py.
|
||||
# Do NOT edit this file manually as any edits will be overwritten by the generation of
|
||||
# the file from the modular. If any change should be done, please apply the change to the
|
||||
# modular_gemma.py file directly. One of our CI enforces this.
|
||||
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
|
||||
# coding=utf-8
|
||||
# Copyright 2024 Google Inc. HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from ...configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class GemmaConfig(PretrainedConfig):
|
||||
r"""
|
||||
This is the configuration class to store the configuration of a [`GemmaModel`]. It is used to instantiate an Gemma
|
||||
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
|
||||
defaults will yield a similar configuration to that of the Gemma-7B.
|
||||
e.g. [google/gemma-7b](https://huggingface.co/google/gemma-7b)
|
||||
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||
documentation from [`PretrainedConfig`] for more information.
|
||||
Args:
|
||||
vocab_size (`int`, *optional*, defaults to 256000):
|
||||
Vocabulary size of the Gemma model. Defines the number of different tokens that can be represented by the
|
||||
`inputs_ids` passed when calling [`GemmaModel`]
|
||||
hidden_size (`int`, *optional*, defaults to 3072):
|
||||
Dimension of the hidden representations.
|
||||
intermediate_size (`int`, *optional*, defaults to 24576):
|
||||
Dimension of the MLP representations.
|
||||
num_hidden_layers (`int`, *optional*, defaults to 28):
|
||||
Number of hidden layers in the Transformer decoder.
|
||||
num_attention_heads (`int`, *optional*, defaults to 16):
|
||||
Number of attention heads for each attention layer in the Transformer decoder.
|
||||
num_key_value_heads (`int`, *optional*, defaults to 16):
|
||||
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
||||
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
||||
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
||||
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
||||
by meanpooling all the original heads within that group. For more details, check out [this
|
||||
paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
|
||||
`num_attention_heads`.
|
||||
head_dim (`int`, *optional*, defaults to 256):
|
||||
The attention head dimension.
|
||||
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
|
||||
The legacy activation function. It is overwritten by the `hidden_activation`.
|
||||
hidden_activation (`str` or `function`, *optional*):
|
||||
The non-linear activation function (function or string) in the decoder. Will default to `"gelu_pytorch_tanh"`
|
||||
if not specified. `"gelu_pytorch_tanh"` uses an approximation of the `"gelu"` activation function.
|
||||
max_position_embeddings (`int`, *optional*, defaults to 8192):
|
||||
The maximum sequence length that this model might ever be used with.
|
||||
initializer_range (`float`, *optional*, defaults to 0.02):
|
||||
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
||||
The epsilon used by the rms normalization layers.
|
||||
use_cache (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
||||
relevant if `config.is_decoder=True`.
|
||||
pad_token_id (`int`, *optional*, defaults to 0):
|
||||
Padding token id.
|
||||
eos_token_id (`int`, *optional*, defaults to 1):
|
||||
End of stream token id.
|
||||
bos_token_id (`int`, *optional*, defaults to 2):
|
||||
Beginning of stream token id.
|
||||
tie_word_embeddings (`bool`, *optional*, defaults to `True`):
|
||||
Whether to tie weight embeddings
|
||||
rope_theta (`float`, *optional*, defaults to 10000.0):
|
||||
The base period of the RoPE embeddings.
|
||||
attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
|
||||
Whether to use a bias in the query, key, value and output projection layers during self-attention.
|
||||
attention_dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout ratio for the attention probabilities.
|
||||
use_adarms (`bool`, *optional*, defaults to `False`):
|
||||
Whether to use ADARMS.
|
||||
adarms_cond_dim (`int`, *optional*, defaults to `None`):
|
||||
The dimension of the ADARMS condition.
|
||||
```python
|
||||
>>> from transformers import GemmaModel, GemmaConfig
|
||||
>>> # Initializing a Gemma gemma-7b style configuration
|
||||
>>> configuration = GemmaConfig()
|
||||
>>> # Initializing a model from the gemma-7b style configuration
|
||||
>>> model = GemmaModel(configuration)
|
||||
>>> # Accessing the model configuration
|
||||
>>> configuration = model.config
|
||||
```"""
|
||||
|
||||
model_type = "gemma"
|
||||
keys_to_ignore_at_inference = ["past_key_values"]
|
||||
base_model_tp_plan = {
|
||||
"layers.*.self_attn.q_proj": "colwise",
|
||||
"layers.*.self_attn.k_proj": "colwise",
|
||||
"layers.*.self_attn.v_proj": "colwise",
|
||||
"layers.*.self_attn.o_proj": "rowwise",
|
||||
"layers.*.mlp.gate_proj": "colwise",
|
||||
"layers.*.mlp.up_proj": "colwise",
|
||||
"layers.*.mlp.down_proj": "rowwise",
|
||||
}
|
||||
base_model_pp_plan = {
|
||||
"embed_tokens": (["input_ids"], ["inputs_embeds"]),
|
||||
"layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
|
||||
"norm": (["hidden_states"], ["hidden_states"]),
|
||||
}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size=256000,
|
||||
hidden_size=3072,
|
||||
intermediate_size=24576,
|
||||
num_hidden_layers=28,
|
||||
num_attention_heads=16,
|
||||
num_key_value_heads=16,
|
||||
head_dim=256,
|
||||
hidden_act="gelu_pytorch_tanh",
|
||||
hidden_activation=None,
|
||||
max_position_embeddings=8192,
|
||||
initializer_range=0.02,
|
||||
rms_norm_eps=1e-6,
|
||||
use_cache=True,
|
||||
pad_token_id=0,
|
||||
eos_token_id=1,
|
||||
bos_token_id=2,
|
||||
tie_word_embeddings=True,
|
||||
rope_theta=10000.0,
|
||||
attention_bias=False,
|
||||
attention_dropout=0.0,
|
||||
use_adarms: bool = False,
|
||||
adarms_cond_dim: int | None = None,
|
||||
**kwargs,
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.head_dim = head_dim
|
||||
self.num_key_value_heads = num_key_value_heads
|
||||
self.hidden_act = hidden_act
|
||||
self.hidden_activation = hidden_activation
|
||||
self.initializer_range = initializer_range
|
||||
self.rms_norm_eps = rms_norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.rope_theta = rope_theta
|
||||
self.attention_bias = attention_bias
|
||||
self.attention_dropout = attention_dropout
|
||||
self.use_adarms = use_adarms
|
||||
self.adarms_cond_dim = adarms_cond_dim
|
||||
|
||||
# Set default for adarms_cond_dim if use_adarms is True
|
||||
if self.use_adarms and self.adarms_cond_dim is None:
|
||||
self.adarms_cond_dim = self.hidden_size
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
__all__ = ["GemmaConfig"]
|
||||
@@ -0,0 +1,895 @@
|
||||
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
|
||||
# This file was automatically generated from src/transformers/models/gemma/modular_gemma.py.
|
||||
# Do NOT edit this file manually as any edits will be overwritten by the generation of
|
||||
# the file from the modular. If any change should be done, please apply the change to the
|
||||
# modular_gemma.py file directly. One of our CI enforces this.
|
||||
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
|
||||
# coding=utf-8
|
||||
# Copyright 2024 Google Inc. HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from collections.abc import Callable
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from ...activations import ACT2FN
|
||||
from ...cache_utils import Cache, DynamicCache
|
||||
from ...generation import GenerationMixin
|
||||
from ...masking_utils import create_causal_mask
|
||||
from ...modeling_flash_attention_utils import FlashAttentionKwargs
|
||||
from ...modeling_layers import GradientCheckpointingLayer
|
||||
from ...modeling_outputs import (
|
||||
BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast,
|
||||
SequenceClassifierOutputWithPast,
|
||||
TokenClassifierOutput,
|
||||
)
|
||||
from ...modeling_rope_utils import ROPE_INIT_FUNCTIONS, dynamic_rope_update
|
||||
from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
|
||||
from ...processing_utils import Unpack
|
||||
from ...utils import LossKwargs, auto_docstring, can_return_tuple, logging
|
||||
from .configuration_gemma import GemmaConfig
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
# Workaround for Python 3.10+ UnionType compatibility with transformers auto_docstring
|
||||
def safe_auto_docstring(func=None, **kwargs):
|
||||
"""Auto docstring decorator that handles Python 3.10+ UnionType gracefully."""
|
||||
|
||||
def decorator(f):
|
||||
try:
|
||||
return auto_docstring(f, **kwargs) if kwargs else auto_docstring(f)
|
||||
except (AttributeError, TypeError):
|
||||
# If auto_docstring fails due to UnionType, just return the function unchanged
|
||||
return f
|
||||
|
||||
if func is None:
|
||||
# Called with arguments, return the decorator
|
||||
return decorator
|
||||
else:
|
||||
# Called without arguments, apply directly
|
||||
return decorator(func)
|
||||
|
||||
|
||||
class GemmaRMSNorm(nn.Module):
|
||||
def __init__(self, dim: int, eps: float = 1e-6, cond_dim: int | None = None):
|
||||
super().__init__()
|
||||
self.eps = eps
|
||||
self.dim = dim
|
||||
self.cond_dim = cond_dim
|
||||
|
||||
# Dense layer for adaptive normalization (if cond_dim is provided)
|
||||
if cond_dim is not None:
|
||||
# self.dense = nn.Linear(cond_dim, dim * 3, bias=True, dtype=torch.bfloat16)
|
||||
self.dense = nn.Linear(cond_dim, dim * 3, bias=True)
|
||||
# Initialize with zeros (matches source implementation)
|
||||
nn.init.zeros_(self.dense.weight)
|
||||
else:
|
||||
self.weight = nn.Parameter(torch.zeros(dim, dtype=torch.bfloat16))
|
||||
self.dense = None
|
||||
|
||||
def _norm(self, x):
|
||||
# Compute variance in float32 (like the source implementation)
|
||||
var = torch.mean(torch.square(x.float()), dim=-1, keepdim=True)
|
||||
# Compute normalization in float32
|
||||
normed_inputs = x * torch.rsqrt(var + self.eps)
|
||||
return normed_inputs
|
||||
|
||||
def forward(self, x, cond=None):
|
||||
dtype = x.dtype # original dtype, could be half-precision
|
||||
normed_inputs = self._norm(x)
|
||||
|
||||
if cond is None or self.dense is None:
|
||||
# regular RMSNorm
|
||||
# scale by learned parameter in float32 (matches source implementation)
|
||||
normed_inputs = normed_inputs * (1.0 + self.weight.float())
|
||||
return normed_inputs.to(dtype), None # return in original dtype with None gate
|
||||
|
||||
# adaptive RMSNorm (if cond is provided and dense layer exists)
|
||||
if cond.shape[-1] != self.cond_dim:
|
||||
raise ValueError(f"Expected cond dimension {self.cond_dim}, got {cond.shape[-1]}")
|
||||
|
||||
# self.dense.to(dtype=torch.bfloat16).to(dtype=torch.float32)
|
||||
modulation = self.dense(cond)
|
||||
# Reshape modulation to broadcast properly: [batch, 1, features] for [batch, seq, features]
|
||||
if len(x.shape) == 3: # [batch, seq, features]
|
||||
modulation = modulation.unsqueeze(1)
|
||||
|
||||
scale, shift, gate = torch.chunk(modulation, 3, dim=-1)
|
||||
|
||||
# Apply adaptive normalization: use model weight dtype to ensure compatibility
|
||||
# model_dtype = self.dense.weight.dtype # Use the model's dtype (bfloat16)
|
||||
# scale = scale.to(model_dtype)
|
||||
# shift = shift.to(model_dtype)
|
||||
# gate = gate.to(model_dtype)
|
||||
# normed_inputs = normed_inputs.to(model_dtype) # Convert normed_inputs to model dtype
|
||||
|
||||
normed_inputs = normed_inputs * (1 + scale.to(torch.float32)) + shift.to(torch.float32)
|
||||
|
||||
return normed_inputs.to(dtype), gate.to(dtype)
|
||||
|
||||
def extra_repr(self):
|
||||
repr_str = f"{tuple(self.weight.shape)}, eps={self.eps}"
|
||||
if self.dense is not None:
|
||||
repr_str += f", adaptive=True, cond_dim={self.cond_dim}"
|
||||
return repr_str
|
||||
|
||||
|
||||
class GemmaMLP(nn.Module):
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.hidden_size = config.hidden_size
|
||||
self.intermediate_size = config.intermediate_size
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
||||
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[config.hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
|
||||
return down_proj
|
||||
|
||||
|
||||
class GemmaRotaryEmbedding(nn.Module):
|
||||
def __init__(self, config: GemmaConfig, device=None):
|
||||
super().__init__()
|
||||
# BC: "rope_type" was originally "type"
|
||||
if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
|
||||
self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
|
||||
else:
|
||||
self.rope_type = "default"
|
||||
self.max_seq_len_cached = config.max_position_embeddings
|
||||
self.original_max_seq_len = config.max_position_embeddings
|
||||
|
||||
self.config = config
|
||||
self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
|
||||
|
||||
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
|
||||
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
||||
self.original_inv_freq = self.inv_freq
|
||||
|
||||
@torch.no_grad()
|
||||
@dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
|
||||
def forward(self, x, position_ids):
|
||||
inv_freq_expanded = (
|
||||
self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
|
||||
)
|
||||
position_ids_expanded = position_ids[:, None, :].float()
|
||||
|
||||
device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
|
||||
with torch.autocast(device_type=device_type, enabled=False): # Force float32
|
||||
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
|
||||
emb = torch.cat((freqs, freqs), dim=-1)
|
||||
cos = emb.cos() * self.attention_scaling
|
||||
sin = emb.sin() * self.attention_scaling
|
||||
|
||||
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
|
||||
|
||||
|
||||
def rotate_half(x):
|
||||
"""Rotates half the hidden dims of the input."""
|
||||
x1 = x[..., : x.shape[-1] // 2]
|
||||
x2 = x[..., x.shape[-1] // 2 :]
|
||||
return torch.cat((-x2, x1), dim=-1)
|
||||
|
||||
|
||||
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
"""Applies Rotary Position Embedding to the query and key tensors.
|
||||
|
||||
Args:
|
||||
q (`torch.Tensor`): The query tensor.
|
||||
k (`torch.Tensor`): The key tensor.
|
||||
cos (`torch.Tensor`): The cosine part of the rotary embedding.
|
||||
sin (`torch.Tensor`): The sine part of the rotary embedding.
|
||||
position_ids (`torch.Tensor`, *optional*):
|
||||
Deprecated and unused.
|
||||
unsqueeze_dim (`int`, *optional*, defaults to 1):
|
||||
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
|
||||
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
|
||||
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
|
||||
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
|
||||
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
|
||||
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
|
||||
Returns:
|
||||
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
|
||||
"""
|
||||
cos = cos.unsqueeze(unsqueeze_dim)
|
||||
sin = sin.unsqueeze(unsqueeze_dim)
|
||||
q_embed = (q * cos) + (rotate_half(q) * sin)
|
||||
k_embed = (k * cos) + (rotate_half(k) * sin)
|
||||
return q_embed, k_embed
|
||||
|
||||
|
||||
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
||||
"""
|
||||
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
||||
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
||||
"""
|
||||
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
||||
if n_rep == 1:
|
||||
return hidden_states
|
||||
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
||||
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
||||
|
||||
|
||||
def _gated_residual(x, y, gate):
|
||||
"""
|
||||
Applies gated residual connection with optional gate parameter.
|
||||
|
||||
Args:
|
||||
x: Input tensor (residual)
|
||||
y: Output tensor to be added
|
||||
gate: Optional gate tensor to modulate the addition
|
||||
|
||||
Returns:
|
||||
x + y if gate is None, otherwise x + y * gate
|
||||
"""
|
||||
if x is None and y is None:
|
||||
return None
|
||||
if x is None or y is None:
|
||||
return x if x is not None else y
|
||||
if gate is None:
|
||||
return x + y
|
||||
return x + y * gate
|
||||
|
||||
|
||||
def eager_attention_forward(
|
||||
module: nn.Module,
|
||||
query: torch.Tensor,
|
||||
key: torch.Tensor,
|
||||
value: torch.Tensor,
|
||||
attention_mask: torch.Tensor | None,
|
||||
scaling: float,
|
||||
dropout: float = 0.0,
|
||||
**kwargs,
|
||||
):
|
||||
key_states = repeat_kv(key, module.num_key_value_groups)
|
||||
value_states = repeat_kv(value, module.num_key_value_groups)
|
||||
|
||||
attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
|
||||
if attention_mask is not None:
|
||||
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
|
||||
attn_weights = attn_weights + causal_mask
|
||||
|
||||
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
|
||||
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
|
||||
attn_output = torch.matmul(attn_weights, value_states)
|
||||
attn_output = attn_output.transpose(1, 2).contiguous()
|
||||
|
||||
return attn_output, attn_weights
|
||||
|
||||
|
||||
class GemmaAttention(nn.Module):
|
||||
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
||||
|
||||
def __init__(self, config: GemmaConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.layer_idx = layer_idx
|
||||
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
|
||||
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
|
||||
self.scaling = self.head_dim**-0.5
|
||||
self.attention_dropout = config.attention_dropout
|
||||
self.is_causal = True
|
||||
|
||||
self.q_proj = nn.Linear(
|
||||
config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
|
||||
)
|
||||
self.k_proj = nn.Linear(
|
||||
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
|
||||
)
|
||||
self.v_proj = nn.Linear(
|
||||
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
|
||||
)
|
||||
self.o_proj = nn.Linear(
|
||||
config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
position_embeddings: tuple[torch.Tensor, torch.Tensor],
|
||||
attention_mask: torch.Tensor | None,
|
||||
past_key_value: Cache | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
use_cache: bool = False,
|
||||
**kwargs: Unpack[FlashAttentionKwargs],
|
||||
) -> tuple[torch.Tensor, torch.Tensor | None, tuple[torch.Tensor] | None]:
|
||||
input_shape = hidden_states.shape[:-1]
|
||||
hidden_shape = (*input_shape, -1, self.head_dim)
|
||||
|
||||
query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
|
||||
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
|
||||
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
|
||||
|
||||
cos, sin = position_embeddings
|
||||
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
|
||||
|
||||
# Use cache if provided
|
||||
if past_key_value is not None:
|
||||
if use_cache:
|
||||
# sin and cos are specific to RoPE models; cache_position needed for the static cache
|
||||
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
|
||||
key_states, value_states = past_key_value.update(
|
||||
key_states, value_states, self.layer_idx, cache_kwargs
|
||||
)
|
||||
else:
|
||||
key_states = torch.cat([past_key_value[self.layer_idx][0], key_states], dim=2)
|
||||
value_states = torch.cat([past_key_value[self.layer_idx][1], value_states], dim=2)
|
||||
|
||||
attention_interface: Callable = eager_attention_forward
|
||||
if self.config._attn_implementation != "eager":
|
||||
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
|
||||
|
||||
attn_output, attn_weights = attention_interface(
|
||||
self,
|
||||
query_states,
|
||||
key_states,
|
||||
value_states,
|
||||
attention_mask,
|
||||
dropout=0.0 if not self.training else self.attention_dropout,
|
||||
scaling=self.scaling,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
|
||||
attn_output = self.o_proj(attn_output)
|
||||
return attn_output, attn_weights
|
||||
|
||||
|
||||
class GemmaDecoderLayer(GradientCheckpointingLayer):
|
||||
def __init__(self, config: GemmaConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.self_attn = GemmaAttention(config=config, layer_idx=layer_idx)
|
||||
|
||||
self.mlp = GemmaMLP(config)
|
||||
cond_dim = getattr(config, "adarms_cond_dim", None) if getattr(config, "use_adarms", False) else None
|
||||
self.input_layernorm = GemmaRMSNorm(config.hidden_size, eps=config.rms_norm_eps, cond_dim=cond_dim)
|
||||
self.post_attention_layernorm = GemmaRMSNorm(
|
||||
config.hidden_size, eps=config.rms_norm_eps, cond_dim=cond_dim
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_value: Cache | None = None,
|
||||
output_attentions: bool | None = False,
|
||||
use_cache: bool | None = False,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
position_embeddings: None
|
||||
| (tuple[torch.Tensor, torch.Tensor]) = None, # necessary, but kept here for BC
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
**kwargs: Unpack[FlashAttentionKwargs],
|
||||
) -> tuple[torch.FloatTensor, tuple[torch.FloatTensor, torch.FloatTensor] | None]:
|
||||
residual = hidden_states
|
||||
hidden_states, gate = self.input_layernorm(hidden_states, adarms_cond)
|
||||
|
||||
# Self Attention
|
||||
hidden_states, self_attn_weights = self.self_attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
cache_position=cache_position,
|
||||
position_embeddings=position_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
hidden_states = _gated_residual(residual, hidden_states, gate)
|
||||
|
||||
# Fully Connected
|
||||
residual = hidden_states
|
||||
hidden_states, gate = self.post_attention_layernorm(hidden_states, adarms_cond)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = _gated_residual(residual, hidden_states, gate)
|
||||
|
||||
outputs = (hidden_states,)
|
||||
if output_attentions:
|
||||
outputs += (self_attn_weights,)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class GemmaPreTrainedModel(PreTrainedModel):
|
||||
config_class = GemmaConfig
|
||||
base_model_prefix = "model"
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ["GemmaDecoderLayer"]
|
||||
_skip_keys_device_placement = ["past_key_values"]
|
||||
_supports_flash_attn_3 = True
|
||||
_supports_flash_attn_2 = True
|
||||
_supports_sdpa = True
|
||||
_supports_flex_attn = True
|
||||
_supports_cache_class = True
|
||||
_supports_quantized_cache = True
|
||||
_supports_static_cache = True
|
||||
_supports_attention_backend = True
|
||||
|
||||
def _init_weights(self, module):
|
||||
std = self.config.initializer_range
|
||||
if isinstance(module, nn.Linear):
|
||||
module.weight.data.normal_(mean=0.0, std=std)
|
||||
if module.bias is not None:
|
||||
module.bias.data.zero_()
|
||||
elif isinstance(module, nn.Embedding):
|
||||
module.weight.data.normal_(mean=0.0, std=std)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
elif isinstance(module, GemmaRMSNorm):
|
||||
if hasattr(module, "weight"):
|
||||
module.weight.data.fill_(1.0)
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class GemmaModel(GemmaPreTrainedModel):
|
||||
def __init__(self, config: GemmaConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList(
|
||||
[GemmaDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
||||
)
|
||||
|
||||
cond_dim = getattr(config, "adarms_cond_dim", None) if getattr(config, "use_adarms", False) else None
|
||||
self.norm = GemmaRMSNorm(config.hidden_size, eps=config.rms_norm_eps, cond_dim=cond_dim)
|
||||
self.rotary_emb = GemmaRotaryEmbedding(config=config)
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embed_tokens = value
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor | None = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: Cache | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
**kwargs: Unpack[FlashAttentionKwargs],
|
||||
) -> BaseModelOutputWithPast:
|
||||
"""
|
||||
adarms_cond (`torch.Tensor` of shape `(batch_size, cond_dim)`, *optional*):
|
||||
Condition for ADARMS.
|
||||
"""
|
||||
output_attentions = (
|
||||
output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
||||
|
||||
if (input_ids is None) ^ (inputs_embeds is not None):
|
||||
raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
|
||||
|
||||
if self.gradient_checkpointing and self.training and use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embed_tokens(input_ids)
|
||||
|
||||
if use_cache and past_key_values is None:
|
||||
past_key_values = DynamicCache()
|
||||
|
||||
if cache_position is None:
|
||||
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
|
||||
cache_position = torch.arange(
|
||||
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
|
||||
)
|
||||
|
||||
if position_ids is None:
|
||||
position_ids = cache_position.unsqueeze(0)
|
||||
|
||||
causal_mask = create_causal_mask(
|
||||
config=self.config,
|
||||
input_embeds=inputs_embeds,
|
||||
attention_mask=attention_mask,
|
||||
cache_position=cache_position,
|
||||
past_key_values=past_key_values,
|
||||
position_ids=position_ids,
|
||||
)
|
||||
|
||||
# embed positions
|
||||
hidden_states = inputs_embeds
|
||||
# Convert to bfloat16 if the first layer uses bfloat16
|
||||
if len(self.layers) > 0 and self.layers[0].self_attn.q_proj.weight.dtype == torch.bfloat16:
|
||||
hidden_states = hidden_states.to(torch.bfloat16)
|
||||
|
||||
# create position embeddings to be shared across the decoder layers
|
||||
position_embeddings = self.rotary_emb(hidden_states, position_ids)
|
||||
|
||||
# normalized
|
||||
# Gemma downcasts the below to float16, causing sqrt(3072)=55.4256 to become 55.5
|
||||
# See https://github.com/huggingface/transformers/pull/29402
|
||||
_normalizer = torch.tensor(self.config.hidden_size**0.5, dtype=hidden_states.dtype)
|
||||
# hidden_states = hidden_states * normalizer
|
||||
|
||||
# decoder layers
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_self_attns = () if output_attentions else None
|
||||
|
||||
for decoder_layer in self.layers[: self.config.num_hidden_layers]:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
layer_outputs = decoder_layer(
|
||||
hidden_states,
|
||||
attention_mask=causal_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_values,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
cache_position=cache_position,
|
||||
position_embeddings=position_embeddings,
|
||||
adarms_cond=adarms_cond,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
hidden_states = layer_outputs[0]
|
||||
|
||||
if output_attentions:
|
||||
all_self_attns += (layer_outputs[1],)
|
||||
|
||||
hidden_states, _ = self.norm(hidden_states, adarms_cond)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=past_key_values if use_cache else None,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_self_attns,
|
||||
)
|
||||
|
||||
|
||||
class KwargsForCausalLM(FlashAttentionKwargs, LossKwargs): ...
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class GemmaForCausalLM(GemmaPreTrainedModel, GenerationMixin):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
_tp_plan = {"lm_head": "colwise_rep"}
|
||||
_pp_plan = {"lm_head": (["hidden_states"], ["logits"])}
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = GemmaModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embed_tokens = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor | None = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: Cache | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
logits_to_keep: int | torch.Tensor = 0,
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
**kwargs: Unpack[KwargsForCausalLM],
|
||||
) -> CausalLMOutputWithPast:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
||||
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
||||
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
||||
|
||||
adarms_cond (`torch.Tensor` of shape `(batch_size, cond_dim)`, *optional*):
|
||||
Condition for ADARMS.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, GemmaForCausalLM
|
||||
|
||||
>>> model = GemmaForCausalLM.from_pretrained("google/gemma-7b")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
|
||||
|
||||
>>> prompt = "What is your favorite condiment?"
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> # Generate
|
||||
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
||||
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
"What is your favorite condiment?"
|
||||
```"""
|
||||
output_attentions = (
|
||||
output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
|
||||
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
||||
outputs: BaseModelOutputWithPast = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
cache_position=cache_position,
|
||||
adarms_cond=adarms_cond,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
hidden_states = outputs.last_hidden_state
|
||||
# Only compute necessary logits, and do not upcast them to float if we are not computing the loss
|
||||
slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
|
||||
logits = self.lm_head(hidden_states[:, slice_indices, :])
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(
|
||||
logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs
|
||||
)
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
|
||||
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
The Gemma Model transformer with a sequence classification head on top (linear layer).
|
||||
|
||||
[`GemmaForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
||||
(e.g. GPT-2) do.
|
||||
|
||||
Since it does classification on the last token, it requires to know the position of the last token. If a
|
||||
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
||||
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
||||
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
||||
each row of the batch).
|
||||
"""
|
||||
)
|
||||
class GemmaForSequenceClassification(GemmaPreTrainedModel):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.num_labels = config.num_labels
|
||||
self.model = GemmaModel(config)
|
||||
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embed_tokens = value
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor | None = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: Cache | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
) -> SequenceClassifierOutputWithPast:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
||||
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
||||
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
||||
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
||||
|
||||
adarms_cond (`torch.Tensor` of shape `(batch_size, cond_dim)`, *optional*):
|
||||
Condition for ADARMS.
|
||||
"""
|
||||
|
||||
transformer_outputs: BaseModelOutputWithPast = self.model(
|
||||
input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
adarms_cond=adarms_cond,
|
||||
)
|
||||
hidden_states = transformer_outputs.last_hidden_state
|
||||
logits = self.score(hidden_states)
|
||||
|
||||
if input_ids is not None:
|
||||
batch_size = input_ids.shape[0]
|
||||
else:
|
||||
batch_size = inputs_embeds.shape[0]
|
||||
|
||||
if self.config.pad_token_id is None and batch_size != 1:
|
||||
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
|
||||
if self.config.pad_token_id is None:
|
||||
last_non_pad_token = -1
|
||||
elif input_ids is not None:
|
||||
# To handle both left- and right- padding, we take the rightmost token that is not equal to pad_token_id
|
||||
non_pad_mask = (input_ids != self.config.pad_token_id).to(logits.device, torch.int32)
|
||||
token_indices = torch.arange(input_ids.shape[-1], device=logits.device, dtype=torch.int32)
|
||||
last_non_pad_token = (token_indices * non_pad_mask).argmax(-1)
|
||||
else:
|
||||
last_non_pad_token = -1
|
||||
logger.warning_once(
|
||||
f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
|
||||
"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
|
||||
)
|
||||
|
||||
pooled_logits = logits[torch.arange(batch_size, device=logits.device), last_non_pad_token]
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(
|
||||
logits=logits, labels=labels, pooled_logits=pooled_logits, config=self.config
|
||||
)
|
||||
|
||||
return SequenceClassifierOutputWithPast(
|
||||
loss=loss,
|
||||
logits=pooled_logits,
|
||||
past_key_values=transformer_outputs.past_key_values,
|
||||
hidden_states=transformer_outputs.hidden_states,
|
||||
attentions=transformer_outputs.attentions,
|
||||
)
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class GemmaForTokenClassification(GemmaPreTrainedModel):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.num_labels = config.num_labels
|
||||
self.model = GemmaModel(config)
|
||||
if getattr(config, "classifier_dropout", None) is not None:
|
||||
classifier_dropout = config.classifier_dropout
|
||||
elif getattr(config, "hidden_dropout", None) is not None:
|
||||
classifier_dropout = config.hidden_dropout
|
||||
else:
|
||||
classifier_dropout = 0.1
|
||||
self.dropout = nn.Dropout(classifier_dropout)
|
||||
self.score = nn.Linear(config.hidden_size, config.num_labels)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embed_tokens = value
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor | None = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: Cache | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
) -> TokenClassifierOutput:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
||||
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
||||
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
||||
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
||||
|
||||
adarms_cond (`torch.Tensor` of shape `(batch_size, cond_dim)`, *optional*):
|
||||
Condition for ADARMS.
|
||||
"""
|
||||
|
||||
outputs: BaseModelOutputWithPast = self.model(
|
||||
input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
adarms_cond=adarms_cond,
|
||||
)
|
||||
sequence_output = outputs.last_hidden_state
|
||||
sequence_output = self.dropout(sequence_output)
|
||||
logits = self.score(sequence_output)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(logits, labels, self.config)
|
||||
|
||||
return TokenClassifierOutput(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
|
||||
|
||||
__all__ = [
|
||||
"GemmaModel",
|
||||
"GemmaForCausalLM",
|
||||
"GemmaForSequenceClassification",
|
||||
"GemmaForTokenClassification",
|
||||
"GemmaPreTrainedModel",
|
||||
]
|
||||
+666
@@ -0,0 +1,666 @@
|
||||
# Copyright 2024 the HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""PyTorch PaliGemmamodel."""
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
import torch.utils.checkpoint
|
||||
from torch import nn
|
||||
|
||||
from ...cache_utils import Cache, HybridCache, StaticCache
|
||||
from ...generation import GenerationMixin
|
||||
from ...modeling_flash_attention_utils import FlashAttentionKwargs
|
||||
from ...modeling_outputs import BaseModelOutputWithPast
|
||||
from ...modeling_utils import PreTrainedModel
|
||||
from ...processing_utils import Unpack
|
||||
from ...utils import (
|
||||
LossKwargs,
|
||||
ModelOutput,
|
||||
auto_docstring,
|
||||
can_return_tuple,
|
||||
is_torchdynamo_compiling,
|
||||
logging,
|
||||
)
|
||||
from ..auto import AutoModel
|
||||
from .configuration_paligemma import PaliGemmaConfig
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
# Workaround for Python 3.10+ UnionType compatibility with transformers auto_docstring
|
||||
def safe_auto_docstring(func=None, **kwargs):
|
||||
"""Auto docstring decorator that handles Python 3.10+ UnionType gracefully."""
|
||||
|
||||
def decorator(f):
|
||||
try:
|
||||
return auto_docstring(f, **kwargs) if kwargs else auto_docstring(f)
|
||||
except (AttributeError, TypeError):
|
||||
# If auto_docstring fails due to UnionType, just return the function unchanged
|
||||
return f
|
||||
|
||||
if func is None:
|
||||
# Called with arguments, return the decorator
|
||||
return decorator
|
||||
else:
|
||||
# Called without arguments, apply directly
|
||||
return decorator(func)
|
||||
|
||||
|
||||
@dataclass
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
Base class for Paligemma outputs, with hidden states and attentions.
|
||||
"""
|
||||
)
|
||||
class PaligemmaModelOutputWithPast(BaseModelOutputWithPast):
|
||||
r"""
|
||||
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
|
||||
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
||||
`(batch_size, num_heads, sequence_length, embed_size_per_head)`)
|
||||
|
||||
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
|
||||
`past_key_values` input) to speed up sequential decoding.
|
||||
image_hidden_states (`torch.FloatTensor`, *optional*):
|
||||
A `torch.FloatTensor` of size `(batch_size, num_images, sequence_length, hidden_size)`.
|
||||
image_hidden_states of the model produced by the vision encoder and after projecting the last hidden state.
|
||||
"""
|
||||
|
||||
image_hidden_states: torch.FloatTensor | None = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
Base class for PaliGemma causal language model (or autoregressive) outputs.
|
||||
"""
|
||||
)
|
||||
class PaliGemmaCausalLMOutputWithPast(ModelOutput):
|
||||
r"""
|
||||
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
|
||||
Language modeling loss (for next-token prediction).
|
||||
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.text_config.vocab_size)`):
|
||||
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
|
||||
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
|
||||
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
||||
`(batch_size, num_heads, sequence_length, embed_size_per_head)`)
|
||||
|
||||
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
|
||||
`past_key_values` input) to speed up sequential decoding.
|
||||
image_hidden_states (`torch.FloatTensor`, *optional*):
|
||||
A `torch.FloatTensor` of size `(batch_size, num_images, sequence_length, hidden_size)`.
|
||||
image_hidden_states of the model produced by the vision encoder after projecting last hidden state.
|
||||
"""
|
||||
|
||||
loss: torch.FloatTensor | None = None
|
||||
logits: torch.FloatTensor | None = None
|
||||
past_key_values: list[torch.FloatTensor] | Cache | None = None
|
||||
hidden_states: tuple[torch.FloatTensor] | None = None
|
||||
attentions: tuple[torch.FloatTensor] | None = None
|
||||
image_hidden_states: torch.FloatTensor | None = None
|
||||
|
||||
|
||||
class PaliGemmaMultiModalProjector(nn.Module):
|
||||
def __init__(self, config: PaliGemmaConfig):
|
||||
super().__init__()
|
||||
self.linear = nn.Linear(
|
||||
config.vision_config.hidden_size, config.vision_config.projection_dim, bias=True
|
||||
)
|
||||
|
||||
def forward(self, image_features):
|
||||
hidden_states = self.linear(image_features)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class PaliGemmaPreTrainedModel(PreTrainedModel):
|
||||
config_class = PaliGemmaConfig
|
||||
base_model_prefix = ""
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ["PaliGemmaMultiModalProjector"]
|
||||
_skip_keys_device_placement = "past_key_values"
|
||||
_supports_cache_class = True
|
||||
_supports_quantized_cache = True
|
||||
_supports_static_cache = True
|
||||
_supports_flash_attn_2 = True
|
||||
_supports_sdpa = True
|
||||
_supports_flex_attn = True
|
||||
_supports_attention_backend = True
|
||||
|
||||
def _init_weights(self, module):
|
||||
# important: this ported version of PaliGemmaisn't meant for training from scratch - only
|
||||
# inference and fine-tuning
|
||||
std = getattr(self.config, "initializer_range", self.config.get_text_config().initializer_range)
|
||||
|
||||
if isinstance(module, nn.Linear):
|
||||
module.weight.data.normal_(mean=0.0, std=std)
|
||||
if module.bias is not None:
|
||||
module.bias.data.zero_()
|
||||
|
||||
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
The Base Paligemma model which consists of a vision backbone and a language model without language modeling head.,
|
||||
"""
|
||||
)
|
||||
class PaliGemmaModel(PaliGemmaPreTrainedModel):
|
||||
_checkpoint_conversion_mapping = {"language_model.model": "language_model"}
|
||||
# we are filtering the logits/labels so we shouldn't divide the loss based on num_items_in_batch
|
||||
accepts_loss_kwargs = False
|
||||
|
||||
def __init__(self, config: PaliGemmaConfig):
|
||||
super().__init__(config)
|
||||
self.vision_tower = AutoModel.from_config(config=config.vision_config)
|
||||
self.multi_modal_projector = PaliGemmaMultiModalProjector(config)
|
||||
self.vocab_size = config.text_config.vocab_size
|
||||
|
||||
language_model = AutoModel.from_config(config=config.text_config)
|
||||
self.language_model = language_model
|
||||
|
||||
self.pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else -1
|
||||
self.post_init()
|
||||
|
||||
# Copied from transformers.models.llava.modeling_llava.LlavaModel.get_input_embeddings with Llava->PaliGemma
|
||||
def get_input_embeddings(self):
|
||||
return self.language_model.get_input_embeddings()
|
||||
|
||||
# Copied from transformers.models.llava.modeling_llava.LlavaModel.set_input_embeddings with Llava->PaliGemma
|
||||
def set_input_embeddings(self, value):
|
||||
self.language_model.set_input_embeddings(value)
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.language_model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.language_model
|
||||
|
||||
def _update_causal_mask(
|
||||
self,
|
||||
attention_mask,
|
||||
token_type_ids=None,
|
||||
past_key_values=None,
|
||||
cache_position=None,
|
||||
input_tensor=None,
|
||||
is_training: bool | None = None,
|
||||
):
|
||||
if self.config.text_config._attn_implementation == "flash_attention_2":
|
||||
if attention_mask is not None and 0.0 in attention_mask:
|
||||
return attention_mask
|
||||
return None
|
||||
is_training = is_training if is_training is not None else self.training
|
||||
using_static_cache = isinstance(past_key_values, StaticCache)
|
||||
min_dtype = torch.finfo(self.dtype).min
|
||||
if input_tensor is None:
|
||||
input_tensor = attention_mask
|
||||
|
||||
inputs_lead_dim, sequence_length = input_tensor.shape[:2]
|
||||
if using_static_cache:
|
||||
target_length = past_key_values.get_max_cache_shape()
|
||||
elif isinstance(past_key_values, HybridCache):
|
||||
target_length = past_key_values.get_max_cache_shape()
|
||||
else:
|
||||
target_length = (
|
||||
attention_mask.shape[-1]
|
||||
if isinstance(attention_mask, torch.Tensor)
|
||||
else cache_position[0] + sequence_length + 1
|
||||
)
|
||||
|
||||
if attention_mask is not None and attention_mask.dim() == 4:
|
||||
# In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
|
||||
return attention_mask
|
||||
|
||||
causal_mask = torch.full(
|
||||
(sequence_length, target_length),
|
||||
fill_value=min_dtype,
|
||||
dtype=self.dtype,
|
||||
device=cache_position.device,
|
||||
)
|
||||
# Causal diagonal mask only if training, otherwise attend to the whole prefix. Training-specific attn for prefix is handled below
|
||||
if sequence_length != 1:
|
||||
if is_training:
|
||||
causal_mask = torch.triu(causal_mask, diagonal=1)
|
||||
else:
|
||||
causal_mask[:, :sequence_length] = 0.0
|
||||
|
||||
causal_mask *= torch.arange(target_length, device=cache_position.device) > cache_position.reshape(
|
||||
-1, 1
|
||||
)
|
||||
causal_mask = causal_mask[None, None, :, :].expand(inputs_lead_dim, 1, -1, -1)
|
||||
if attention_mask is not None:
|
||||
causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
|
||||
mask_length = attention_mask.shape[-1]
|
||||
|
||||
# First unmask prefix tokens during training
|
||||
if is_training:
|
||||
if token_type_ids is None:
|
||||
raise ValueError("Token type ids must be provided during training")
|
||||
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
|
||||
token_type_ids[:, None, None, :].to(causal_mask.device) == 0, 0
|
||||
)
|
||||
|
||||
# Then apply padding mask (will mask pad tokens)
|
||||
padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
|
||||
causal_mask.device
|
||||
)
|
||||
padding_mask = padding_mask == 0
|
||||
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
|
||||
padding_mask, min_dtype
|
||||
)
|
||||
|
||||
return causal_mask
|
||||
|
||||
def get_image_features(self, pixel_values: torch.FloatTensor):
|
||||
"""
|
||||
Obtains image last hidden states from the vision tower and apply multimodal projection.
|
||||
|
||||
Args:
|
||||
pixel_values (`torch.FloatTensor]` of shape `(batch_size, channels, height, width)`)
|
||||
The tensors corresponding to the input images.
|
||||
Returns:
|
||||
image_features (`torch.Tensor`): Image feature tensor of shape `(num_images, image_length, embed_dim)`).
|
||||
"""
|
||||
image_outputs = self.vision_tower(pixel_values)
|
||||
selected_image_feature = image_outputs.last_hidden_state
|
||||
image_features = self.multi_modal_projector(selected_image_feature)
|
||||
return image_features
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
pixel_values: torch.FloatTensor = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: list[torch.FloatTensor] | Cache | None = None,
|
||||
token_type_ids: torch.LongTensor | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
return_dict: bool | None = None,
|
||||
**kwargs: Unpack[FlashAttentionKwargs],
|
||||
) -> tuple | PaligemmaModelOutputWithPast:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
||||
config.text_config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
||||
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.text_config.vocab_size]`.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from PIL import Image
|
||||
>>> import requests
|
||||
>>> from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
|
||||
|
||||
>>> model = PaliGemmaForConditionalGeneration.from_pretrained("google/paligemma2-3b-mix-224")
|
||||
>>> processor = AutoProcessor.from_pretrained("google/paligemma2-3b-mix-224")
|
||||
|
||||
>>> prompt = "Where is the cat standing?"
|
||||
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
>>> image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
>>> inputs = processor(images=image, text=prompt, return_tensors="pt")
|
||||
|
||||
>>> # Generate
|
||||
>>> generate_ids = model.generate(**inputs,)
|
||||
>>> processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
"Where is the cat standing?\nsnow"
|
||||
```"""
|
||||
|
||||
if (input_ids is None) ^ (inputs_embeds is not None):
|
||||
raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
|
||||
|
||||
output_attentions = (
|
||||
output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
is_training = token_type_ids is not None and labels is not None
|
||||
|
||||
# Replace image id with PAD if the image token if OOV, to avoid index-errors
|
||||
if input_ids is not None and self.config.image_token_id >= self.vocab_size:
|
||||
special_image_mask = input_ids == self.config.image_token_id
|
||||
llm_input_ids = input_ids.clone()
|
||||
llm_input_ids[special_image_mask] = 0
|
||||
else:
|
||||
llm_input_ids = input_ids
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.get_input_embeddings()(llm_input_ids)
|
||||
|
||||
if cache_position is None:
|
||||
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
|
||||
cache_position = torch.arange(
|
||||
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
|
||||
)
|
||||
|
||||
if position_ids is None:
|
||||
position_ids = cache_position.unsqueeze(0) + 1 # Paligemma positions are 1-indexed
|
||||
|
||||
# Merge text and images
|
||||
if pixel_values is not None:
|
||||
image_features = self.get_image_features(pixel_values)
|
||||
|
||||
if input_ids is None:
|
||||
special_image_mask = inputs_embeds == self.get_input_embeddings()(
|
||||
torch.tensor(self.config.image_token_id, dtype=torch.long, device=inputs_embeds.device)
|
||||
)
|
||||
else:
|
||||
special_image_mask = (input_ids == self.config.image_token_id).unsqueeze(-1)
|
||||
special_image_mask = special_image_mask.expand_as(inputs_embeds).to(inputs_embeds.device)
|
||||
|
||||
if (
|
||||
not is_torchdynamo_compiling()
|
||||
and inputs_embeds[special_image_mask].numel() != image_features.numel()
|
||||
):
|
||||
image_tokens_in_text = (special_image_mask).sum(dim=1).sum(dim=0)[0]
|
||||
raise ValueError(
|
||||
f"Number of images does not match number of special image tokens in the input text. "
|
||||
f"Got {image_tokens_in_text} image tokens in the text but {image_features.shape[0] * image_features.shape[1]} "
|
||||
"tokens from image embeddings."
|
||||
)
|
||||
image_features = image_features.to(inputs_embeds.device, inputs_embeds.dtype)
|
||||
inputs_embeds = inputs_embeds.masked_scatter(special_image_mask, image_features)
|
||||
|
||||
causal_mask = self._update_causal_mask(
|
||||
attention_mask, token_type_ids, past_key_values, cache_position, inputs_embeds, is_training
|
||||
)
|
||||
outputs = self.language_model(
|
||||
attention_mask=causal_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=True,
|
||||
cache_position=cache_position,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
return PaligemmaModelOutputWithPast(
|
||||
last_hidden_state=outputs.last_hidden_state,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
image_hidden_states=image_features if pixel_values is not None else None,
|
||||
)
|
||||
|
||||
|
||||
class KwargsForCausalLM(FlashAttentionKwargs, LossKwargs): ...
|
||||
|
||||
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
The Base Paligemma model which consists of a vision backbone and a language model without language modeling head.,
|
||||
"""
|
||||
)
|
||||
class PaliGemmaForConditionalGeneration(PaliGemmaPreTrainedModel, GenerationMixin):
|
||||
_checkpoint_conversion_mapping = {
|
||||
"^language_model.model": "model.language_model",
|
||||
"^vision_tower": "model.vision_tower",
|
||||
"^multi_modal_projector": "model.multi_modal_projector",
|
||||
"^language_model.lm_head": "lm_head",
|
||||
}
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config: PaliGemmaConfig):
|
||||
super().__init__(config)
|
||||
self.model = PaliGemmaModel(config)
|
||||
self.lm_head = nn.Linear(config.text_config.hidden_size, config.text_config.vocab_size, bias=False)
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.get_input_embeddings()
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.set_input_embeddings(value)
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model.set_decoder(decoder)
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model.get_decoder()
|
||||
|
||||
def get_image_features(self, pixel_values):
|
||||
return self.model.get_image_features(pixel_values)
|
||||
|
||||
# Make modules available through conditional class for BC
|
||||
@property
|
||||
def language_model(self):
|
||||
return self.model.language_model
|
||||
|
||||
@property
|
||||
def vision_tower(self):
|
||||
return self.model.vision_tower
|
||||
|
||||
@property
|
||||
def multi_modal_projector(self):
|
||||
return self.model.multi_modal_projector
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
pixel_values: torch.FloatTensor = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: list[torch.FloatTensor] | Cache | None = None,
|
||||
token_type_ids: torch.LongTensor | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
return_dict: bool | None = None,
|
||||
logits_to_keep: int | torch.Tensor = 0,
|
||||
**kwargs: Unpack[KwargsForCausalLM],
|
||||
) -> tuple | PaliGemmaCausalLMOutputWithPast:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
||||
config.text_config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
||||
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.text_config.vocab_size]`.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from PIL import Image
|
||||
>>> import requests
|
||||
>>> from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
|
||||
|
||||
>>> model = PaliGemmaForConditionalGeneration.from_pretrained("google/paligemma2-3b-mix-224")
|
||||
>>> processor = AutoProcessor.from_pretrained("google/paligemma2-3b-mix-224")
|
||||
|
||||
>>> prompt = "Where is the cat standing?"
|
||||
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
>>> image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
>>> inputs = processor(images=image, text=prompt, return_tensors="pt")
|
||||
|
||||
>>> # Generate
|
||||
>>> generate_ids = model.generate(**inputs,)
|
||||
>>> processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
"Where is the cat standing?\nsnow"
|
||||
```"""
|
||||
output_attentions = (
|
||||
output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
pixel_values=pixel_values,
|
||||
token_type_ids=token_type_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
labels=labels,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=True,
|
||||
cache_position=cache_position,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
# Only compute necessary logits, and do not upcast them to float if we are not computing the loss
|
||||
slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
|
||||
logits = self.lm_head(hidden_states[:, slice_indices, :])
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(
|
||||
logits=logits, labels=labels, vocab_size=self.config.text_config.vocab_size, **kwargs
|
||||
)
|
||||
|
||||
return PaliGemmaCausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
image_hidden_states=outputs.image_hidden_states,
|
||||
)
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids,
|
||||
past_key_values=None,
|
||||
inputs_embeds=None,
|
||||
cache_position=None,
|
||||
position_ids=None,
|
||||
pixel_values=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
use_cache=True,
|
||||
logits_to_keep=None,
|
||||
labels=None,
|
||||
**kwargs,
|
||||
):
|
||||
# Overwritten -- custom `position_ids` and `pixel_values` handling
|
||||
model_inputs = super().prepare_inputs_for_generation(
|
||||
input_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
cache_position=cache_position,
|
||||
use_cache=use_cache,
|
||||
logits_to_keep=logits_to_keep,
|
||||
token_type_ids=token_type_ids,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
# position_ids in Paligemma are 1-indexed
|
||||
if model_inputs.get("position_ids") is not None:
|
||||
model_inputs["position_ids"] += 1
|
||||
# If we're in cached decoding stage, pixel values should be None because input ids do not contain special image token anymore
|
||||
# Otherwise we need pixel values to be passed to model. NOTE: use_cache=False needs pixel_values always
|
||||
if cache_position[0] == 0:
|
||||
model_inputs["pixel_values"] = pixel_values
|
||||
is_training = token_type_ids is not None and labels is not None
|
||||
if cache_position[0] == 0 and isinstance(past_key_values, HybridCache):
|
||||
input_tensor = inputs_embeds if inputs_embeds is not None else input_ids
|
||||
causal_mask = self.model._update_causal_mask(
|
||||
attention_mask, token_type_ids, past_key_values, cache_position, input_tensor, is_training
|
||||
)
|
||||
model_inputs["attention_mask"] = causal_mask
|
||||
|
||||
return model_inputs
|
||||
|
||||
@staticmethod
|
||||
# Copied from transformers.models.gptj.modeling_gptj.GPTJModel._prepare_4d_causal_attention_mask_with_cache_position
|
||||
def _prepare_4d_causal_attention_mask_with_cache_position(
|
||||
attention_mask: torch.Tensor,
|
||||
sequence_length: int,
|
||||
target_length: int,
|
||||
dtype: torch.dtype,
|
||||
cache_position: torch.Tensor,
|
||||
batch_size: int,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
|
||||
`(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
|
||||
|
||||
Args:
|
||||
attention_mask (`torch.Tensor`):
|
||||
A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
|
||||
`(batch_size, 1, query_length, key_value_length)`.
|
||||
sequence_length (`int`):
|
||||
The sequence length being processed.
|
||||
target_length (`int`):
|
||||
The target length: when generating with static cache, the mask should be as long as the static cache,
|
||||
to account for the 0 padding, the part of the cache that is not filled yet.
|
||||
dtype (`torch.dtype`):
|
||||
The dtype to use for the 4D attention mask.
|
||||
cache_position (`torch.Tensor`):
|
||||
Indices depicting the position of the input sequence tokens in the sequence.
|
||||
batch_size (`torch.Tensor`):
|
||||
Batch size.
|
||||
"""
|
||||
if attention_mask is not None and attention_mask.dim() == 4:
|
||||
# In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
|
||||
causal_mask = attention_mask
|
||||
else:
|
||||
min_dtype = torch.finfo(dtype).min
|
||||
causal_mask = torch.full(
|
||||
(sequence_length, target_length),
|
||||
fill_value=min_dtype,
|
||||
dtype=dtype,
|
||||
device=cache_position.device,
|
||||
)
|
||||
if sequence_length != 1:
|
||||
causal_mask = torch.triu(causal_mask, diagonal=1)
|
||||
causal_mask *= torch.arange(target_length, device=cache_position.device) > cache_position.reshape(
|
||||
-1, 1
|
||||
)
|
||||
causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
|
||||
if attention_mask is not None:
|
||||
causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
|
||||
mask_length = attention_mask.shape[-1]
|
||||
padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
|
||||
causal_mask.device
|
||||
)
|
||||
padding_mask = padding_mask == 0
|
||||
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
|
||||
padding_mask, min_dtype
|
||||
)
|
||||
|
||||
return causal_mask
|
||||
|
||||
|
||||
__all__ = ["PaliGemmaForConditionalGeneration", "PaliGemmaPreTrainedModel", "PaliGemmaModel"]
|
||||
@@ -0,0 +1,5 @@
|
||||
import transformers
|
||||
|
||||
|
||||
def check_whether_transformers_replace_is_installed_correctly():
|
||||
return transformers.__version__ == "4.53.2"
|
||||
+1283
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,92 @@
|
||||
# π₀ (pi0)
|
||||
|
||||
This repository contains the Hugging Face port of **π₀**, adapted from [OpenPI](https://github.com/Physical-Intelligence/openpi) by the Physical Intelligence.
|
||||
It is designed as a **Vision-Language-Action flow model for general robot control**.
|
||||
|
||||
---
|
||||
|
||||
### ⚠️ WARNING ⚠️
|
||||
|
||||
This project requires **patching the Hugging Face `transformers` library**.
|
||||
|
||||
1. Make sure you have the exact version installed:
|
||||
|
||||
```bash
|
||||
pip show transformers
|
||||
```
|
||||
|
||||
It must be version **4.53.2**.
|
||||
|
||||
2. Apply the custom patches by copying the modified files into your environment:
|
||||
|
||||
```bash
|
||||
cp -r ./src/lerobot/policies/pi0_openpi/transformers_replace/* \
|
||||
$(python -c "import transformers, os; print(os.path.dirname(transformers.__file__))")
|
||||
```
|
||||
|
||||
These patches overwrite parts of `transformers` to:
|
||||
- Support the **AdaRMS optimizer**,
|
||||
- Correctly control the precision of activations,
|
||||
- Allow the KV cache to be used without updates.
|
||||
|
||||
**Important:**
|
||||
|
||||
- This permanently modifies your `transformers` installation.
|
||||
- The changes survive reinstalls unless you explicitly remove the patched files or recreate the environment.
|
||||
|
||||
To undo and restore a clean state:
|
||||
|
||||
```bash
|
||||
pip uninstall transformers
|
||||
pip install transformers==4.53.2
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Model Overview
|
||||
|
||||
| Feature | π₀ | π₀.₅ |
|
||||
| -------------------- | ------------------------------------------------------ | ----------------------------------------- |
|
||||
| State Embedding | Uses `state_proj` layer | No state embedding |
|
||||
| Time Conditioning | Concatenates time with actions via `action_time_mlp_*` | Uses `time_mlp_*` for AdaRMS conditioning |
|
||||
| AdaRMS | Not used | Used in action expert |
|
||||
| Tokenizer Length | 48 tokens | 200 tokens |
|
||||
| Discrete State Input | False | True |
|
||||
| Parameter Count | Higher (includes state embedding) | Lower (no state embedding) |
|
||||
|
||||
---
|
||||
|
||||
## Citation
|
||||
|
||||
If you use this work, please cite both **OpenPI** and the π₀ paper:
|
||||
|
||||
```bibtex
|
||||
@misc{openpi2024,
|
||||
author = {Physical Intelligence Lab},
|
||||
title = {OpenPI: PyTorch Implementation of π0 and π0.5 Policies},
|
||||
year = {2024},
|
||||
publisher = {GitHub},
|
||||
howpublished = {\url{https://github.com/Physical-Intelligence/openpi}},
|
||||
license = {Apache-2.0}
|
||||
}
|
||||
|
||||
@misc{black2024pi0visionlanguageactionflowmodel,
|
||||
title = {π₀: A Vision-Language-Action Flow Model for General Robot Control},
|
||||
author = {Kevin Black and Noah Brown and Danny Driess and Adnan Esmail and Michael Equi and Chelsea Finn and Niccolo Fusai and Lachy Groom and Karol Hausman and Brian Ichter and Szymon Jakubczak and Tim Jones and Liyiming Ke and Sergey Levine and Adrian Li-Bell and Mohith Mothukuri and Suraj Nair and Karl Pertsch and Lucy Xiaoyang Shi and James Tanner and Quan Vuong and Anna Walling and Haohuan Wang and Ury Zhilinsky},
|
||||
year = {2024},
|
||||
eprint = {2410.24164},
|
||||
archivePrefix= {arXiv},
|
||||
primaryClass = {cs.LG},
|
||||
url = {https://arxiv.org/abs/2410.24164},
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## License
|
||||
|
||||
This port follows the **Apache 2.0 License**, consistent with the original [OpenPI repository](https://github.com/Physical-Intelligence/openpi).
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
@@ -0,0 +1,20 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
# Copyright 2025 Physical Intelligence and The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from .configuration_pi0openpi import PI0OpenPIConfig
|
||||
from .modeling_pi0openpi import PI0OpenPIPolicy
|
||||
|
||||
__all__ = ["PI0OpenPIConfig", "PI0OpenPIPolicy"]
|
||||
@@ -0,0 +1,134 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
# Copyright 2025 Physical Intelligence and The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from dataclasses import dataclass, field
|
||||
|
||||
from lerobot.configs.policies import PreTrainedConfig
|
||||
from lerobot.configs.types import NormalizationMode
|
||||
from lerobot.optim.optimizers import AdamWConfig
|
||||
from lerobot.optim.schedulers import CosineDecayWithWarmupSchedulerConfig
|
||||
|
||||
|
||||
@PreTrainedConfig.register_subclass("pi0_openpi")
|
||||
@dataclass
|
||||
class PI0OpenPIConfig(PreTrainedConfig):
|
||||
# Model architecture
|
||||
paligemma_variant: str = "gemma_2b"
|
||||
action_expert_variant: str = "gemma_300m"
|
||||
dtype: str = "float32" # Options: "bfloat16", "float32"
|
||||
|
||||
# Input / output structure
|
||||
n_obs_steps: int = 1
|
||||
chunk_size: int = 50 # Number of action steps to predict, in openpi called "action_horizon"
|
||||
n_action_steps: int = 50 # Number of action steps to execute
|
||||
|
||||
# Shorter state and action vectors will be padded to these dimensions
|
||||
max_state_dim: int = 32 # State dimension (will be padded to 32)
|
||||
max_action_dim: int = 32 # Action dimension (will be padded to 32)
|
||||
|
||||
# Flow matching parameters: see openpi `PI0Pytorch`
|
||||
num_inference_steps: int = 10 # Number of denoising steps during inference
|
||||
time_sampling_beta_alpha: float = 1.5 # Beta distribution alpha parameter for time sampling
|
||||
time_sampling_beta_beta: float = 1.0 # Beta distribution beta parameter for time sampling
|
||||
min_period: float = 4e-3 # Min period for sinusoidal positional encoding
|
||||
max_period: float = 4.0 # Max period for sinusoidal positional encoding
|
||||
|
||||
# Image preprocessing
|
||||
image_resolution: tuple[int, int] = (224, 224) # see openpi `preprocessing_pytorch.py`
|
||||
|
||||
# Normalization
|
||||
normalization_mapping: dict[str, NormalizationMode] = field(
|
||||
default_factory=lambda: {
|
||||
"VISUAL": NormalizationMode.IDENTITY, # Images are normalized to [-1, 1] in preprocessing
|
||||
"STATE": NormalizationMode.MEAN_STD,
|
||||
"ACTION": NormalizationMode.MEAN_STD,
|
||||
}
|
||||
)
|
||||
|
||||
# Training settings
|
||||
gradient_checkpointing: bool = False # Enable gradient checkpointing for memory optimization
|
||||
compile_model: bool = False # Whether to use torch.compile for model optimization
|
||||
compile_mode: str = "max-autotune" # Torch compile mode
|
||||
device: str | None = None # Device to use for the model (None = auto-detect)
|
||||
|
||||
# Optimizer settings: see openpi `AdamW` and
|
||||
optimizer_lr: float = 2.5e-5 # see openpi `CosineDecaySchedule: peak_lr`
|
||||
optimizer_betas: tuple[float, float] = (0.9, 0.95)
|
||||
optimizer_eps: float = 1e-8
|
||||
optimizer_weight_decay: float = 0.01
|
||||
optimizer_grad_clip_norm: float = 1.0
|
||||
|
||||
# Scheduler settings: see openpi `CosineDecaySchedule`
|
||||
scheduler_warmup_steps: int = 1_000
|
||||
scheduler_decay_steps: int = 30_000
|
||||
scheduler_decay_lr: float = 2.5e-6
|
||||
|
||||
tokenizer_max_length: int = 48 # pi0=48, see openpi `__post_init__`
|
||||
|
||||
def __post_init__(self):
|
||||
super().__post_init__()
|
||||
|
||||
# Validate configuration
|
||||
if self.n_action_steps > self.chunk_size:
|
||||
raise ValueError(
|
||||
f"n_action_steps ({self.n_action_steps}) cannot be greater than chunk_size ({self.chunk_size})"
|
||||
)
|
||||
|
||||
if self.paligemma_variant not in ["gemma_300m", "gemma_2b"]:
|
||||
raise ValueError(f"Invalid paligemma_variant: {self.paligemma_variant}")
|
||||
|
||||
if self.action_expert_variant not in ["gemma_300m", "gemma_2b"]:
|
||||
raise ValueError(f"Invalid action_expert_variant: {self.action_expert_variant}")
|
||||
|
||||
if self.dtype not in ["bfloat16", "float32"]:
|
||||
raise ValueError(f"Invalid dtype: {self.dtype}")
|
||||
|
||||
def validate_features(self) -> None:
|
||||
"""Validate and set up input/output features."""
|
||||
# Image features are now handled dynamically through dataset configuration
|
||||
# No need to auto-add hardcoded image keys
|
||||
|
||||
# State and action features are also handled dynamically through dataset configuration
|
||||
# The actual dimensions come from the feature shapes, max dimensions are used for padding only
|
||||
pass
|
||||
|
||||
def get_optimizer_preset(self) -> AdamWConfig:
|
||||
return AdamWConfig(
|
||||
lr=self.optimizer_lr,
|
||||
betas=self.optimizer_betas,
|
||||
eps=self.optimizer_eps,
|
||||
weight_decay=self.optimizer_weight_decay,
|
||||
grad_clip_norm=self.optimizer_grad_clip_norm,
|
||||
)
|
||||
|
||||
def get_scheduler_preset(self):
|
||||
return CosineDecayWithWarmupSchedulerConfig(
|
||||
peak_lr=self.optimizer_lr,
|
||||
decay_lr=self.scheduler_decay_lr,
|
||||
num_warmup_steps=self.scheduler_warmup_steps,
|
||||
num_decay_steps=self.scheduler_decay_steps,
|
||||
)
|
||||
|
||||
@property
|
||||
def observation_delta_indices(self) -> None:
|
||||
return None
|
||||
|
||||
@property
|
||||
def action_delta_indices(self) -> list:
|
||||
return list(range(self.chunk_size))
|
||||
|
||||
@property
|
||||
def reward_delta_indices(self) -> None:
|
||||
return None
|
||||
File diff suppressed because it is too large
Load Diff
+173
@@ -0,0 +1,173 @@
|
||||
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
|
||||
# This file was automatically generated from src/transformers/models/gemma/modular_gemma.py.
|
||||
# Do NOT edit this file manually as any edits will be overwritten by the generation of
|
||||
# the file from the modular. If any change should be done, please apply the change to the
|
||||
# modular_gemma.py file directly. One of our CI enforces this.
|
||||
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
|
||||
# coding=utf-8
|
||||
# Copyright 2024 Google Inc. HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from ...configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class GemmaConfig(PretrainedConfig):
|
||||
r"""
|
||||
This is the configuration class to store the configuration of a [`GemmaModel`]. It is used to instantiate an Gemma
|
||||
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
|
||||
defaults will yield a similar configuration to that of the Gemma-7B.
|
||||
e.g. [google/gemma-7b](https://huggingface.co/google/gemma-7b)
|
||||
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||
documentation from [`PretrainedConfig`] for more information.
|
||||
Args:
|
||||
vocab_size (`int`, *optional*, defaults to 256000):
|
||||
Vocabulary size of the Gemma model. Defines the number of different tokens that can be represented by the
|
||||
`inputs_ids` passed when calling [`GemmaModel`]
|
||||
hidden_size (`int`, *optional*, defaults to 3072):
|
||||
Dimension of the hidden representations.
|
||||
intermediate_size (`int`, *optional*, defaults to 24576):
|
||||
Dimension of the MLP representations.
|
||||
num_hidden_layers (`int`, *optional*, defaults to 28):
|
||||
Number of hidden layers in the Transformer decoder.
|
||||
num_attention_heads (`int`, *optional*, defaults to 16):
|
||||
Number of attention heads for each attention layer in the Transformer decoder.
|
||||
num_key_value_heads (`int`, *optional*, defaults to 16):
|
||||
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
||||
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
||||
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
||||
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
||||
by meanpooling all the original heads within that group. For more details, check out [this
|
||||
paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
|
||||
`num_attention_heads`.
|
||||
head_dim (`int`, *optional*, defaults to 256):
|
||||
The attention head dimension.
|
||||
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
|
||||
The legacy activation function. It is overwritten by the `hidden_activation`.
|
||||
hidden_activation (`str` or `function`, *optional*):
|
||||
The non-linear activation function (function or string) in the decoder. Will default to `"gelu_pytorch_tanh"`
|
||||
if not specified. `"gelu_pytorch_tanh"` uses an approximation of the `"gelu"` activation function.
|
||||
max_position_embeddings (`int`, *optional*, defaults to 8192):
|
||||
The maximum sequence length that this model might ever be used with.
|
||||
initializer_range (`float`, *optional*, defaults to 0.02):
|
||||
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
||||
The epsilon used by the rms normalization layers.
|
||||
use_cache (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
||||
relevant if `config.is_decoder=True`.
|
||||
pad_token_id (`int`, *optional*, defaults to 0):
|
||||
Padding token id.
|
||||
eos_token_id (`int`, *optional*, defaults to 1):
|
||||
End of stream token id.
|
||||
bos_token_id (`int`, *optional*, defaults to 2):
|
||||
Beginning of stream token id.
|
||||
tie_word_embeddings (`bool`, *optional*, defaults to `True`):
|
||||
Whether to tie weight embeddings
|
||||
rope_theta (`float`, *optional*, defaults to 10000.0):
|
||||
The base period of the RoPE embeddings.
|
||||
attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
|
||||
Whether to use a bias in the query, key, value and output projection layers during self-attention.
|
||||
attention_dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout ratio for the attention probabilities.
|
||||
use_adarms (`bool`, *optional*, defaults to `False`):
|
||||
Whether to use ADARMS.
|
||||
adarms_cond_dim (`int`, *optional*, defaults to `None`):
|
||||
The dimension of the ADARMS condition.
|
||||
```python
|
||||
>>> from transformers import GemmaModel, GemmaConfig
|
||||
>>> # Initializing a Gemma gemma-7b style configuration
|
||||
>>> configuration = GemmaConfig()
|
||||
>>> # Initializing a model from the gemma-7b style configuration
|
||||
>>> model = GemmaModel(configuration)
|
||||
>>> # Accessing the model configuration
|
||||
>>> configuration = model.config
|
||||
```"""
|
||||
|
||||
model_type = "gemma"
|
||||
keys_to_ignore_at_inference = ["past_key_values"]
|
||||
base_model_tp_plan = {
|
||||
"layers.*.self_attn.q_proj": "colwise",
|
||||
"layers.*.self_attn.k_proj": "colwise",
|
||||
"layers.*.self_attn.v_proj": "colwise",
|
||||
"layers.*.self_attn.o_proj": "rowwise",
|
||||
"layers.*.mlp.gate_proj": "colwise",
|
||||
"layers.*.mlp.up_proj": "colwise",
|
||||
"layers.*.mlp.down_proj": "rowwise",
|
||||
}
|
||||
base_model_pp_plan = {
|
||||
"embed_tokens": (["input_ids"], ["inputs_embeds"]),
|
||||
"layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
|
||||
"norm": (["hidden_states"], ["hidden_states"]),
|
||||
}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size=256000,
|
||||
hidden_size=3072,
|
||||
intermediate_size=24576,
|
||||
num_hidden_layers=28,
|
||||
num_attention_heads=16,
|
||||
num_key_value_heads=16,
|
||||
head_dim=256,
|
||||
hidden_act="gelu_pytorch_tanh",
|
||||
hidden_activation=None,
|
||||
max_position_embeddings=8192,
|
||||
initializer_range=0.02,
|
||||
rms_norm_eps=1e-6,
|
||||
use_cache=True,
|
||||
pad_token_id=0,
|
||||
eos_token_id=1,
|
||||
bos_token_id=2,
|
||||
tie_word_embeddings=True,
|
||||
rope_theta=10000.0,
|
||||
attention_bias=False,
|
||||
attention_dropout=0.0,
|
||||
use_adarms: bool = False,
|
||||
adarms_cond_dim: int | None = None,
|
||||
**kwargs,
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.head_dim = head_dim
|
||||
self.num_key_value_heads = num_key_value_heads
|
||||
self.hidden_act = hidden_act
|
||||
self.hidden_activation = hidden_activation
|
||||
self.initializer_range = initializer_range
|
||||
self.rms_norm_eps = rms_norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.rope_theta = rope_theta
|
||||
self.attention_bias = attention_bias
|
||||
self.attention_dropout = attention_dropout
|
||||
self.use_adarms = use_adarms
|
||||
self.adarms_cond_dim = adarms_cond_dim
|
||||
|
||||
# Set default for adarms_cond_dim if use_adarms is True
|
||||
if self.use_adarms and self.adarms_cond_dim is None:
|
||||
self.adarms_cond_dim = self.hidden_size
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
__all__ = ["GemmaConfig"]
|
||||
@@ -0,0 +1,895 @@
|
||||
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
|
||||
# This file was automatically generated from src/transformers/models/gemma/modular_gemma.py.
|
||||
# Do NOT edit this file manually as any edits will be overwritten by the generation of
|
||||
# the file from the modular. If any change should be done, please apply the change to the
|
||||
# modular_gemma.py file directly. One of our CI enforces this.
|
||||
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
|
||||
# coding=utf-8
|
||||
# Copyright 2024 Google Inc. HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from collections.abc import Callable
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from ...activations import ACT2FN
|
||||
from ...cache_utils import Cache, DynamicCache
|
||||
from ...generation import GenerationMixin
|
||||
from ...masking_utils import create_causal_mask
|
||||
from ...modeling_flash_attention_utils import FlashAttentionKwargs
|
||||
from ...modeling_layers import GradientCheckpointingLayer
|
||||
from ...modeling_outputs import (
|
||||
BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast,
|
||||
SequenceClassifierOutputWithPast,
|
||||
TokenClassifierOutput,
|
||||
)
|
||||
from ...modeling_rope_utils import ROPE_INIT_FUNCTIONS, dynamic_rope_update
|
||||
from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
|
||||
from ...processing_utils import Unpack
|
||||
from ...utils import LossKwargs, auto_docstring, can_return_tuple, logging
|
||||
from .configuration_gemma import GemmaConfig
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
# Workaround for Python 3.10+ UnionType compatibility with transformers auto_docstring
|
||||
def safe_auto_docstring(func=None, **kwargs):
|
||||
"""Auto docstring decorator that handles Python 3.10+ UnionType gracefully."""
|
||||
|
||||
def decorator(f):
|
||||
try:
|
||||
return auto_docstring(f, **kwargs) if kwargs else auto_docstring(f)
|
||||
except (AttributeError, TypeError):
|
||||
# If auto_docstring fails due to UnionType, just return the function unchanged
|
||||
return f
|
||||
|
||||
if func is None:
|
||||
# Called with arguments, return the decorator
|
||||
return decorator
|
||||
else:
|
||||
# Called without arguments, apply directly
|
||||
return decorator(func)
|
||||
|
||||
|
||||
class GemmaRMSNorm(nn.Module):
|
||||
def __init__(self, dim: int, eps: float = 1e-6, cond_dim: int | None = None):
|
||||
super().__init__()
|
||||
self.eps = eps
|
||||
self.dim = dim
|
||||
self.cond_dim = cond_dim
|
||||
|
||||
# Dense layer for adaptive normalization (if cond_dim is provided)
|
||||
if cond_dim is not None:
|
||||
# self.dense = nn.Linear(cond_dim, dim * 3, bias=True, dtype=torch.bfloat16)
|
||||
self.dense = nn.Linear(cond_dim, dim * 3, bias=True)
|
||||
# Initialize with zeros (matches source implementation)
|
||||
nn.init.zeros_(self.dense.weight)
|
||||
else:
|
||||
self.weight = nn.Parameter(torch.zeros(dim, dtype=torch.bfloat16))
|
||||
self.dense = None
|
||||
|
||||
def _norm(self, x):
|
||||
# Compute variance in float32 (like the source implementation)
|
||||
var = torch.mean(torch.square(x.float()), dim=-1, keepdim=True)
|
||||
# Compute normalization in float32
|
||||
normed_inputs = x * torch.rsqrt(var + self.eps)
|
||||
return normed_inputs
|
||||
|
||||
def forward(self, x, cond=None):
|
||||
dtype = x.dtype # original dtype, could be half-precision
|
||||
normed_inputs = self._norm(x)
|
||||
|
||||
if cond is None or self.dense is None:
|
||||
# regular RMSNorm
|
||||
# scale by learned parameter in float32 (matches source implementation)
|
||||
normed_inputs = normed_inputs * (1.0 + self.weight.float())
|
||||
return normed_inputs.to(dtype), None # return in original dtype with None gate
|
||||
|
||||
# adaptive RMSNorm (if cond is provided and dense layer exists)
|
||||
if cond.shape[-1] != self.cond_dim:
|
||||
raise ValueError(f"Expected cond dimension {self.cond_dim}, got {cond.shape[-1]}")
|
||||
|
||||
# self.dense.to(dtype=torch.bfloat16).to(dtype=torch.float32)
|
||||
modulation = self.dense(cond)
|
||||
# Reshape modulation to broadcast properly: [batch, 1, features] for [batch, seq, features]
|
||||
if len(x.shape) == 3: # [batch, seq, features]
|
||||
modulation = modulation.unsqueeze(1)
|
||||
|
||||
scale, shift, gate = torch.chunk(modulation, 3, dim=-1)
|
||||
|
||||
# Apply adaptive normalization: use model weight dtype to ensure compatibility
|
||||
# model_dtype = self.dense.weight.dtype # Use the model's dtype (bfloat16)
|
||||
# scale = scale.to(model_dtype)
|
||||
# shift = shift.to(model_dtype)
|
||||
# gate = gate.to(model_dtype)
|
||||
# normed_inputs = normed_inputs.to(model_dtype) # Convert normed_inputs to model dtype
|
||||
|
||||
normed_inputs = normed_inputs * (1 + scale.to(torch.float32)) + shift.to(torch.float32)
|
||||
|
||||
return normed_inputs.to(dtype), gate.to(dtype)
|
||||
|
||||
def extra_repr(self):
|
||||
repr_str = f"{tuple(self.weight.shape)}, eps={self.eps}"
|
||||
if self.dense is not None:
|
||||
repr_str += f", adaptive=True, cond_dim={self.cond_dim}"
|
||||
return repr_str
|
||||
|
||||
|
||||
class GemmaMLP(nn.Module):
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.hidden_size = config.hidden_size
|
||||
self.intermediate_size = config.intermediate_size
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
||||
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[config.hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
|
||||
return down_proj
|
||||
|
||||
|
||||
class GemmaRotaryEmbedding(nn.Module):
|
||||
def __init__(self, config: GemmaConfig, device=None):
|
||||
super().__init__()
|
||||
# BC: "rope_type" was originally "type"
|
||||
if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
|
||||
self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
|
||||
else:
|
||||
self.rope_type = "default"
|
||||
self.max_seq_len_cached = config.max_position_embeddings
|
||||
self.original_max_seq_len = config.max_position_embeddings
|
||||
|
||||
self.config = config
|
||||
self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
|
||||
|
||||
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
|
||||
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
||||
self.original_inv_freq = self.inv_freq
|
||||
|
||||
@torch.no_grad()
|
||||
@dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
|
||||
def forward(self, x, position_ids):
|
||||
inv_freq_expanded = (
|
||||
self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
|
||||
)
|
||||
position_ids_expanded = position_ids[:, None, :].float()
|
||||
|
||||
device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
|
||||
with torch.autocast(device_type=device_type, enabled=False): # Force float32
|
||||
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
|
||||
emb = torch.cat((freqs, freqs), dim=-1)
|
||||
cos = emb.cos() * self.attention_scaling
|
||||
sin = emb.sin() * self.attention_scaling
|
||||
|
||||
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
|
||||
|
||||
|
||||
def rotate_half(x):
|
||||
"""Rotates half the hidden dims of the input."""
|
||||
x1 = x[..., : x.shape[-1] // 2]
|
||||
x2 = x[..., x.shape[-1] // 2 :]
|
||||
return torch.cat((-x2, x1), dim=-1)
|
||||
|
||||
|
||||
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
"""Applies Rotary Position Embedding to the query and key tensors.
|
||||
|
||||
Args:
|
||||
q (`torch.Tensor`): The query tensor.
|
||||
k (`torch.Tensor`): The key tensor.
|
||||
cos (`torch.Tensor`): The cosine part of the rotary embedding.
|
||||
sin (`torch.Tensor`): The sine part of the rotary embedding.
|
||||
position_ids (`torch.Tensor`, *optional*):
|
||||
Deprecated and unused.
|
||||
unsqueeze_dim (`int`, *optional*, defaults to 1):
|
||||
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
|
||||
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
|
||||
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
|
||||
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
|
||||
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
|
||||
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
|
||||
Returns:
|
||||
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
|
||||
"""
|
||||
cos = cos.unsqueeze(unsqueeze_dim)
|
||||
sin = sin.unsqueeze(unsqueeze_dim)
|
||||
q_embed = (q * cos) + (rotate_half(q) * sin)
|
||||
k_embed = (k * cos) + (rotate_half(k) * sin)
|
||||
return q_embed, k_embed
|
||||
|
||||
|
||||
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
||||
"""
|
||||
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
||||
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
||||
"""
|
||||
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
||||
if n_rep == 1:
|
||||
return hidden_states
|
||||
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
||||
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
||||
|
||||
|
||||
def _gated_residual(x, y, gate):
|
||||
"""
|
||||
Applies gated residual connection with optional gate parameter.
|
||||
|
||||
Args:
|
||||
x: Input tensor (residual)
|
||||
y: Output tensor to be added
|
||||
gate: Optional gate tensor to modulate the addition
|
||||
|
||||
Returns:
|
||||
x + y if gate is None, otherwise x + y * gate
|
||||
"""
|
||||
if x is None and y is None:
|
||||
return None
|
||||
if x is None or y is None:
|
||||
return x if x is not None else y
|
||||
if gate is None:
|
||||
return x + y
|
||||
return x + y * gate
|
||||
|
||||
|
||||
def eager_attention_forward(
|
||||
module: nn.Module,
|
||||
query: torch.Tensor,
|
||||
key: torch.Tensor,
|
||||
value: torch.Tensor,
|
||||
attention_mask: torch.Tensor | None,
|
||||
scaling: float,
|
||||
dropout: float = 0.0,
|
||||
**kwargs,
|
||||
):
|
||||
key_states = repeat_kv(key, module.num_key_value_groups)
|
||||
value_states = repeat_kv(value, module.num_key_value_groups)
|
||||
|
||||
attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
|
||||
if attention_mask is not None:
|
||||
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
|
||||
attn_weights = attn_weights + causal_mask
|
||||
|
||||
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
|
||||
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
|
||||
attn_output = torch.matmul(attn_weights, value_states)
|
||||
attn_output = attn_output.transpose(1, 2).contiguous()
|
||||
|
||||
return attn_output, attn_weights
|
||||
|
||||
|
||||
class GemmaAttention(nn.Module):
|
||||
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
||||
|
||||
def __init__(self, config: GemmaConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.layer_idx = layer_idx
|
||||
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
|
||||
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
|
||||
self.scaling = self.head_dim**-0.5
|
||||
self.attention_dropout = config.attention_dropout
|
||||
self.is_causal = True
|
||||
|
||||
self.q_proj = nn.Linear(
|
||||
config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
|
||||
)
|
||||
self.k_proj = nn.Linear(
|
||||
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
|
||||
)
|
||||
self.v_proj = nn.Linear(
|
||||
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
|
||||
)
|
||||
self.o_proj = nn.Linear(
|
||||
config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
position_embeddings: tuple[torch.Tensor, torch.Tensor],
|
||||
attention_mask: torch.Tensor | None,
|
||||
past_key_value: Cache | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
use_cache: bool = False,
|
||||
**kwargs: Unpack[FlashAttentionKwargs],
|
||||
) -> tuple[torch.Tensor, torch.Tensor | None, tuple[torch.Tensor] | None]:
|
||||
input_shape = hidden_states.shape[:-1]
|
||||
hidden_shape = (*input_shape, -1, self.head_dim)
|
||||
|
||||
query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
|
||||
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
|
||||
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
|
||||
|
||||
cos, sin = position_embeddings
|
||||
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
|
||||
|
||||
# Use cache if provided
|
||||
if past_key_value is not None:
|
||||
if use_cache:
|
||||
# sin and cos are specific to RoPE models; cache_position needed for the static cache
|
||||
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
|
||||
key_states, value_states = past_key_value.update(
|
||||
key_states, value_states, self.layer_idx, cache_kwargs
|
||||
)
|
||||
else:
|
||||
key_states = torch.cat([past_key_value[self.layer_idx][0], key_states], dim=2)
|
||||
value_states = torch.cat([past_key_value[self.layer_idx][1], value_states], dim=2)
|
||||
|
||||
attention_interface: Callable = eager_attention_forward
|
||||
if self.config._attn_implementation != "eager":
|
||||
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
|
||||
|
||||
attn_output, attn_weights = attention_interface(
|
||||
self,
|
||||
query_states,
|
||||
key_states,
|
||||
value_states,
|
||||
attention_mask,
|
||||
dropout=0.0 if not self.training else self.attention_dropout,
|
||||
scaling=self.scaling,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
|
||||
attn_output = self.o_proj(attn_output)
|
||||
return attn_output, attn_weights
|
||||
|
||||
|
||||
class GemmaDecoderLayer(GradientCheckpointingLayer):
|
||||
def __init__(self, config: GemmaConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.self_attn = GemmaAttention(config=config, layer_idx=layer_idx)
|
||||
|
||||
self.mlp = GemmaMLP(config)
|
||||
cond_dim = getattr(config, "adarms_cond_dim", None) if getattr(config, "use_adarms", False) else None
|
||||
self.input_layernorm = GemmaRMSNorm(config.hidden_size, eps=config.rms_norm_eps, cond_dim=cond_dim)
|
||||
self.post_attention_layernorm = GemmaRMSNorm(
|
||||
config.hidden_size, eps=config.rms_norm_eps, cond_dim=cond_dim
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_value: Cache | None = None,
|
||||
output_attentions: bool | None = False,
|
||||
use_cache: bool | None = False,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
position_embeddings: None
|
||||
| (tuple[torch.Tensor, torch.Tensor]) = None, # necessary, but kept here for BC
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
**kwargs: Unpack[FlashAttentionKwargs],
|
||||
) -> tuple[torch.FloatTensor, tuple[torch.FloatTensor, torch.FloatTensor] | None]:
|
||||
residual = hidden_states
|
||||
hidden_states, gate = self.input_layernorm(hidden_states, adarms_cond)
|
||||
|
||||
# Self Attention
|
||||
hidden_states, self_attn_weights = self.self_attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
cache_position=cache_position,
|
||||
position_embeddings=position_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
hidden_states = _gated_residual(residual, hidden_states, gate)
|
||||
|
||||
# Fully Connected
|
||||
residual = hidden_states
|
||||
hidden_states, gate = self.post_attention_layernorm(hidden_states, adarms_cond)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = _gated_residual(residual, hidden_states, gate)
|
||||
|
||||
outputs = (hidden_states,)
|
||||
if output_attentions:
|
||||
outputs += (self_attn_weights,)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class GemmaPreTrainedModel(PreTrainedModel):
|
||||
config_class = GemmaConfig
|
||||
base_model_prefix = "model"
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ["GemmaDecoderLayer"]
|
||||
_skip_keys_device_placement = ["past_key_values"]
|
||||
_supports_flash_attn_3 = True
|
||||
_supports_flash_attn_2 = True
|
||||
_supports_sdpa = True
|
||||
_supports_flex_attn = True
|
||||
_supports_cache_class = True
|
||||
_supports_quantized_cache = True
|
||||
_supports_static_cache = True
|
||||
_supports_attention_backend = True
|
||||
|
||||
def _init_weights(self, module):
|
||||
std = self.config.initializer_range
|
||||
if isinstance(module, nn.Linear):
|
||||
module.weight.data.normal_(mean=0.0, std=std)
|
||||
if module.bias is not None:
|
||||
module.bias.data.zero_()
|
||||
elif isinstance(module, nn.Embedding):
|
||||
module.weight.data.normal_(mean=0.0, std=std)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
elif isinstance(module, GemmaRMSNorm):
|
||||
if hasattr(module, "weight"):
|
||||
module.weight.data.fill_(1.0)
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class GemmaModel(GemmaPreTrainedModel):
|
||||
def __init__(self, config: GemmaConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList(
|
||||
[GemmaDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
||||
)
|
||||
|
||||
cond_dim = getattr(config, "adarms_cond_dim", None) if getattr(config, "use_adarms", False) else None
|
||||
self.norm = GemmaRMSNorm(config.hidden_size, eps=config.rms_norm_eps, cond_dim=cond_dim)
|
||||
self.rotary_emb = GemmaRotaryEmbedding(config=config)
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embed_tokens = value
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor | None = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: Cache | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
**kwargs: Unpack[FlashAttentionKwargs],
|
||||
) -> BaseModelOutputWithPast:
|
||||
"""
|
||||
adarms_cond (`torch.Tensor` of shape `(batch_size, cond_dim)`, *optional*):
|
||||
Condition for ADARMS.
|
||||
"""
|
||||
output_attentions = (
|
||||
output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
||||
|
||||
if (input_ids is None) ^ (inputs_embeds is not None):
|
||||
raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
|
||||
|
||||
if self.gradient_checkpointing and self.training and use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embed_tokens(input_ids)
|
||||
|
||||
if use_cache and past_key_values is None:
|
||||
past_key_values = DynamicCache()
|
||||
|
||||
if cache_position is None:
|
||||
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
|
||||
cache_position = torch.arange(
|
||||
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
|
||||
)
|
||||
|
||||
if position_ids is None:
|
||||
position_ids = cache_position.unsqueeze(0)
|
||||
|
||||
causal_mask = create_causal_mask(
|
||||
config=self.config,
|
||||
input_embeds=inputs_embeds,
|
||||
attention_mask=attention_mask,
|
||||
cache_position=cache_position,
|
||||
past_key_values=past_key_values,
|
||||
position_ids=position_ids,
|
||||
)
|
||||
|
||||
# embed positions
|
||||
hidden_states = inputs_embeds
|
||||
# Convert to bfloat16 if the first layer uses bfloat16
|
||||
if len(self.layers) > 0 and self.layers[0].self_attn.q_proj.weight.dtype == torch.bfloat16:
|
||||
hidden_states = hidden_states.to(torch.bfloat16)
|
||||
|
||||
# create position embeddings to be shared across the decoder layers
|
||||
position_embeddings = self.rotary_emb(hidden_states, position_ids)
|
||||
|
||||
# normalized
|
||||
# Gemma downcasts the below to float16, causing sqrt(3072)=55.4256 to become 55.5
|
||||
# See https://github.com/huggingface/transformers/pull/29402
|
||||
_normalizer = torch.tensor(self.config.hidden_size**0.5, dtype=hidden_states.dtype)
|
||||
# hidden_states = hidden_states * normalizer
|
||||
|
||||
# decoder layers
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_self_attns = () if output_attentions else None
|
||||
|
||||
for decoder_layer in self.layers[: self.config.num_hidden_layers]:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
layer_outputs = decoder_layer(
|
||||
hidden_states,
|
||||
attention_mask=causal_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_values,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
cache_position=cache_position,
|
||||
position_embeddings=position_embeddings,
|
||||
adarms_cond=adarms_cond,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
hidden_states = layer_outputs[0]
|
||||
|
||||
if output_attentions:
|
||||
all_self_attns += (layer_outputs[1],)
|
||||
|
||||
hidden_states, _ = self.norm(hidden_states, adarms_cond)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=past_key_values if use_cache else None,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_self_attns,
|
||||
)
|
||||
|
||||
|
||||
class KwargsForCausalLM(FlashAttentionKwargs, LossKwargs): ...
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class GemmaForCausalLM(GemmaPreTrainedModel, GenerationMixin):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
_tp_plan = {"lm_head": "colwise_rep"}
|
||||
_pp_plan = {"lm_head": (["hidden_states"], ["logits"])}
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = GemmaModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embed_tokens = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor | None = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: Cache | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
logits_to_keep: int | torch.Tensor = 0,
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
**kwargs: Unpack[KwargsForCausalLM],
|
||||
) -> CausalLMOutputWithPast:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
||||
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
||||
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
||||
|
||||
adarms_cond (`torch.Tensor` of shape `(batch_size, cond_dim)`, *optional*):
|
||||
Condition for ADARMS.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, GemmaForCausalLM
|
||||
|
||||
>>> model = GemmaForCausalLM.from_pretrained("google/gemma-7b")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
|
||||
|
||||
>>> prompt = "What is your favorite condiment?"
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> # Generate
|
||||
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
||||
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
"What is your favorite condiment?"
|
||||
```"""
|
||||
output_attentions = (
|
||||
output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
|
||||
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
||||
outputs: BaseModelOutputWithPast = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
cache_position=cache_position,
|
||||
adarms_cond=adarms_cond,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
hidden_states = outputs.last_hidden_state
|
||||
# Only compute necessary logits, and do not upcast them to float if we are not computing the loss
|
||||
slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
|
||||
logits = self.lm_head(hidden_states[:, slice_indices, :])
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(
|
||||
logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs
|
||||
)
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
|
||||
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
The Gemma Model transformer with a sequence classification head on top (linear layer).
|
||||
|
||||
[`GemmaForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
||||
(e.g. GPT-2) do.
|
||||
|
||||
Since it does classification on the last token, it requires to know the position of the last token. If a
|
||||
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
||||
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
||||
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
||||
each row of the batch).
|
||||
"""
|
||||
)
|
||||
class GemmaForSequenceClassification(GemmaPreTrainedModel):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.num_labels = config.num_labels
|
||||
self.model = GemmaModel(config)
|
||||
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embed_tokens = value
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor | None = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: Cache | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
) -> SequenceClassifierOutputWithPast:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
||||
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
||||
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
||||
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
||||
|
||||
adarms_cond (`torch.Tensor` of shape `(batch_size, cond_dim)`, *optional*):
|
||||
Condition for ADARMS.
|
||||
"""
|
||||
|
||||
transformer_outputs: BaseModelOutputWithPast = self.model(
|
||||
input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
adarms_cond=adarms_cond,
|
||||
)
|
||||
hidden_states = transformer_outputs.last_hidden_state
|
||||
logits = self.score(hidden_states)
|
||||
|
||||
if input_ids is not None:
|
||||
batch_size = input_ids.shape[0]
|
||||
else:
|
||||
batch_size = inputs_embeds.shape[0]
|
||||
|
||||
if self.config.pad_token_id is None and batch_size != 1:
|
||||
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
|
||||
if self.config.pad_token_id is None:
|
||||
last_non_pad_token = -1
|
||||
elif input_ids is not None:
|
||||
# To handle both left- and right- padding, we take the rightmost token that is not equal to pad_token_id
|
||||
non_pad_mask = (input_ids != self.config.pad_token_id).to(logits.device, torch.int32)
|
||||
token_indices = torch.arange(input_ids.shape[-1], device=logits.device, dtype=torch.int32)
|
||||
last_non_pad_token = (token_indices * non_pad_mask).argmax(-1)
|
||||
else:
|
||||
last_non_pad_token = -1
|
||||
logger.warning_once(
|
||||
f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
|
||||
"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
|
||||
)
|
||||
|
||||
pooled_logits = logits[torch.arange(batch_size, device=logits.device), last_non_pad_token]
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(
|
||||
logits=logits, labels=labels, pooled_logits=pooled_logits, config=self.config
|
||||
)
|
||||
|
||||
return SequenceClassifierOutputWithPast(
|
||||
loss=loss,
|
||||
logits=pooled_logits,
|
||||
past_key_values=transformer_outputs.past_key_values,
|
||||
hidden_states=transformer_outputs.hidden_states,
|
||||
attentions=transformer_outputs.attentions,
|
||||
)
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class GemmaForTokenClassification(GemmaPreTrainedModel):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.num_labels = config.num_labels
|
||||
self.model = GemmaModel(config)
|
||||
if getattr(config, "classifier_dropout", None) is not None:
|
||||
classifier_dropout = config.classifier_dropout
|
||||
elif getattr(config, "hidden_dropout", None) is not None:
|
||||
classifier_dropout = config.hidden_dropout
|
||||
else:
|
||||
classifier_dropout = 0.1
|
||||
self.dropout = nn.Dropout(classifier_dropout)
|
||||
self.score = nn.Linear(config.hidden_size, config.num_labels)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embed_tokens = value
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor | None = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: Cache | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
adarms_cond: torch.Tensor | None = None,
|
||||
) -> TokenClassifierOutput:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
||||
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
||||
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
||||
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
||||
|
||||
adarms_cond (`torch.Tensor` of shape `(batch_size, cond_dim)`, *optional*):
|
||||
Condition for ADARMS.
|
||||
"""
|
||||
|
||||
outputs: BaseModelOutputWithPast = self.model(
|
||||
input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
adarms_cond=adarms_cond,
|
||||
)
|
||||
sequence_output = outputs.last_hidden_state
|
||||
sequence_output = self.dropout(sequence_output)
|
||||
logits = self.score(sequence_output)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(logits, labels, self.config)
|
||||
|
||||
return TokenClassifierOutput(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
|
||||
|
||||
__all__ = [
|
||||
"GemmaModel",
|
||||
"GemmaForCausalLM",
|
||||
"GemmaForSequenceClassification",
|
||||
"GemmaForTokenClassification",
|
||||
"GemmaPreTrainedModel",
|
||||
]
|
||||
+666
@@ -0,0 +1,666 @@
|
||||
# Copyright 2024 the HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""PyTorch PaliGemmamodel."""
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
import torch.utils.checkpoint
|
||||
from torch import nn
|
||||
|
||||
from ...cache_utils import Cache, HybridCache, StaticCache
|
||||
from ...generation import GenerationMixin
|
||||
from ...modeling_flash_attention_utils import FlashAttentionKwargs
|
||||
from ...modeling_outputs import BaseModelOutputWithPast
|
||||
from ...modeling_utils import PreTrainedModel
|
||||
from ...processing_utils import Unpack
|
||||
from ...utils import (
|
||||
LossKwargs,
|
||||
ModelOutput,
|
||||
auto_docstring,
|
||||
can_return_tuple,
|
||||
is_torchdynamo_compiling,
|
||||
logging,
|
||||
)
|
||||
from ..auto import AutoModel
|
||||
from .configuration_paligemma import PaliGemmaConfig
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
# Workaround for Python 3.10+ UnionType compatibility with transformers auto_docstring
|
||||
def safe_auto_docstring(func=None, **kwargs):
|
||||
"""Auto docstring decorator that handles Python 3.10+ UnionType gracefully."""
|
||||
|
||||
def decorator(f):
|
||||
try:
|
||||
return auto_docstring(f, **kwargs) if kwargs else auto_docstring(f)
|
||||
except (AttributeError, TypeError):
|
||||
# If auto_docstring fails due to UnionType, just return the function unchanged
|
||||
return f
|
||||
|
||||
if func is None:
|
||||
# Called with arguments, return the decorator
|
||||
return decorator
|
||||
else:
|
||||
# Called without arguments, apply directly
|
||||
return decorator(func)
|
||||
|
||||
|
||||
@dataclass
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
Base class for Paligemma outputs, with hidden states and attentions.
|
||||
"""
|
||||
)
|
||||
class PaligemmaModelOutputWithPast(BaseModelOutputWithPast):
|
||||
r"""
|
||||
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
|
||||
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
||||
`(batch_size, num_heads, sequence_length, embed_size_per_head)`)
|
||||
|
||||
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
|
||||
`past_key_values` input) to speed up sequential decoding.
|
||||
image_hidden_states (`torch.FloatTensor`, *optional*):
|
||||
A `torch.FloatTensor` of size `(batch_size, num_images, sequence_length, hidden_size)`.
|
||||
image_hidden_states of the model produced by the vision encoder and after projecting the last hidden state.
|
||||
"""
|
||||
|
||||
image_hidden_states: torch.FloatTensor | None = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
Base class for PaliGemma causal language model (or autoregressive) outputs.
|
||||
"""
|
||||
)
|
||||
class PaliGemmaCausalLMOutputWithPast(ModelOutput):
|
||||
r"""
|
||||
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
|
||||
Language modeling loss (for next-token prediction).
|
||||
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.text_config.vocab_size)`):
|
||||
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
|
||||
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
|
||||
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
||||
`(batch_size, num_heads, sequence_length, embed_size_per_head)`)
|
||||
|
||||
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
|
||||
`past_key_values` input) to speed up sequential decoding.
|
||||
image_hidden_states (`torch.FloatTensor`, *optional*):
|
||||
A `torch.FloatTensor` of size `(batch_size, num_images, sequence_length, hidden_size)`.
|
||||
image_hidden_states of the model produced by the vision encoder after projecting last hidden state.
|
||||
"""
|
||||
|
||||
loss: torch.FloatTensor | None = None
|
||||
logits: torch.FloatTensor | None = None
|
||||
past_key_values: list[torch.FloatTensor] | Cache | None = None
|
||||
hidden_states: tuple[torch.FloatTensor] | None = None
|
||||
attentions: tuple[torch.FloatTensor] | None = None
|
||||
image_hidden_states: torch.FloatTensor | None = None
|
||||
|
||||
|
||||
class PaliGemmaMultiModalProjector(nn.Module):
|
||||
def __init__(self, config: PaliGemmaConfig):
|
||||
super().__init__()
|
||||
self.linear = nn.Linear(
|
||||
config.vision_config.hidden_size, config.vision_config.projection_dim, bias=True
|
||||
)
|
||||
|
||||
def forward(self, image_features):
|
||||
hidden_states = self.linear(image_features)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
@safe_auto_docstring
|
||||
class PaliGemmaPreTrainedModel(PreTrainedModel):
|
||||
config_class = PaliGemmaConfig
|
||||
base_model_prefix = ""
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ["PaliGemmaMultiModalProjector"]
|
||||
_skip_keys_device_placement = "past_key_values"
|
||||
_supports_cache_class = True
|
||||
_supports_quantized_cache = True
|
||||
_supports_static_cache = True
|
||||
_supports_flash_attn_2 = True
|
||||
_supports_sdpa = True
|
||||
_supports_flex_attn = True
|
||||
_supports_attention_backend = True
|
||||
|
||||
def _init_weights(self, module):
|
||||
# important: this ported version of PaliGemmaisn't meant for training from scratch - only
|
||||
# inference and fine-tuning
|
||||
std = getattr(self.config, "initializer_range", self.config.get_text_config().initializer_range)
|
||||
|
||||
if isinstance(module, nn.Linear):
|
||||
module.weight.data.normal_(mean=0.0, std=std)
|
||||
if module.bias is not None:
|
||||
module.bias.data.zero_()
|
||||
|
||||
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
The Base Paligemma model which consists of a vision backbone and a language model without language modeling head.,
|
||||
"""
|
||||
)
|
||||
class PaliGemmaModel(PaliGemmaPreTrainedModel):
|
||||
_checkpoint_conversion_mapping = {"language_model.model": "language_model"}
|
||||
# we are filtering the logits/labels so we shouldn't divide the loss based on num_items_in_batch
|
||||
accepts_loss_kwargs = False
|
||||
|
||||
def __init__(self, config: PaliGemmaConfig):
|
||||
super().__init__(config)
|
||||
self.vision_tower = AutoModel.from_config(config=config.vision_config)
|
||||
self.multi_modal_projector = PaliGemmaMultiModalProjector(config)
|
||||
self.vocab_size = config.text_config.vocab_size
|
||||
|
||||
language_model = AutoModel.from_config(config=config.text_config)
|
||||
self.language_model = language_model
|
||||
|
||||
self.pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else -1
|
||||
self.post_init()
|
||||
|
||||
# Copied from transformers.models.llava.modeling_llava.LlavaModel.get_input_embeddings with Llava->PaliGemma
|
||||
def get_input_embeddings(self):
|
||||
return self.language_model.get_input_embeddings()
|
||||
|
||||
# Copied from transformers.models.llava.modeling_llava.LlavaModel.set_input_embeddings with Llava->PaliGemma
|
||||
def set_input_embeddings(self, value):
|
||||
self.language_model.set_input_embeddings(value)
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.language_model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.language_model
|
||||
|
||||
def _update_causal_mask(
|
||||
self,
|
||||
attention_mask,
|
||||
token_type_ids=None,
|
||||
past_key_values=None,
|
||||
cache_position=None,
|
||||
input_tensor=None,
|
||||
is_training: bool | None = None,
|
||||
):
|
||||
if self.config.text_config._attn_implementation == "flash_attention_2":
|
||||
if attention_mask is not None and 0.0 in attention_mask:
|
||||
return attention_mask
|
||||
return None
|
||||
is_training = is_training if is_training is not None else self.training
|
||||
using_static_cache = isinstance(past_key_values, StaticCache)
|
||||
min_dtype = torch.finfo(self.dtype).min
|
||||
if input_tensor is None:
|
||||
input_tensor = attention_mask
|
||||
|
||||
inputs_lead_dim, sequence_length = input_tensor.shape[:2]
|
||||
if using_static_cache:
|
||||
target_length = past_key_values.get_max_cache_shape()
|
||||
elif isinstance(past_key_values, HybridCache):
|
||||
target_length = past_key_values.get_max_cache_shape()
|
||||
else:
|
||||
target_length = (
|
||||
attention_mask.shape[-1]
|
||||
if isinstance(attention_mask, torch.Tensor)
|
||||
else cache_position[0] + sequence_length + 1
|
||||
)
|
||||
|
||||
if attention_mask is not None and attention_mask.dim() == 4:
|
||||
# In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
|
||||
return attention_mask
|
||||
|
||||
causal_mask = torch.full(
|
||||
(sequence_length, target_length),
|
||||
fill_value=min_dtype,
|
||||
dtype=self.dtype,
|
||||
device=cache_position.device,
|
||||
)
|
||||
# Causal diagonal mask only if training, otherwise attend to the whole prefix. Training-specific attn for prefix is handled below
|
||||
if sequence_length != 1:
|
||||
if is_training:
|
||||
causal_mask = torch.triu(causal_mask, diagonal=1)
|
||||
else:
|
||||
causal_mask[:, :sequence_length] = 0.0
|
||||
|
||||
causal_mask *= torch.arange(target_length, device=cache_position.device) > cache_position.reshape(
|
||||
-1, 1
|
||||
)
|
||||
causal_mask = causal_mask[None, None, :, :].expand(inputs_lead_dim, 1, -1, -1)
|
||||
if attention_mask is not None:
|
||||
causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
|
||||
mask_length = attention_mask.shape[-1]
|
||||
|
||||
# First unmask prefix tokens during training
|
||||
if is_training:
|
||||
if token_type_ids is None:
|
||||
raise ValueError("Token type ids must be provided during training")
|
||||
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
|
||||
token_type_ids[:, None, None, :].to(causal_mask.device) == 0, 0
|
||||
)
|
||||
|
||||
# Then apply padding mask (will mask pad tokens)
|
||||
padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
|
||||
causal_mask.device
|
||||
)
|
||||
padding_mask = padding_mask == 0
|
||||
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
|
||||
padding_mask, min_dtype
|
||||
)
|
||||
|
||||
return causal_mask
|
||||
|
||||
def get_image_features(self, pixel_values: torch.FloatTensor):
|
||||
"""
|
||||
Obtains image last hidden states from the vision tower and apply multimodal projection.
|
||||
|
||||
Args:
|
||||
pixel_values (`torch.FloatTensor]` of shape `(batch_size, channels, height, width)`)
|
||||
The tensors corresponding to the input images.
|
||||
Returns:
|
||||
image_features (`torch.Tensor`): Image feature tensor of shape `(num_images, image_length, embed_dim)`).
|
||||
"""
|
||||
image_outputs = self.vision_tower(pixel_values)
|
||||
selected_image_feature = image_outputs.last_hidden_state
|
||||
image_features = self.multi_modal_projector(selected_image_feature)
|
||||
return image_features
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
pixel_values: torch.FloatTensor = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: list[torch.FloatTensor] | Cache | None = None,
|
||||
token_type_ids: torch.LongTensor | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
return_dict: bool | None = None,
|
||||
**kwargs: Unpack[FlashAttentionKwargs],
|
||||
) -> tuple | PaligemmaModelOutputWithPast:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
||||
config.text_config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
||||
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.text_config.vocab_size]`.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from PIL import Image
|
||||
>>> import requests
|
||||
>>> from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
|
||||
|
||||
>>> model = PaliGemmaForConditionalGeneration.from_pretrained("google/paligemma2-3b-mix-224")
|
||||
>>> processor = AutoProcessor.from_pretrained("google/paligemma2-3b-mix-224")
|
||||
|
||||
>>> prompt = "Where is the cat standing?"
|
||||
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
>>> image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
>>> inputs = processor(images=image, text=prompt, return_tensors="pt")
|
||||
|
||||
>>> # Generate
|
||||
>>> generate_ids = model.generate(**inputs,)
|
||||
>>> processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
"Where is the cat standing?\nsnow"
|
||||
```"""
|
||||
|
||||
if (input_ids is None) ^ (inputs_embeds is not None):
|
||||
raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
|
||||
|
||||
output_attentions = (
|
||||
output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
is_training = token_type_ids is not None and labels is not None
|
||||
|
||||
# Replace image id with PAD if the image token if OOV, to avoid index-errors
|
||||
if input_ids is not None and self.config.image_token_id >= self.vocab_size:
|
||||
special_image_mask = input_ids == self.config.image_token_id
|
||||
llm_input_ids = input_ids.clone()
|
||||
llm_input_ids[special_image_mask] = 0
|
||||
else:
|
||||
llm_input_ids = input_ids
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.get_input_embeddings()(llm_input_ids)
|
||||
|
||||
if cache_position is None:
|
||||
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
|
||||
cache_position = torch.arange(
|
||||
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
|
||||
)
|
||||
|
||||
if position_ids is None:
|
||||
position_ids = cache_position.unsqueeze(0) + 1 # Paligemma positions are 1-indexed
|
||||
|
||||
# Merge text and images
|
||||
if pixel_values is not None:
|
||||
image_features = self.get_image_features(pixel_values)
|
||||
|
||||
if input_ids is None:
|
||||
special_image_mask = inputs_embeds == self.get_input_embeddings()(
|
||||
torch.tensor(self.config.image_token_id, dtype=torch.long, device=inputs_embeds.device)
|
||||
)
|
||||
else:
|
||||
special_image_mask = (input_ids == self.config.image_token_id).unsqueeze(-1)
|
||||
special_image_mask = special_image_mask.expand_as(inputs_embeds).to(inputs_embeds.device)
|
||||
|
||||
if (
|
||||
not is_torchdynamo_compiling()
|
||||
and inputs_embeds[special_image_mask].numel() != image_features.numel()
|
||||
):
|
||||
image_tokens_in_text = (special_image_mask).sum(dim=1).sum(dim=0)[0]
|
||||
raise ValueError(
|
||||
f"Number of images does not match number of special image tokens in the input text. "
|
||||
f"Got {image_tokens_in_text} image tokens in the text but {image_features.shape[0] * image_features.shape[1]} "
|
||||
"tokens from image embeddings."
|
||||
)
|
||||
image_features = image_features.to(inputs_embeds.device, inputs_embeds.dtype)
|
||||
inputs_embeds = inputs_embeds.masked_scatter(special_image_mask, image_features)
|
||||
|
||||
causal_mask = self._update_causal_mask(
|
||||
attention_mask, token_type_ids, past_key_values, cache_position, inputs_embeds, is_training
|
||||
)
|
||||
outputs = self.language_model(
|
||||
attention_mask=causal_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=True,
|
||||
cache_position=cache_position,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
return PaligemmaModelOutputWithPast(
|
||||
last_hidden_state=outputs.last_hidden_state,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
image_hidden_states=image_features if pixel_values is not None else None,
|
||||
)
|
||||
|
||||
|
||||
class KwargsForCausalLM(FlashAttentionKwargs, LossKwargs): ...
|
||||
|
||||
|
||||
@safe_auto_docstring(
|
||||
custom_intro="""
|
||||
The Base Paligemma model which consists of a vision backbone and a language model without language modeling head.,
|
||||
"""
|
||||
)
|
||||
class PaliGemmaForConditionalGeneration(PaliGemmaPreTrainedModel, GenerationMixin):
|
||||
_checkpoint_conversion_mapping = {
|
||||
"^language_model.model": "model.language_model",
|
||||
"^vision_tower": "model.vision_tower",
|
||||
"^multi_modal_projector": "model.multi_modal_projector",
|
||||
"^language_model.lm_head": "lm_head",
|
||||
}
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config: PaliGemmaConfig):
|
||||
super().__init__(config)
|
||||
self.model = PaliGemmaModel(config)
|
||||
self.lm_head = nn.Linear(config.text_config.hidden_size, config.text_config.vocab_size, bias=False)
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.get_input_embeddings()
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.set_input_embeddings(value)
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model.set_decoder(decoder)
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model.get_decoder()
|
||||
|
||||
def get_image_features(self, pixel_values):
|
||||
return self.model.get_image_features(pixel_values)
|
||||
|
||||
# Make modules available through conditional class for BC
|
||||
@property
|
||||
def language_model(self):
|
||||
return self.model.language_model
|
||||
|
||||
@property
|
||||
def vision_tower(self):
|
||||
return self.model.vision_tower
|
||||
|
||||
@property
|
||||
def multi_modal_projector(self):
|
||||
return self.model.multi_modal_projector
|
||||
|
||||
@can_return_tuple
|
||||
@safe_auto_docstring
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
pixel_values: torch.FloatTensor = None,
|
||||
attention_mask: torch.Tensor | None = None,
|
||||
position_ids: torch.LongTensor | None = None,
|
||||
past_key_values: list[torch.FloatTensor] | Cache | None = None,
|
||||
token_type_ids: torch.LongTensor | None = None,
|
||||
cache_position: torch.LongTensor | None = None,
|
||||
inputs_embeds: torch.FloatTensor | None = None,
|
||||
labels: torch.LongTensor | None = None,
|
||||
use_cache: bool | None = None,
|
||||
output_attentions: bool | None = None,
|
||||
output_hidden_states: bool | None = None,
|
||||
return_dict: bool | None = None,
|
||||
logits_to_keep: int | torch.Tensor = 0,
|
||||
**kwargs: Unpack[KwargsForCausalLM],
|
||||
) -> tuple | PaliGemmaCausalLMOutputWithPast:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
||||
config.text_config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
||||
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.text_config.vocab_size]`.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from PIL import Image
|
||||
>>> import requests
|
||||
>>> from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
|
||||
|
||||
>>> model = PaliGemmaForConditionalGeneration.from_pretrained("google/paligemma2-3b-mix-224")
|
||||
>>> processor = AutoProcessor.from_pretrained("google/paligemma2-3b-mix-224")
|
||||
|
||||
>>> prompt = "Where is the cat standing?"
|
||||
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
>>> image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
>>> inputs = processor(images=image, text=prompt, return_tensors="pt")
|
||||
|
||||
>>> # Generate
|
||||
>>> generate_ids = model.generate(**inputs,)
|
||||
>>> processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
"Where is the cat standing?\nsnow"
|
||||
```"""
|
||||
output_attentions = (
|
||||
output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
pixel_values=pixel_values,
|
||||
token_type_ids=token_type_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
labels=labels,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=True,
|
||||
cache_position=cache_position,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
# Only compute necessary logits, and do not upcast them to float if we are not computing the loss
|
||||
slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
|
||||
logits = self.lm_head(hidden_states[:, slice_indices, :])
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(
|
||||
logits=logits, labels=labels, vocab_size=self.config.text_config.vocab_size, **kwargs
|
||||
)
|
||||
|
||||
return PaliGemmaCausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
image_hidden_states=outputs.image_hidden_states,
|
||||
)
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids,
|
||||
past_key_values=None,
|
||||
inputs_embeds=None,
|
||||
cache_position=None,
|
||||
position_ids=None,
|
||||
pixel_values=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
use_cache=True,
|
||||
logits_to_keep=None,
|
||||
labels=None,
|
||||
**kwargs,
|
||||
):
|
||||
# Overwritten -- custom `position_ids` and `pixel_values` handling
|
||||
model_inputs = super().prepare_inputs_for_generation(
|
||||
input_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
cache_position=cache_position,
|
||||
use_cache=use_cache,
|
||||
logits_to_keep=logits_to_keep,
|
||||
token_type_ids=token_type_ids,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
# position_ids in Paligemma are 1-indexed
|
||||
if model_inputs.get("position_ids") is not None:
|
||||
model_inputs["position_ids"] += 1
|
||||
# If we're in cached decoding stage, pixel values should be None because input ids do not contain special image token anymore
|
||||
# Otherwise we need pixel values to be passed to model. NOTE: use_cache=False needs pixel_values always
|
||||
if cache_position[0] == 0:
|
||||
model_inputs["pixel_values"] = pixel_values
|
||||
is_training = token_type_ids is not None and labels is not None
|
||||
if cache_position[0] == 0 and isinstance(past_key_values, HybridCache):
|
||||
input_tensor = inputs_embeds if inputs_embeds is not None else input_ids
|
||||
causal_mask = self.model._update_causal_mask(
|
||||
attention_mask, token_type_ids, past_key_values, cache_position, input_tensor, is_training
|
||||
)
|
||||
model_inputs["attention_mask"] = causal_mask
|
||||
|
||||
return model_inputs
|
||||
|
||||
@staticmethod
|
||||
# Copied from transformers.models.gptj.modeling_gptj.GPTJModel._prepare_4d_causal_attention_mask_with_cache_position
|
||||
def _prepare_4d_causal_attention_mask_with_cache_position(
|
||||
attention_mask: torch.Tensor,
|
||||
sequence_length: int,
|
||||
target_length: int,
|
||||
dtype: torch.dtype,
|
||||
cache_position: torch.Tensor,
|
||||
batch_size: int,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
|
||||
`(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
|
||||
|
||||
Args:
|
||||
attention_mask (`torch.Tensor`):
|
||||
A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
|
||||
`(batch_size, 1, query_length, key_value_length)`.
|
||||
sequence_length (`int`):
|
||||
The sequence length being processed.
|
||||
target_length (`int`):
|
||||
The target length: when generating with static cache, the mask should be as long as the static cache,
|
||||
to account for the 0 padding, the part of the cache that is not filled yet.
|
||||
dtype (`torch.dtype`):
|
||||
The dtype to use for the 4D attention mask.
|
||||
cache_position (`torch.Tensor`):
|
||||
Indices depicting the position of the input sequence tokens in the sequence.
|
||||
batch_size (`torch.Tensor`):
|
||||
Batch size.
|
||||
"""
|
||||
if attention_mask is not None and attention_mask.dim() == 4:
|
||||
# In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
|
||||
causal_mask = attention_mask
|
||||
else:
|
||||
min_dtype = torch.finfo(dtype).min
|
||||
causal_mask = torch.full(
|
||||
(sequence_length, target_length),
|
||||
fill_value=min_dtype,
|
||||
dtype=dtype,
|
||||
device=cache_position.device,
|
||||
)
|
||||
if sequence_length != 1:
|
||||
causal_mask = torch.triu(causal_mask, diagonal=1)
|
||||
causal_mask *= torch.arange(target_length, device=cache_position.device) > cache_position.reshape(
|
||||
-1, 1
|
||||
)
|
||||
causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
|
||||
if attention_mask is not None:
|
||||
causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
|
||||
mask_length = attention_mask.shape[-1]
|
||||
padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
|
||||
causal_mask.device
|
||||
)
|
||||
padding_mask = padding_mask == 0
|
||||
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
|
||||
padding_mask, min_dtype
|
||||
)
|
||||
|
||||
return causal_mask
|
||||
|
||||
|
||||
__all__ = ["PaliGemmaForConditionalGeneration", "PaliGemmaPreTrainedModel", "PaliGemmaModel"]
|
||||
@@ -0,0 +1,5 @@
|
||||
import transformers
|
||||
|
||||
|
||||
def check_whether_transformers_replace_is_installed_correctly():
|
||||
return transformers.__version__ == "4.53.2"
|
||||
+1283
File diff suppressed because it is too large
Load Diff
+201
-18
@@ -46,16 +46,19 @@ Note that in both examples, the repo/folder should contain at least `config.json
|
||||
You can learn about the CLI options for this script in the `EvalPipelineConfig` in lerobot/configs/eval.py
|
||||
"""
|
||||
|
||||
import concurrent.futures as cf
|
||||
import json
|
||||
import logging
|
||||
import threading
|
||||
import time
|
||||
from collections.abc import Callable
|
||||
from collections import defaultdict
|
||||
from collections.abc import Callable, Iterator
|
||||
from contextlib import nullcontext
|
||||
from copy import deepcopy
|
||||
from dataclasses import asdict
|
||||
from pathlib import Path
|
||||
from pprint import pformat
|
||||
from typing import TypedDict
|
||||
|
||||
import einops
|
||||
import gymnasium as gym
|
||||
@@ -68,7 +71,11 @@ from tqdm import trange
|
||||
from lerobot.configs import parser
|
||||
from lerobot.configs.eval import EvalPipelineConfig
|
||||
from lerobot.envs.factory import make_env
|
||||
from lerobot.envs.utils import add_envs_task, check_env_attributes_and_types, preprocess_observation
|
||||
from lerobot.envs.utils import (
|
||||
add_envs_task,
|
||||
check_env_attributes_and_types,
|
||||
preprocess_observation,
|
||||
)
|
||||
from lerobot.policies.factory import make_policy
|
||||
from lerobot.policies.pretrained import PreTrainedPolicy
|
||||
from lerobot.policies.utils import get_device_from_parameters
|
||||
@@ -145,7 +152,7 @@ def rollout(
|
||||
leave=False,
|
||||
)
|
||||
check_env_attributes_and_types(env)
|
||||
while not np.all(done):
|
||||
while not np.all(done) and step < max_steps:
|
||||
# Numpy array to tensor and changing dictionary keys to LeRobot policy format.
|
||||
observation = preprocess_observation(observation)
|
||||
if return_observations:
|
||||
@@ -158,10 +165,8 @@ def rollout(
|
||||
# Infer "task" from attributes of environments.
|
||||
# TODO: works with SyncVectorEnv but not AsyncVectorEnv
|
||||
observation = add_envs_task(env, observation)
|
||||
|
||||
with torch.inference_mode():
|
||||
action = policy.select_action(observation)
|
||||
|
||||
# Convert to CPU / numpy.
|
||||
action = action.to("cpu").numpy()
|
||||
assert action.ndim == 2, "Action dimensions should be (batch, action_dim)"
|
||||
@@ -179,7 +184,12 @@ def rollout(
|
||||
successes = [False] * env.num_envs
|
||||
|
||||
# Keep track of which environments are done so far.
|
||||
# Mark the episode as done if we reach the maximum step limit.
|
||||
# This ensures that the rollout always terminates cleanly at `max_steps`,
|
||||
# and allows logging/saving (e.g., videos) to be triggered consistently.
|
||||
done = terminated | truncated | done
|
||||
if step + 1 == max_steps:
|
||||
done = np.ones_like(done, dtype=bool)
|
||||
|
||||
all_actions.append(torch.from_numpy(action))
|
||||
all_rewards.append(torch.from_numpy(reward))
|
||||
@@ -402,7 +412,6 @@ def eval_policy(
|
||||
"eval_ep_s": (time.time() - start) / n_episodes,
|
||||
},
|
||||
}
|
||||
|
||||
if return_episode_data:
|
||||
info["episodes"] = episode_data
|
||||
|
||||
@@ -463,7 +472,9 @@ def eval_main(cfg: EvalPipelineConfig):
|
||||
|
||||
# Check device is available
|
||||
device = get_safe_torch_device(cfg.policy.device, log=True)
|
||||
# login to hf
|
||||
|
||||
# login()
|
||||
torch.backends.cudnn.benchmark = True
|
||||
torch.backends.cuda.matmul.allow_tf32 = True
|
||||
set_seed(cfg.seed)
|
||||
@@ -471,40 +482,212 @@ def eval_main(cfg: EvalPipelineConfig):
|
||||
logging.info(colored("Output dir:", "yellow", attrs=["bold"]) + f" {cfg.output_dir}")
|
||||
|
||||
logging.info("Making environment.")
|
||||
env = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
|
||||
envs = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
|
||||
|
||||
logging.info("Making policy.")
|
||||
|
||||
policy = make_policy(
|
||||
cfg=cfg.policy,
|
||||
env_cfg=cfg.env,
|
||||
)
|
||||
policy.eval()
|
||||
|
||||
policy.eval()
|
||||
with torch.no_grad(), torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext():
|
||||
info = eval_policy(
|
||||
env,
|
||||
info = eval_policy_all(
|
||||
envs,
|
||||
policy,
|
||||
cfg.eval.n_episodes,
|
||||
max_episodes_rendered=10,
|
||||
videos_dir=Path(cfg.output_dir) / "videos",
|
||||
start_seed=cfg.seed,
|
||||
max_parallel_tasks=cfg.env.max_parallel_tasks,
|
||||
verbose=False,
|
||||
)
|
||||
print(info["aggregated"])
|
||||
print("Overall Aggregated Metrics:")
|
||||
print(info["overall"]["aggregated"])
|
||||
|
||||
# Print per-suite stats
|
||||
for task_group, task_group_info in info.items():
|
||||
if task_group == "overall":
|
||||
continue # Skip the overall stats since we already printed it
|
||||
print(f"\nAggregated Metrics for {task_group}:")
|
||||
print(task_group_info["aggregated"])
|
||||
# Close all vec envs
|
||||
for _suite, task_map in envs.items():
|
||||
for _vec in task_map.values():
|
||||
_vec.close()
|
||||
# Save info
|
||||
with open(Path(cfg.output_dir) / "eval_info.json", "w") as f:
|
||||
json.dump(info, f, indent=2)
|
||||
|
||||
env.close()
|
||||
|
||||
logging.info("End of eval")
|
||||
|
||||
|
||||
def main():
|
||||
init_logging()
|
||||
eval_main()
|
||||
# ---- typed payload returned by one task eval ----
|
||||
class TaskMetrics(TypedDict):
|
||||
sum_rewards: list[float]
|
||||
max_rewards: list[float]
|
||||
successes: list[bool]
|
||||
video_paths: list[str]
|
||||
|
||||
|
||||
ACC_KEYS = ("sum_rewards", "max_rewards", "successes", "video_paths")
|
||||
|
||||
|
||||
def eval_policy_all(
|
||||
envs: dict[str, dict[int, gym.vector.VectorEnv]],
|
||||
policy: PreTrainedPolicy,
|
||||
n_episodes: int,
|
||||
max_episodes_rendered: int = 0,
|
||||
videos_dir: Path | None = None,
|
||||
return_episode_data: bool = False,
|
||||
start_seed: int | None = None,
|
||||
max_parallel_tasks: int = 5,
|
||||
verbose: bool = True,
|
||||
) -> dict:
|
||||
"""
|
||||
Evaluate a policy over a dict-of-dicts of vectorized envs:
|
||||
envs[suite_name][task_id] -> gym.vector.VectorEnv
|
||||
Returns a dict with per-suite aggregates and an 'overall' block.
|
||||
"""
|
||||
global_start = time.time()
|
||||
|
||||
# inner: evaluate a single (suite, task)
|
||||
def eval_one(
|
||||
task_group: str,
|
||||
task_id: int,
|
||||
env: gym.vector.VectorEnv,
|
||||
*,
|
||||
policy: PreTrainedPolicy,
|
||||
n_episodes: int,
|
||||
max_episodes_rendered: int,
|
||||
videos_dir: Path | None,
|
||||
return_episode_data: bool,
|
||||
start_seed: int | None,
|
||||
) -> TaskMetrics:
|
||||
"""Evaluates one task_id of one suite using the provided vec env."""
|
||||
if verbose:
|
||||
print(f"Evaluating: task_group={task_group}, task_id={task_id} ...")
|
||||
|
||||
task_videos_dir = None
|
||||
if videos_dir is not None:
|
||||
task_videos_dir = videos_dir / f"{task_group}_{task_id}"
|
||||
task_videos_dir.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
task_result = eval_policy(
|
||||
env=env,
|
||||
policy=policy,
|
||||
n_episodes=n_episodes,
|
||||
max_episodes_rendered=max_episodes_rendered,
|
||||
videos_dir=task_videos_dir,
|
||||
return_episode_data=return_episode_data,
|
||||
start_seed=start_seed,
|
||||
)
|
||||
|
||||
per_episode = task_result["per_episode"]
|
||||
return TaskMetrics(
|
||||
sum_rewards=[ep["sum_reward"] for ep in per_episode],
|
||||
max_rewards=[ep["max_reward"] for ep in per_episode],
|
||||
successes=[ep["success"] for ep in per_episode],
|
||||
video_paths=task_result.get("video_paths", []),
|
||||
)
|
||||
|
||||
# result producer: sequential or threaded, same consumer
|
||||
def iter_task_results() -> Iterator[tuple[str, int, TaskMetrics]]:
|
||||
if max_parallel_tasks == 1:
|
||||
for task_group, tasks in envs.items():
|
||||
for task_id, vec in tasks.items():
|
||||
yield (
|
||||
task_group,
|
||||
task_id,
|
||||
eval_one(
|
||||
task_group,
|
||||
task_id,
|
||||
vec,
|
||||
policy=policy,
|
||||
n_episodes=n_episodes,
|
||||
max_episodes_rendered=max_episodes_rendered,
|
||||
videos_dir=videos_dir,
|
||||
return_episode_data=return_episode_data,
|
||||
start_seed=start_seed,
|
||||
),
|
||||
)
|
||||
else:
|
||||
with cf.ThreadPoolExecutor(max_workers=max_parallel_tasks) as executor:
|
||||
fut2key: dict[cf.Future, tuple[str, int]] = {}
|
||||
for task_group, tasks in envs.items():
|
||||
for task_id, vec in tasks.items():
|
||||
fut = executor.submit(
|
||||
eval_one,
|
||||
task_group,
|
||||
task_id,
|
||||
vec,
|
||||
policy=policy,
|
||||
n_episodes=n_episodes,
|
||||
max_episodes_rendered=max_episodes_rendered,
|
||||
videos_dir=videos_dir,
|
||||
return_episode_data=return_episode_data,
|
||||
start_seed=start_seed,
|
||||
)
|
||||
fut2key[fut] = (task_group, task_id)
|
||||
for fut in cf.as_completed(fut2key):
|
||||
task_group, task_id = fut2key[fut]
|
||||
yield task_group, task_id, fut.result()
|
||||
|
||||
# single accumulator path on the main thread
|
||||
group_acc: dict[str, dict[str, list]] = defaultdict(lambda: {k: [] for k in ACC_KEYS})
|
||||
overall: dict[str, list] = {k: [] for k in ACC_KEYS}
|
||||
|
||||
for task_group, task_id, metrics in iter_task_results():
|
||||
acc = group_acc[task_group]
|
||||
for k in ACC_KEYS:
|
||||
acc[k].extend(metrics[k])
|
||||
overall[k].extend(metrics[k])
|
||||
|
||||
# build outputs
|
||||
results: dict[str, dict] = {}
|
||||
for task_group, data in group_acc.items():
|
||||
suite_rewards = data["sum_rewards"]
|
||||
suite_max = data["max_rewards"]
|
||||
suite_succ = data["successes"]
|
||||
suite_vids = data["video_paths"]
|
||||
|
||||
suite_eval_s = time.time() - global_start
|
||||
suite_eval_ep_s = suite_eval_s / max(1, len(suite_rewards))
|
||||
|
||||
results[task_group] = {
|
||||
"aggregated": {
|
||||
"avg_sum_reward": float(np.nanmean(suite_rewards)) if suite_rewards else float("nan"),
|
||||
"avg_max_reward": float(np.nanmean(suite_max)) if suite_max else float("nan"),
|
||||
"pc_success": float(np.nanmean(suite_succ) * 100) if suite_succ else float("nan"),
|
||||
"eval_s": suite_eval_s,
|
||||
"eval_ep_s": suite_eval_ep_s,
|
||||
},
|
||||
"video_paths": suite_vids,
|
||||
"episodes": None,
|
||||
}
|
||||
|
||||
global_eval_s = time.time() - global_start
|
||||
global_eval_ep_s = global_eval_s / max(1, len(overall["sum_rewards"]))
|
||||
results["overall"] = {
|
||||
"aggregated": {
|
||||
"avg_sum_reward": float(np.nanmean(overall["sum_rewards"]))
|
||||
if overall["sum_rewards"]
|
||||
else float("nan"),
|
||||
"avg_max_reward": float(np.nanmean(overall["max_rewards"]))
|
||||
if overall["max_rewards"]
|
||||
else float("nan"),
|
||||
"pc_success": float(np.nanmean(overall["successes"]) * 100)
|
||||
if overall["successes"]
|
||||
else float("nan"),
|
||||
"eval_s": global_eval_s,
|
||||
"eval_ep_s": global_eval_ep_s,
|
||||
},
|
||||
"video_paths": overall["video_paths"],
|
||||
"episodes": None,
|
||||
}
|
||||
return results
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
init_logging()
|
||||
eval_main()
|
||||
|
||||
@@ -30,11 +30,12 @@ from lerobot.datasets.factory import make_dataset
|
||||
from lerobot.datasets.sampler import EpisodeAwareSampler
|
||||
from lerobot.datasets.utils import cycle
|
||||
from lerobot.envs.factory import make_env
|
||||
from lerobot.envs.utils import close_envs
|
||||
from lerobot.optim.factory import make_optimizer_and_scheduler
|
||||
from lerobot.policies.factory import make_policy
|
||||
from lerobot.policies.pretrained import PreTrainedPolicy
|
||||
from lerobot.policies.utils import get_device_from_parameters
|
||||
from lerobot.scripts.eval import eval_policy
|
||||
from lerobot.scripts.eval import eval_policy_all
|
||||
from lerobot.utils.logging_utils import AverageMeter, MetricsTracker
|
||||
from lerobot.utils.random_utils import set_seed
|
||||
from lerobot.utils.train_utils import (
|
||||
@@ -126,7 +127,6 @@ def train(cfg: TrainPipelineConfig):
|
||||
|
||||
logging.info("Creating dataset")
|
||||
dataset = make_dataset(cfg)
|
||||
|
||||
# Create environment used for evaluating checkpoints during training on simulation data.
|
||||
# On real-world data, no need to create an environment as evaluations are done outside train.py,
|
||||
# using the eval.py instead, with gym_dora environment and dora-rs.
|
||||
@@ -140,7 +140,6 @@ def train(cfg: TrainPipelineConfig):
|
||||
cfg=cfg.policy,
|
||||
ds_meta=dataset.meta,
|
||||
)
|
||||
|
||||
logging.info("Creating optimizer and scheduler")
|
||||
optimizer, lr_scheduler = make_optimizer_and_scheduler(cfg, policy)
|
||||
grad_scaler = GradScaler(device.type, enabled=cfg.policy.use_amp)
|
||||
@@ -186,7 +185,6 @@ def train(cfg: TrainPipelineConfig):
|
||||
dl_iter = cycle(dataloader)
|
||||
|
||||
policy.train()
|
||||
|
||||
train_metrics = {
|
||||
"loss": AverageMeter("loss", ":.3f"),
|
||||
"grad_norm": AverageMeter("grdn", ":.3f"),
|
||||
@@ -204,7 +202,6 @@ def train(cfg: TrainPipelineConfig):
|
||||
start_time = time.perf_counter()
|
||||
batch = next(dl_iter)
|
||||
train_tracker.dataloading_s = time.perf_counter() - start_time
|
||||
|
||||
for key in batch:
|
||||
if isinstance(batch[key], torch.Tensor):
|
||||
batch[key] = batch[key].to(device, non_blocking=device.type == "cuda")
|
||||
@@ -252,15 +249,27 @@ def train(cfg: TrainPipelineConfig):
|
||||
torch.no_grad(),
|
||||
torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext(),
|
||||
):
|
||||
eval_info = eval_policy(
|
||||
eval_env,
|
||||
eval_info = eval_policy_all(
|
||||
eval_env, # dict[suite][task_id] -> vec_env
|
||||
policy,
|
||||
cfg.eval.n_episodes,
|
||||
videos_dir=cfg.output_dir / "eval" / f"videos_step_{step_id}",
|
||||
videos_dir=videos_dir,
|
||||
max_episodes_rendered=4,
|
||||
start_seed=cfg.seed,
|
||||
max_parallel_tasks=cfg.env.max_parallel_tasks,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
# overall metrics (suite-agnostic)
|
||||
aggregated = eval_info["overall"]["aggregated"]
|
||||
|
||||
# optional: per-suite logging
|
||||
for suite, suite_info in eval_info.items():
|
||||
if suite == "overall":
|
||||
continue
|
||||
logging.info("Suite %s aggregated: %s", suite, suite_info["aggregated"])
|
||||
|
||||
# meters/tracker
|
||||
eval_metrics = {
|
||||
"avg_sum_reward": AverageMeter("∑rwrd", ":.3f"),
|
||||
"pc_success": AverageMeter("success", ":.1f"),
|
||||
@@ -269,17 +278,16 @@ def train(cfg: TrainPipelineConfig):
|
||||
eval_tracker = MetricsTracker(
|
||||
cfg.batch_size, dataset.num_frames, dataset.num_episodes, eval_metrics, initial_step=step
|
||||
)
|
||||
eval_tracker.eval_s = eval_info["aggregated"].pop("eval_s")
|
||||
eval_tracker.avg_sum_reward = eval_info["aggregated"].pop("avg_sum_reward")
|
||||
eval_tracker.pc_success = eval_info["aggregated"].pop("pc_success")
|
||||
logging.info(eval_tracker)
|
||||
eval_tracker.eval_s = aggregated.get("eval_s", 0.0)
|
||||
eval_tracker.avg_sum_reward = aggregated.get("avg_sum_reward", float("nan"))
|
||||
eval_tracker.pc_success = aggregated.get("pc_success", float("nan"))
|
||||
if wandb_logger:
|
||||
wandb_log_dict = {**eval_tracker.to_dict(), **eval_info}
|
||||
wandb_logger.log_dict(wandb_log_dict, step, mode="eval")
|
||||
wandb_logger.log_video(eval_info["video_paths"][0], step, mode="eval")
|
||||
|
||||
if eval_env:
|
||||
eval_env.close()
|
||||
close_envs(eval_env)
|
||||
logging.info("End of training")
|
||||
|
||||
if cfg.policy.push_to_hub:
|
||||
|
||||
@@ -0,0 +1,226 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
"""Test script to verify PI0.5 (pi05) support in PI0OpenPI policy."""
|
||||
|
||||
import torch
|
||||
|
||||
from lerobot.policies.pi0_openpi.configuration_pi0openpi import PI0OpenPIConfig
|
||||
from lerobot.policies.pi0_openpi.modeling_pi0openpi import PI0OpenPIPolicy
|
||||
from lerobot.policies.pi05_openpi import PI05OpenPIConfig, PI05OpenPIPolicy
|
||||
|
||||
|
||||
def test_pi05_model_architecture():
|
||||
"""Test that pi05=True creates the correct model architecture."""
|
||||
print("Testing PI0.5 model architecture...")
|
||||
|
||||
# Create config
|
||||
config = PI05OpenPIConfig(
|
||||
action_dim=7,
|
||||
state_dim=14,
|
||||
dtype="float32",
|
||||
)
|
||||
|
||||
# Verify tokenizer max length is set correctly
|
||||
assert config.tokenizer_max_length == 200, (
|
||||
f"Expected tokenizer_max_length=200 for pi05, got {config.tokenizer_max_length}"
|
||||
)
|
||||
print(f"✓ Tokenizer max length correctly set to {config.tokenizer_max_length}")
|
||||
|
||||
# Verify discrete_state_input defaults to pi05
|
||||
assert config.discrete_state_input == True, ( # noqa: E712
|
||||
f"Expected discrete_state_input=True for pi05, got {config.discrete_state_input}"
|
||||
)
|
||||
print(f"✓ discrete_state_input correctly defaults to pi05 value: {config.discrete_state_input}")
|
||||
|
||||
# Create dummy dataset stats
|
||||
dataset_stats = {
|
||||
"observation.state": {
|
||||
"mean": torch.zeros(14),
|
||||
"std": torch.ones(14),
|
||||
},
|
||||
"action": {
|
||||
"mean": torch.zeros(7),
|
||||
"std": torch.ones(7),
|
||||
},
|
||||
}
|
||||
|
||||
# Instantiate policy
|
||||
policy = PI05OpenPIPolicy(config, dataset_stats)
|
||||
|
||||
# Verify pi05 model components exist
|
||||
|
||||
# Check that time_mlp layers exist (for AdaRMS conditioning)
|
||||
assert hasattr(policy.model, "time_mlp_in"), "Missing time_mlp_in layer for pi05"
|
||||
assert hasattr(policy.model, "time_mlp_out"), "Missing time_mlp_out layer for pi05"
|
||||
print("✓ Time MLP layers present for AdaRMS conditioning")
|
||||
|
||||
# Check that action_time_mlp layers don't exist (pi0 only)
|
||||
assert not hasattr(policy.model, "action_time_mlp_in"), "action_time_mlp_in should not exist in pi05 mode"
|
||||
assert not hasattr(policy.model, "action_time_mlp_out"), (
|
||||
"action_time_mlp_out should not exist in pi05 mode"
|
||||
)
|
||||
print("✓ Action-time MLP layers correctly absent")
|
||||
|
||||
# Check that state_proj doesn't exist in pi05 mode
|
||||
assert not hasattr(policy.model, "state_proj"), "state_proj should not exist in pi05 mode"
|
||||
print("✓ State projection layer correctly absent")
|
||||
|
||||
# Check AdaRMS configuration in the underlying model
|
||||
adarms_config = policy.model.paligemma_with_expert.paligemma.config.text_config.use_adarms
|
||||
assert adarms_config == False, f"PaliGemma should not use AdaRMS, got {adarms_config}" # noqa: E712
|
||||
|
||||
adarms_expert_config = policy.model.paligemma_with_expert.gemma_expert.config.use_adarms
|
||||
assert adarms_expert_config == True, ( # noqa: E712
|
||||
f"Action expert should use AdaRMS in pi05, got {adarms_expert_config}"
|
||||
)
|
||||
print("✓ AdaRMS correctly configured: PaliGemma=False, Expert=True")
|
||||
|
||||
return True
|
||||
|
||||
|
||||
def test_pi05_forward_pass():
|
||||
"""Test forward pass with"""
|
||||
print("\nTesting PI0.5 forward pass...")
|
||||
|
||||
# Create config
|
||||
config = PI05OpenPIConfig(
|
||||
action_dim=7,
|
||||
state_dim=14,
|
||||
dtype="float32",
|
||||
chunk_size=16, # Shorter chunk_size for testing
|
||||
n_action_steps=16, # Shorter action steps for testing
|
||||
)
|
||||
|
||||
# Create dummy dataset stats
|
||||
dataset_stats = {
|
||||
"observation.state": {
|
||||
"mean": torch.zeros(14),
|
||||
"std": torch.ones(14),
|
||||
},
|
||||
"action": {
|
||||
"mean": torch.zeros(7),
|
||||
"std": torch.ones(7),
|
||||
},
|
||||
}
|
||||
|
||||
# Instantiate policy
|
||||
policy = PI05OpenPIPolicy(config, dataset_stats)
|
||||
|
||||
# Create test batch
|
||||
batch_size = 2
|
||||
device = next(policy.parameters()).device
|
||||
batch = {
|
||||
"observation.state": torch.randn(batch_size, 14, dtype=torch.float32, device=device),
|
||||
"action": torch.randn(batch_size, config.chunk_size, 7, dtype=torch.float32, device=device),
|
||||
"observation.images.base_0_rgb": torch.rand(
|
||||
batch_size, 3, 224, 224, dtype=torch.float32, device=device
|
||||
),
|
||||
"task": ["Pick up the object"] * batch_size,
|
||||
}
|
||||
|
||||
# Test forward pass
|
||||
try:
|
||||
loss, loss_dict = policy.forward(batch)
|
||||
print(f"✓ Forward pass successful. Loss: {loss_dict['loss']:.4f}")
|
||||
assert not torch.isnan(loss), "Loss is NaN"
|
||||
assert loss.item() >= 0, "Loss should be non-negative"
|
||||
except Exception as e:
|
||||
print(f"✗ Forward pass failed: {e}")
|
||||
return False
|
||||
|
||||
# Test action prediction
|
||||
try:
|
||||
with torch.no_grad():
|
||||
action = policy.select_action(batch)
|
||||
print(f"✓ Action prediction successful. Action shape: {action.shape}")
|
||||
# When batch_size > 1, select_action returns (batch_size, action_dim)
|
||||
assert action.shape == (batch_size, 7), f"Expected action shape ({batch_size}, 7), got {action.shape}"
|
||||
assert not torch.isnan(action).any(), "Action contains NaN values"
|
||||
except Exception as e:
|
||||
print(f"✗ Action prediction failed: {e}")
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
|
||||
def test_pi0_vs_pi05_differences():
|
||||
"""Test key differences between pi0 and pi05 modes."""
|
||||
print("\nComparing PI0 vs PI0.5 architectures...")
|
||||
|
||||
# Create both configurations
|
||||
config_pi0 = PI0OpenPIConfig(action_dim=7, state_dim=14, dtype="float32")
|
||||
config_pi05 = PI05OpenPIConfig(action_dim=7, state_dim=14, dtype="float32")
|
||||
|
||||
dataset_stats = {
|
||||
"observation.state": {"mean": torch.zeros(14), "std": torch.ones(14)},
|
||||
"action": {"mean": torch.zeros(7), "std": torch.ones(7)},
|
||||
}
|
||||
|
||||
# Create both models
|
||||
policy_pi0 = PI0OpenPIPolicy(config_pi0, dataset_stats)
|
||||
policy_pi05 = PI05OpenPIPolicy(config_pi05, dataset_stats)
|
||||
|
||||
print("\nPI0 Model:")
|
||||
print(f" - Tokenizer max length: {config_pi0.tokenizer_max_length}")
|
||||
print(f" - Has state_proj: {hasattr(policy_pi0.model, 'state_proj')}")
|
||||
print(f" - Has action_time_mlp: {hasattr(policy_pi0.model, 'action_time_mlp_in')}")
|
||||
print(f" - Has time_mlp: {hasattr(policy_pi0.model, 'time_mlp_in')}")
|
||||
print(f" - Uses AdaRMS: {policy_pi0.model.paligemma_with_expert.gemma_expert.config.use_adarms}")
|
||||
|
||||
print("\nPI0.5 Model:")
|
||||
print(f" - Tokenizer max length: {config_pi05.tokenizer_max_length}")
|
||||
print(f" - discrete_state_input: {config_pi05.discrete_state_input}")
|
||||
print(f" - Has state_proj: {hasattr(policy_pi05.model, 'state_proj')}")
|
||||
print(f" - Has action_time_mlp: {hasattr(policy_pi05.model, 'action_time_mlp_in')}")
|
||||
print(f" - Has time_mlp: {hasattr(policy_pi05.model, 'time_mlp_in')}")
|
||||
print(f" - Uses AdaRMS: {policy_pi05.model.paligemma_with_expert.gemma_expert.config.use_adarms}")
|
||||
|
||||
# Count parameters
|
||||
pi0_params = sum(p.numel() for p in policy_pi0.parameters())
|
||||
pi05_params = sum(p.numel() for p in policy_pi05.parameters())
|
||||
|
||||
print("\nParameter counts:")
|
||||
print(f" - PI0: {pi0_params:,}")
|
||||
print(f" - PI0.5: {pi05_params:,}")
|
||||
print(f" - Difference: {pi0_params - pi05_params:,} (PI0.5 has fewer params due to no state embedding)")
|
||||
|
||||
return True
|
||||
|
||||
|
||||
def main():
|
||||
"""Run all PI0.5 tests."""
|
||||
print("=" * 60)
|
||||
print("PI0.5 Support Test Suite")
|
||||
print("=" * 60)
|
||||
|
||||
tests = [
|
||||
("Model Architecture", test_pi05_model_architecture),
|
||||
("Forward Pass", test_pi05_forward_pass),
|
||||
("PI0 vs PI0.5 Comparison", test_pi0_vs_pi05_differences),
|
||||
]
|
||||
|
||||
all_passed = True
|
||||
for test_name, test_func in tests:
|
||||
print(f"\n[{test_name}]")
|
||||
print("-" * 40)
|
||||
try:
|
||||
if not test_func():
|
||||
all_passed = False
|
||||
print(f"✗ {test_name} failed")
|
||||
except Exception as e:
|
||||
all_passed = False
|
||||
print(f"✗ {test_name} failed with exception: {e}")
|
||||
import traceback
|
||||
|
||||
traceback.print_exc()
|
||||
|
||||
print("\n" + "=" * 60)
|
||||
if all_passed:
|
||||
print("✅ All PI0.5 tests passed!")
|
||||
else:
|
||||
print("❌ Some tests failed.")
|
||||
print("=" * 60)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -0,0 +1,109 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
"""Test script to verify PI0OpenPI policy integration with LeRobot."""
|
||||
|
||||
import torch
|
||||
|
||||
from lerobot.policies.factory import make_policy_config
|
||||
from lerobot.policies.pi0_openpi import PI0OpenPIConfig, PI0OpenPIPolicy
|
||||
|
||||
|
||||
def test_policy_instantiation():
|
||||
"""Test basic policy instantiation."""
|
||||
print("Testing PI0OpenPI policy instantiation...")
|
||||
|
||||
# Create config
|
||||
config = PI0OpenPIConfig(action_dim=7, state_dim=14, dtype="float32")
|
||||
|
||||
# Create dummy dataset stats
|
||||
dataset_stats = {
|
||||
"observation.state": {
|
||||
"mean": torch.zeros(14),
|
||||
"std": torch.ones(14),
|
||||
},
|
||||
"action": {
|
||||
"mean": torch.zeros(7),
|
||||
"std": torch.ones(7),
|
||||
},
|
||||
}
|
||||
|
||||
# Instantiate policy
|
||||
policy = PI0OpenPIPolicy(config, dataset_stats)
|
||||
print(f"Policy created successfully: {policy.name}")
|
||||
|
||||
# Test forward pass with dummy data
|
||||
batch_size = 1
|
||||
device = policy.device if hasattr(policy, "device") else "cpu"
|
||||
batch = {
|
||||
"observation.state": torch.randn(batch_size, 14, dtype=torch.float32, device=device),
|
||||
"action": torch.randn(batch_size, config.chunk_size, 7, dtype=torch.float32, device=device),
|
||||
"observation.images.base_0_rgb": torch.rand(
|
||||
batch_size, 3, 224, 224, dtype=torch.float32, device=device
|
||||
), # Use rand for [0,1] range
|
||||
"task": ["Pick up the object"] * batch_size,
|
||||
}
|
||||
|
||||
print("\nTesting forward pass...")
|
||||
try:
|
||||
loss, loss_dict = policy.forward(batch)
|
||||
print(f"✓ Forward pass successful. Loss: {loss_dict['loss']:.4f}")
|
||||
except Exception as e:
|
||||
print(f"✗ Forward pass failed: {e}")
|
||||
return False
|
||||
|
||||
print("\nTesting action prediction...")
|
||||
try:
|
||||
with torch.no_grad():
|
||||
action = policy.select_action(batch)
|
||||
print(f"✓ Action prediction successful. Action shape: {action.shape}")
|
||||
except Exception as e:
|
||||
print(f"✗ Action prediction failed: {e}")
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
|
||||
def test_config_creation():
|
||||
"""Test policy config creation through factory."""
|
||||
print("\nTesting config creation through factory...")
|
||||
|
||||
try:
|
||||
config = make_policy_config(
|
||||
policy_type="pi0_openpi",
|
||||
action_dim=7,
|
||||
state_dim=14,
|
||||
)
|
||||
print("✓ Config created successfully through factory")
|
||||
print(f" Config type: {type(config).__name__}")
|
||||
print(f" PaliGemma variant: {config.paligemma_variant}")
|
||||
print(f" Action expert variant: {config.action_expert_variant}")
|
||||
return True
|
||||
except Exception as e:
|
||||
print(f"✗ Config creation failed: {e}")
|
||||
return False
|
||||
|
||||
|
||||
def main():
|
||||
"""Run all tests."""
|
||||
print("=" * 60)
|
||||
print("PI0OpenPI Policy Integration Test")
|
||||
print("=" * 60)
|
||||
|
||||
# Test config creation
|
||||
config_test = test_config_creation()
|
||||
|
||||
print("\n" + "-" * 60)
|
||||
|
||||
# Test policy instantiation
|
||||
policy_test = test_policy_instantiation()
|
||||
|
||||
print("\n" + "=" * 60)
|
||||
if config_test and policy_test:
|
||||
print("✓ All tests passed!")
|
||||
else:
|
||||
print("✗ Some tests failed.")
|
||||
print("=" * 60)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -0,0 +1,396 @@
|
||||
"""Test script to verify PI0OpenPI policy integration with LeRobot vs the original implementation."""
|
||||
|
||||
import os
|
||||
|
||||
import torch
|
||||
from openpi.models_pytorch import preprocessing_pytorch as openpi_preprocessing
|
||||
|
||||
# NOTE: Assumes PYTHONPATH is set to include OpenPI src as per instructions.
|
||||
from openpi.models_pytorch.pi0_pytorch import PI0Pytorch
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
from lerobot.policies.pi0_openpi import PI0OpenPIConfig, PI0OpenPIPolicy
|
||||
|
||||
DUMMY_ACTION_DIM = 32
|
||||
DUMMY_STATE_DIM = 32
|
||||
DUMMY_ACTION_HORIZON = 50
|
||||
DUMMY_MAX_TOKEN_LEN = 48 # Default for PI0 (non-pi05)
|
||||
DEVICE = "cpu" # Use CPU to avoid memory issues for testing
|
||||
|
||||
DUMMY_DATASET_STATS = {
|
||||
"observation.state": {
|
||||
"mean": torch.zeros(DUMMY_STATE_DIM),
|
||||
"std": torch.ones(DUMMY_STATE_DIM),
|
||||
},
|
||||
"action": {
|
||||
"mean": torch.zeros(DUMMY_ACTION_DIM),
|
||||
"std": torch.ones(DUMMY_ACTION_DIM),
|
||||
},
|
||||
"images": {
|
||||
"base_0_rgb": {
|
||||
"mean": torch.zeros(3, 224, 224),
|
||||
"std": torch.ones(3, 224, 224),
|
||||
},
|
||||
"left_wrist_0_rgb": {
|
||||
"mean": torch.zeros(3, 224, 224),
|
||||
"std": torch.ones(3, 224, 224),
|
||||
},
|
||||
"right_wrist_0_rgb": {
|
||||
"mean": torch.zeros(3, 224, 224),
|
||||
"std": torch.ones(3, 224, 224),
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
class PI0BaseOriginalConfig:
|
||||
action_dim: int = DUMMY_ACTION_DIM
|
||||
action_horizon: int = DUMMY_ACTION_HORIZON
|
||||
paligemma_variant: str = "gemma_2b"
|
||||
action_expert_variant: str = "gemma_300m"
|
||||
precision: str = "float32"
|
||||
pi05: bool = False
|
||||
dtype: str = "float32"
|
||||
|
||||
|
||||
def instantiate_lerobot_pi0(from_pretrained: bool = False):
|
||||
if from_pretrained:
|
||||
# Load the policy first
|
||||
policy = PI0OpenPIPolicy.from_pretrained(
|
||||
pretrained_name_or_path="pepijn223/pi0_base_fp32", strict=True
|
||||
)
|
||||
# Then reinitialize the normalization with proper stats
|
||||
from lerobot.policies.normalize import Normalize, Unnormalize
|
||||
|
||||
policy.normalize_inputs = Normalize(
|
||||
policy.config.input_features, policy.config.normalization_mapping, DUMMY_DATASET_STATS
|
||||
)
|
||||
policy.normalize_targets = Normalize(
|
||||
policy.config.output_features, policy.config.normalization_mapping, DUMMY_DATASET_STATS
|
||||
)
|
||||
policy.unnormalize_outputs = Unnormalize(
|
||||
policy.config.output_features, policy.config.normalization_mapping, DUMMY_DATASET_STATS
|
||||
)
|
||||
else:
|
||||
config = PI0OpenPIConfig(action_dim=DUMMY_ACTION_DIM, state_dim=DUMMY_STATE_DIM, dtype="float32")
|
||||
policy = PI0OpenPIPolicy(config, DUMMY_DATASET_STATS)
|
||||
policy.to(DEVICE)
|
||||
return policy
|
||||
|
||||
|
||||
def instantiate_original_pi0(from_pretrained: bool = False, model_path: str = None):
|
||||
config = PI0BaseOriginalConfig()
|
||||
policy = PI0Pytorch(config)
|
||||
|
||||
if from_pretrained:
|
||||
try:
|
||||
print("Loading converted PyTorch weights from HuggingFace Hub (pepijn223/pi0_base_fp32)...")
|
||||
|
||||
# Download the model from HuggingFace Hub
|
||||
import safetensors.torch
|
||||
from huggingface_hub import snapshot_download
|
||||
|
||||
# Download the entire repository
|
||||
if model_path and os.path.exists(model_path):
|
||||
cache_dir = model_path
|
||||
print(f"Using cached model from: {cache_dir}")
|
||||
else:
|
||||
cache_dir = snapshot_download(repo_id="pepijn223/pi0_base_fp32", repo_type="model")
|
||||
print(f"Downloaded model to: {cache_dir}")
|
||||
|
||||
# Try to load safetensors format first
|
||||
model_file = os.path.join(cache_dir, "model.safetensors")
|
||||
if os.path.exists(model_file):
|
||||
state_dict = safetensors.torch.load_file(model_file)
|
||||
print(f"Loaded {len(state_dict)} parameters from safetensors")
|
||||
else:
|
||||
raise FileNotFoundError(f"No safetensors file found in {cache_dir}")
|
||||
|
||||
# Load the state dict into the model
|
||||
missing_keys, unexpected_keys = policy.load_state_dict(state_dict, strict=False)
|
||||
|
||||
if missing_keys:
|
||||
print(f"Missing keys: {len(missing_keys)}")
|
||||
if len(missing_keys) <= 5:
|
||||
for key in missing_keys:
|
||||
print(f" - {key}")
|
||||
else:
|
||||
for key in missing_keys[:5]:
|
||||
print(f" - {key}")
|
||||
print(f" ... and {len(missing_keys) - 5} more")
|
||||
|
||||
if unexpected_keys:
|
||||
print(f"Unexpected keys: {len(unexpected_keys)}")
|
||||
if len(unexpected_keys) <= 5:
|
||||
for key in unexpected_keys:
|
||||
print(f" - {key}")
|
||||
else:
|
||||
for key in unexpected_keys[:5]:
|
||||
print(f" - {key}")
|
||||
print(f" ... and {len(unexpected_keys) - 5} more")
|
||||
|
||||
if not missing_keys and not unexpected_keys:
|
||||
print("All pretrained weights loaded successfully!")
|
||||
else:
|
||||
print("Pretrained weights loaded with some missing/unexpected keys (this may be normal)")
|
||||
|
||||
except Exception as e:
|
||||
print(f"Failed to load pretrained weights: {e}")
|
||||
print(" Using randomly initialized weights...")
|
||||
import traceback
|
||||
|
||||
traceback.print_exc()
|
||||
|
||||
policy.to(DEVICE)
|
||||
return policy
|
||||
|
||||
|
||||
def create_dummy_data():
|
||||
batch_size = 2 # Reduce batch size for testing
|
||||
device = DEVICE
|
||||
|
||||
# Use the exact same prompt for both implementations
|
||||
prompt = "Pick up the red block and place it in the bin"
|
||||
|
||||
batch = {
|
||||
"observation.state": torch.randn(batch_size, DUMMY_STATE_DIM, dtype=torch.float32, device=device),
|
||||
"action": torch.randn(
|
||||
batch_size, DUMMY_ACTION_HORIZON, DUMMY_ACTION_DIM, dtype=torch.float32, device=device
|
||||
),
|
||||
# Create images in [0, 1] range as expected by LeRobot (will be converted to [-1, 1] internally)
|
||||
"observation.images.base_0_rgb": torch.rand(
|
||||
batch_size, 3, 224, 224, dtype=torch.float32, device=device
|
||||
),
|
||||
"observation.images.left_wrist_0_rgb": torch.rand(
|
||||
batch_size, 3, 224, 224, dtype=torch.float32, device=device
|
||||
),
|
||||
"observation.images.right_wrist_0_rgb": torch.rand(
|
||||
batch_size, 3, 224, 224, dtype=torch.float32, device=device
|
||||
),
|
||||
# Add the task prompt for LeRobot - provide as list with single element to trigger expansion
|
||||
"task": [prompt],
|
||||
}
|
||||
return batch
|
||||
|
||||
|
||||
def extract_lerobot_processed_inputs(lerobot_pi0, batch):
|
||||
"""Extract the exact same processed inputs that LeRobot uses internally."""
|
||||
# Get the tokenized language from LeRobot's internal method
|
||||
lang_tokens, lang_masks = lerobot_pi0._tokenize_language(batch)
|
||||
|
||||
# Get the preprocessed images from LeRobot's internal method
|
||||
images, img_masks = lerobot_pi0._preprocess_images(batch, train=False)
|
||||
|
||||
# Create dummy token_ar_mask and token_loss_mask for original implementation
|
||||
token_ar_mask = torch.zeros_like(lang_tokens, dtype=torch.int32)
|
||||
token_loss_mask = torch.ones_like(lang_masks, dtype=torch.bool)
|
||||
|
||||
return images, img_masks, lang_tokens, lang_masks, token_ar_mask, token_loss_mask
|
||||
|
||||
|
||||
class PI0Observation:
|
||||
"""Observation class that matches the original OpenPI format."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
state,
|
||||
images,
|
||||
image_masks,
|
||||
tokenized_prompt,
|
||||
tokenized_prompt_mask,
|
||||
token_ar_mask,
|
||||
token_loss_mask,
|
||||
):
|
||||
self.state = state
|
||||
self.images = images
|
||||
self.image_masks = image_masks
|
||||
self.tokenized_prompt = tokenized_prompt
|
||||
self.tokenized_prompt_mask = tokenized_prompt_mask
|
||||
self.token_ar_mask = token_ar_mask
|
||||
self.token_loss_mask = token_loss_mask
|
||||
|
||||
|
||||
def create_original_observation_with_openpi_preprocessing(batch):
|
||||
"""Create observation object for OpenPI using OpenPI's own preprocessing."""
|
||||
batch_size = batch["observation.state"].shape[0]
|
||||
device = batch["observation.state"].device
|
||||
|
||||
# Create tokenizer for OpenPI (same as LeRobot uses)
|
||||
tokenizer = AutoTokenizer.from_pretrained("google/paligemma-3b-pt-224")
|
||||
|
||||
# Get task description
|
||||
if "task" in batch:
|
||||
tasks = batch["task"]
|
||||
if isinstance(tasks, str):
|
||||
tasks = [tasks]
|
||||
elif isinstance(tasks, list) and len(tasks) == 1:
|
||||
# Expand to batch size
|
||||
tasks = tasks * batch_size
|
||||
else:
|
||||
# Default task if not provided
|
||||
tasks = ["Pick up the object"] * batch_size
|
||||
|
||||
# Tokenize with max_length padding to match OpenPI's expected format
|
||||
tokenized = tokenizer(
|
||||
tasks,
|
||||
padding="max_length",
|
||||
padding_side="right",
|
||||
truncation=True,
|
||||
max_length=DUMMY_MAX_TOKEN_LEN,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
lang_tokens = tokenized["input_ids"].to(device)
|
||||
lang_masks = tokenized["attention_mask"].to(device, dtype=torch.bool)
|
||||
|
||||
# Create dummy token_ar_mask and token_loss_mask for OpenPI
|
||||
token_ar_mask = torch.zeros_like(lang_tokens, dtype=torch.int32)
|
||||
token_loss_mask = torch.ones_like(lang_masks, dtype=torch.bool)
|
||||
|
||||
# Convert LeRobot images format to OpenPI format (convert [0,1] to [-1,1] range)
|
||||
image_dict = {
|
||||
"base_0_rgb": batch["observation.images.base_0_rgb"] * 2.0 - 1.0,
|
||||
"left_wrist_0_rgb": batch["observation.images.left_wrist_0_rgb"] * 2.0 - 1.0,
|
||||
"right_wrist_0_rgb": batch["observation.images.right_wrist_0_rgb"] * 2.0 - 1.0,
|
||||
}
|
||||
|
||||
# Create image masks (all ones for real images)
|
||||
image_masks_dict = {}
|
||||
for key in image_dict:
|
||||
image_masks_dict[key] = torch.ones(batch_size, dtype=torch.bool, device=device)
|
||||
|
||||
# Create raw observation object (before preprocessing)
|
||||
raw_observation = PI0Observation(
|
||||
state=batch["observation.state"],
|
||||
images=image_dict,
|
||||
image_masks=image_masks_dict,
|
||||
tokenized_prompt=lang_tokens,
|
||||
tokenized_prompt_mask=lang_masks,
|
||||
token_ar_mask=token_ar_mask,
|
||||
token_loss_mask=token_loss_mask,
|
||||
)
|
||||
|
||||
# Now use OpenPI's preprocessing
|
||||
processed_obs = openpi_preprocessing.preprocess_observation_pytorch(raw_observation, train=False)
|
||||
|
||||
return processed_obs
|
||||
|
||||
|
||||
def create_original_observation_from_lerobot(lerobot_pi0, batch):
|
||||
"""Create observation object compatible with original OpenPI using the exact same inputs as LeRobot."""
|
||||
_batch_size = batch["observation.state"].shape[0]
|
||||
_device = batch["observation.state"].device
|
||||
|
||||
# Extract the exact same processed inputs that LeRobot uses
|
||||
images, img_masks, lang_tokens, lang_masks, token_ar_mask, token_loss_mask = (
|
||||
extract_lerobot_processed_inputs(lerobot_pi0, batch)
|
||||
)
|
||||
|
||||
# Convert images list to dict with original OpenPI keys
|
||||
image_dict = {
|
||||
"base_0_rgb": images[0],
|
||||
"left_wrist_0_rgb": images[1],
|
||||
"right_wrist_0_rgb": images[2],
|
||||
}
|
||||
|
||||
# Convert image masks list to dict with original OpenPI keys
|
||||
image_masks_dict = {
|
||||
"base_0_rgb": img_masks[0],
|
||||
"left_wrist_0_rgb": img_masks[1],
|
||||
"right_wrist_0_rgb": img_masks[2],
|
||||
}
|
||||
|
||||
return PI0Observation(
|
||||
state=batch["observation.state"],
|
||||
images=image_dict,
|
||||
image_masks=image_masks_dict,
|
||||
tokenized_prompt=lang_tokens,
|
||||
tokenized_prompt_mask=lang_masks,
|
||||
token_ar_mask=token_ar_mask,
|
||||
token_loss_mask=token_loss_mask,
|
||||
)
|
||||
|
||||
|
||||
def main():
|
||||
print("Initializing models...")
|
||||
lerobot_pi0 = instantiate_lerobot_pi0(from_pretrained=True) # Load pretrained LeRobot model
|
||||
original_pi0 = instantiate_original_pi0(
|
||||
from_pretrained=True
|
||||
) # Load pretrained OpenPI model from HuggingFace Hub
|
||||
|
||||
print("Creating dummy data...")
|
||||
batch = create_dummy_data()
|
||||
|
||||
# Test 1: Each model with its own preprocessing (more realistic end-to-end test)
|
||||
print("\n=== TEST 1: Each model with its own preprocessing ===")
|
||||
print("Creating observation for OpenPI using OpenPI's own preprocessing...")
|
||||
pi0_obs_openpi = create_original_observation_with_openpi_preprocessing(batch)
|
||||
|
||||
print(f"Task prompt: '{batch['task'][0]}'")
|
||||
print(f"OpenPI tokenized prompt shape: {pi0_obs_openpi.tokenized_prompt.shape}")
|
||||
print(f"OpenPI image shapes: {[img.shape for img in pi0_obs_openpi.images.values()]}")
|
||||
print(f"OpenPI state shape: {pi0_obs_openpi.state.shape}")
|
||||
|
||||
print("Testing OpenPI with own preprocessing...")
|
||||
original_pi0.eval()
|
||||
torch.manual_seed(42) # Set seed for reproducibility
|
||||
batch_size = batch["observation.state"].shape[0]
|
||||
noise_shape = (batch_size, DUMMY_ACTION_HORIZON, DUMMY_ACTION_DIM)
|
||||
fixed_noise = torch.randn(noise_shape, dtype=torch.float32, device=DEVICE)
|
||||
|
||||
with torch.no_grad():
|
||||
openpi_actions = original_pi0.sample_actions(
|
||||
device=DEVICE, observation=pi0_obs_openpi, noise=fixed_noise, num_steps=10
|
||||
)
|
||||
print(f"OpenPI (own preprocessing) Actions shape: {openpi_actions.shape}")
|
||||
print(f"OpenPI (own preprocessing) Actions mean: {openpi_actions.mean().item():.6f}")
|
||||
print(f"OpenPI (own preprocessing) Actions std: {openpi_actions.std().item():.6f}")
|
||||
|
||||
print("Testing LeRobot with own preprocessing...")
|
||||
lerobot_pi0.eval()
|
||||
torch.manual_seed(42) # Set the same seed
|
||||
with torch.no_grad():
|
||||
lerobot_actions_own = lerobot_pi0.predict_action_chunk(batch)
|
||||
print(f"LeRobot (own preprocessing) Actions shape: {lerobot_actions_own.shape}")
|
||||
print(f"LeRobot (own preprocessing) Actions mean: {lerobot_actions_own.mean().item():.6f}")
|
||||
print(f"LeRobot (own preprocessing) Actions std: {lerobot_actions_own.std().item():.6f}")
|
||||
|
||||
print("\nComparing end-to-end implementations:")
|
||||
print(f"Actions close (atol=1e-4): {torch.allclose(lerobot_actions_own, openpi_actions, atol=1e-4)}")
|
||||
print(f"Actions close (atol=1e-2): {torch.allclose(lerobot_actions_own, openpi_actions, atol=1e-2)}")
|
||||
print(f"Max absolute difference: {torch.abs(lerobot_actions_own - openpi_actions).max().item():.6f}")
|
||||
|
||||
# Test 2: Both models with LeRobot preprocessing (isolates model differences)
|
||||
print("\n=== TEST 2: Both models with LeRobot preprocessing (model comparison) ===")
|
||||
print("Creating observation for OpenPI using LeRobot's preprocessing...")
|
||||
pi0_obs_lerobot = create_original_observation_from_lerobot(lerobot_pi0, batch)
|
||||
|
||||
print("Testing OpenPI with LeRobot preprocessing...")
|
||||
torch.manual_seed(42) # Set seed for reproducibility
|
||||
with torch.no_grad():
|
||||
openpi_actions_lerobot_preproc = original_pi0.sample_actions(
|
||||
device=DEVICE, observation=pi0_obs_lerobot, noise=fixed_noise, num_steps=10
|
||||
)
|
||||
print(f"OpenPI (LeRobot preprocessing) Actions shape: {openpi_actions_lerobot_preproc.shape}")
|
||||
print(f"OpenPI (LeRobot preprocessing) Actions mean: {openpi_actions_lerobot_preproc.mean().item():.6f}")
|
||||
print(f"OpenPI (LeRobot preprocessing) Actions std: {openpi_actions_lerobot_preproc.std().item():.6f}")
|
||||
|
||||
print("\nComparing models with same preprocessing:")
|
||||
print(
|
||||
f"Actions close (atol=1e-4): {torch.allclose(lerobot_actions_own, openpi_actions_lerobot_preproc, atol=1e-4)}"
|
||||
)
|
||||
print(
|
||||
f"Actions close (atol=1e-2): {torch.allclose(lerobot_actions_own, openpi_actions_lerobot_preproc, atol=1e-2)}"
|
||||
)
|
||||
print(
|
||||
f"Max absolute difference: {torch.abs(lerobot_actions_own - openpi_actions_lerobot_preproc).max().item():.6f}"
|
||||
)
|
||||
|
||||
print("\n=== SUMMARY ===")
|
||||
print("Test 1 compares end-to-end pipelines (each model with its own preprocessing)")
|
||||
print("Test 2 isolates model differences (both models with LeRobot preprocessing)")
|
||||
print("Both tests completed successfully!")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -0,0 +1,273 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
"""Test script to load PI0OpenPI model from HuggingFace hub and run inference."""
|
||||
|
||||
import torch
|
||||
|
||||
from lerobot.policies.pi0_openpi import PI0OpenPIPolicy
|
||||
from lerobot.policies.pi05_openpi.modeling_pi05openpi import PI05OpenPIPolicy
|
||||
|
||||
|
||||
def create_dummy_stats(config):
|
||||
"""Create dummy dataset statistics for testing."""
|
||||
dummy_stats = {
|
||||
"observation.state": {
|
||||
"mean": torch.zeros(config.state_dim),
|
||||
"std": torch.ones(config.state_dim),
|
||||
},
|
||||
"action": {
|
||||
"mean": torch.zeros(config.action_dim),
|
||||
"std": torch.ones(config.action_dim),
|
||||
},
|
||||
}
|
||||
|
||||
# Add stats for image keys if they exist
|
||||
for key in config.image_keys:
|
||||
dummy_stats[key] = {
|
||||
"mean": torch.zeros(3, config.image_resolution[0], config.image_resolution[1]),
|
||||
"std": torch.ones(3, config.image_resolution[0], config.image_resolution[1]),
|
||||
}
|
||||
|
||||
return dummy_stats
|
||||
|
||||
|
||||
def test_hub_loading(model_id="pepijn223/pi0_base_fp32", model_name="PI0"):
|
||||
"""Test loading model from HuggingFace hub.
|
||||
|
||||
Args:
|
||||
model_id: HuggingFace model ID to load
|
||||
model_name: Display name for the model (e.g., "PI0", "PI0.5")
|
||||
"""
|
||||
print("=" * 60)
|
||||
print(f"{model_name} OpenPI HuggingFace Hub Loading Test")
|
||||
print("=" * 60)
|
||||
|
||||
print(f"\nLoading model from: {model_id}")
|
||||
print("-" * 60)
|
||||
|
||||
try:
|
||||
# Load the model from HuggingFace hub with strict mode
|
||||
if model_name == "PI0.5":
|
||||
policy = PI05OpenPIPolicy.from_pretrained(
|
||||
model_id,
|
||||
strict=True, # Ensure all weights are loaded correctly,
|
||||
)
|
||||
else:
|
||||
policy = PI0OpenPIPolicy.from_pretrained(
|
||||
model_id,
|
||||
strict=True, # Ensure all weights are loaded correctly,
|
||||
)
|
||||
|
||||
print("✓ Model loaded successfully from HuggingFace hub")
|
||||
|
||||
# Inject dummy stats since they aren't loaded from the hub
|
||||
print("Creating dummy dataset stats for testing...")
|
||||
device = next(policy.parameters()).device
|
||||
dummy_stats = create_dummy_stats(policy.config)
|
||||
|
||||
# Move dummy stats to device
|
||||
for key, stats in dummy_stats.items():
|
||||
dummy_stats[key] = {
|
||||
"mean": stats["mean"].to(device),
|
||||
"std": stats["std"].to(device),
|
||||
}
|
||||
|
||||
# Initialize normalization layers with dummy stats if they have NaN/inf values
|
||||
print("✓ Dummy stats created and moved to device")
|
||||
|
||||
# Get model info
|
||||
print("\nModel configuration:")
|
||||
print(f" - Model type: {model_name}")
|
||||
print(f" - PaliGemma variant: {policy.config.paligemma_variant}")
|
||||
print(f" - Action expert variant: {policy.config.action_expert_variant}")
|
||||
print(f" - Action dimension: {policy.config.action_dim}")
|
||||
print(f" - State dimension: {policy.config.state_dim}")
|
||||
print(f" - Chunk_size: {policy.config.chunk_size}")
|
||||
print(f" - Tokenizer max length: {policy.config.tokenizer_max_length}")
|
||||
if model_name == "PI0.5":
|
||||
print(f" - discrete_state_input: {policy.config.discrete_state_input}")
|
||||
print(f" - Device: {device}")
|
||||
print(f" - Dtype: {next(policy.parameters()).dtype}")
|
||||
|
||||
# Check model-specific features
|
||||
if model_name == "PI0.5":
|
||||
print("\nPI0.5 specific features:")
|
||||
print(f" - Has time_mlp layers: {hasattr(policy.model, 'time_mlp_in')}")
|
||||
print(f" - Has state_proj: {hasattr(policy.model, 'state_proj')} (should be False)")
|
||||
print(f" - Uses AdaRMS: {policy.model.paligemma_with_expert.gemma_expert.config.use_adarms}")
|
||||
|
||||
# Verify PI0.5 architecture
|
||||
assert hasattr(policy.model, "time_mlp_in"), "PI0.5 should have time_mlp_in"
|
||||
assert hasattr(policy.model, "time_mlp_out"), "PI0.5 should have time_mlp_out"
|
||||
assert not hasattr(policy.model, "state_proj"), "PI0.5 should not have state_proj"
|
||||
assert not hasattr(policy.model, "action_time_mlp_in"), "PI0.5 should not have action_time_mlp_in"
|
||||
print(" ✓ PI0.5 architecture verified")
|
||||
else:
|
||||
print("\nPI0 specific features:")
|
||||
print(f" - Has action_time_mlp layers: {hasattr(policy.model, 'action_time_mlp_in')}")
|
||||
print(f" - Has state_proj: {hasattr(policy.model, 'state_proj')} (should be True)")
|
||||
print(
|
||||
f" - Uses AdaRMS: {policy.model.paligemma_with_expert.gemma_expert.config.use_adarms} (should be False)"
|
||||
)
|
||||
|
||||
# Verify PI0 architecture
|
||||
assert hasattr(policy.model, "action_time_mlp_in"), "PI0 should have action_time_mlp_in"
|
||||
assert hasattr(policy.model, "action_time_mlp_out"), "PI0 should have action_time_mlp_out"
|
||||
assert hasattr(policy.model, "state_proj"), "PI0 should have state_proj"
|
||||
assert not hasattr(policy.model, "time_mlp_in"), "PI0 should not have time_mlp_in"
|
||||
print(" ✓ PI0 architecture verified")
|
||||
|
||||
except Exception as e:
|
||||
print(f"✗ Failed to load model: {e}")
|
||||
return False
|
||||
|
||||
print("\n" + "-" * 60)
|
||||
print("Testing forward pass with loaded model...")
|
||||
|
||||
# Create dummy batch for testing
|
||||
batch_size = 1
|
||||
|
||||
# Check if normalization layers have invalid stats and replace with dummy stats if needed
|
||||
try:
|
||||
# Check if the normalize_inputs has valid stats
|
||||
if hasattr(policy.normalize_inputs, "stats"):
|
||||
obs_state_mean = policy.normalize_inputs.stats.get("observation.state", {}).get("mean")
|
||||
if obs_state_mean is not None and (
|
||||
torch.isinf(obs_state_mean).any() or torch.isnan(obs_state_mean).any()
|
||||
):
|
||||
print("⚠️ Found invalid normalization stats, replacing with dummy stats...")
|
||||
|
||||
# Replace with dummy stats
|
||||
from lerobot.policies.normalize import Normalize, Unnormalize
|
||||
|
||||
policy.normalize_inputs = Normalize(
|
||||
policy.config.input_features, policy.config.normalization_mapping, dummy_stats
|
||||
)
|
||||
policy.normalize_targets = Normalize(
|
||||
policy.config.output_features, policy.config.normalization_mapping, dummy_stats
|
||||
)
|
||||
policy.unnormalize_outputs = Unnormalize(
|
||||
policy.config.output_features, policy.config.normalization_mapping, dummy_stats
|
||||
)
|
||||
print("✓ Normalization layers updated with dummy stats")
|
||||
except Exception as e:
|
||||
print(f"⚠️ Error checking normalization stats, creating new ones: {e}")
|
||||
# Fallback: create new normalization layers
|
||||
from lerobot.policies.normalize import Normalize, Unnormalize
|
||||
|
||||
policy.normalize_inputs = Normalize(
|
||||
policy.config.input_features, policy.config.normalization_mapping, dummy_stats
|
||||
)
|
||||
policy.normalize_targets = Normalize(
|
||||
policy.config.output_features, policy.config.normalization_mapping, dummy_stats
|
||||
)
|
||||
policy.unnormalize_outputs = Unnormalize(
|
||||
policy.config.output_features, policy.config.normalization_mapping, dummy_stats
|
||||
)
|
||||
|
||||
# Create test batch
|
||||
batch = {
|
||||
"observation.state": torch.randn(
|
||||
batch_size, policy.config.state_dim, dtype=torch.float32, device=device
|
||||
),
|
||||
"action": torch.randn(
|
||||
batch_size,
|
||||
policy.config.chunk_size,
|
||||
policy.config.action_dim,
|
||||
dtype=torch.float32,
|
||||
device=device,
|
||||
),
|
||||
"task": ["Pick up the object"] * batch_size,
|
||||
}
|
||||
|
||||
# Add images if they're in the config
|
||||
for key in policy.config.image_keys:
|
||||
batch[key] = torch.rand(batch_size, 3, 224, 224, dtype=torch.float32, device=device)
|
||||
|
||||
try:
|
||||
# Test forward pass
|
||||
policy.train() # Set to training mode for forward pass with loss
|
||||
loss, loss_dict = policy.forward(batch)
|
||||
print("✓ Forward pass successful")
|
||||
print(f" - Loss: {loss_dict['loss']:.4f}")
|
||||
print(f" - Loss shape: {loss.shape if hasattr(loss, 'shape') else 'scalar'}")
|
||||
|
||||
except Exception as e:
|
||||
print(f"✗ Forward pass failed: {e}")
|
||||
import traceback
|
||||
|
||||
traceback.print_exc()
|
||||
return False
|
||||
|
||||
print("\n" + "-" * 60)
|
||||
print("Testing inference with loaded model...")
|
||||
|
||||
try:
|
||||
# Test action prediction
|
||||
policy.eval() # Set to evaluation mode for inference
|
||||
with torch.no_grad():
|
||||
action = policy.select_action(batch)
|
||||
print("✓ Action prediction successful")
|
||||
print(f" - Action shape: {action.shape}")
|
||||
print(f" - Action range: [{action.min().item():.3f}, {action.max().item():.3f}]")
|
||||
|
||||
except Exception as e:
|
||||
print(f"✗ Action prediction failed: {e}")
|
||||
import traceback
|
||||
|
||||
traceback.print_exc()
|
||||
return False
|
||||
|
||||
print("\n" + "=" * 60)
|
||||
print(f"✓ All tests passed for {model_name}!")
|
||||
print("=" * 60)
|
||||
return True
|
||||
|
||||
|
||||
def main():
|
||||
"""Run tests for both PI0 and PI0.5 models."""
|
||||
print("\n")
|
||||
print("╔" + "═" * 58 + "╗")
|
||||
print("║" + " PI0 & PI0.5 HuggingFace Hub Loading Test Suite ".center(58) + "║")
|
||||
print("╚" + "═" * 58 + "╝")
|
||||
print()
|
||||
|
||||
results = []
|
||||
|
||||
# Test PI0 model
|
||||
print("\n[Test 1/2] Testing PI0 model...")
|
||||
print("─" * 60)
|
||||
pi0_success = test_hub_loading(model_id="pepijn223/pi0_base_fp32", model_name="PI0")
|
||||
results.append(("PI0", pi0_success))
|
||||
|
||||
# Test PI0.5 model
|
||||
print("\n\n[Test 2/2] Testing PI0.5 model...")
|
||||
print("─" * 60)
|
||||
pi05_success = test_hub_loading(model_id="pepijn223/pi05_base_fp32", model_name="PI0.5")
|
||||
results.append(("PI0.5", pi05_success))
|
||||
|
||||
# Summary
|
||||
print("\n\n")
|
||||
print("╔" + "═" * 58 + "╗")
|
||||
print("║" + " TEST SUMMARY ".center(58) + "║")
|
||||
print("╚" + "═" * 58 + "╝")
|
||||
|
||||
all_passed = True
|
||||
for model_name, success in results:
|
||||
status = "✅ PASSED" if success else "❌ FAILED"
|
||||
print(f" {model_name:10} : {status}")
|
||||
if not success:
|
||||
all_passed = False
|
||||
|
||||
print()
|
||||
if all_passed:
|
||||
print("🎉 All models loaded and tested successfully!")
|
||||
else:
|
||||
print("⚠️ Some tests failed. Check the output above for details.")
|
||||
|
||||
return all_passed
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
success = main()
|
||||
exit(0 if success else 1)
|
||||
Reference in New Issue
Block a user